













絵文字を扱う上で知っておくと良いかもしれないことをまとめてみました。
Ruiさんの記事を見て、「EmojiはSurrogate Pair以外にも、色々とおもしろい技術があるんですよ〜」思って書いてみました。
なお、書いた人はAndroidの人間なので、特に表記していない場合は主にAndroid上での動作のことを書いてます。
またQiita初めてなので読みにくい部分等がありましてもご容赦ください。
サロゲートペア(Surrogate Piars)
このエントリーを書くきっかけにもなったサロゲートペア。なぜこれが導入されたかの経緯は、Ruiさんのブログエントリーに譲るとして、技術的な解説をします。
サロゲートペアは、U+0000..U+FFFFに収まりきらなかった範囲のUnicodeコードポイント(U+10000..U+10FFFF)を、なんとか16bitでエンコードしようとして導入されました。つまり1,048,576個分のスペースを、なんとかしてひねり出さないといけません。ですがUTF-16の1文字あたりのサイズは16bit、つまり65,536個なので逆立ちしても足りません。そこで考えついたのが、「2つのUTF-16文字を組み合わせて、足りない部分を表現しよう!」という荒業です。
具体的には、Unicodeは予め2つの1024個の領域を確保し、その組み合わせの1,024 * 1,024 = 1,048,576通りで足りない部分を表現しようと決めました。その2つの領域をハイサロゲート(High Surrogate)とローサロゲート(Low Surrogate)、そのペアのことをサロゲートペア(Surrogate Pair)と呼びます。最近ではHighとLowだと分かりにくいので、リーディングサロゲート(Leading Surrogate)とトレイリングサロゲート(Trailing Surrogate)と呼ぶことのほうが多い気がします。
サロゲートペアの1個めと2個めは、それぞれ別の領域が割当らているので、順番がひっくり返ることはありません。つまり文字列を頭から読んでいる途中で、いきなりローサロゲートに出くわすことはなくて、かならずハイサロゲートとその直後にローサロゲートという順番でやってきます。片方が存在しないサロゲート(ハイサロゲートのみ、またはローサロゲートのみ)や順番が入れ替わったサロゲートペア(ローサロゲートの後にハイサロゲート)はUnicode的に正しくない文字列となります。
実際に変換する場合は、APIを呼んでください。Javaならこんな感じ。
Character.toCodePoint(highSurrogate, lowSurrogate); // サロゲートペアからコードポイントへ
char[] chs = {Character.highSurrogate(cp), Character.lowSurroage(cp)} // コードポイントからサロゲートペアへ
これを無視すると・・・
- 文字数カウンターで1文字多く表示されてしまう。
- 部分文字列を取得する際に、運悪くサロゲートペアの間で切っちゃうと、中途半端な文字が残ってしまう。
- 他のエンコード(UTF-8とか)に変換するときにに、サロゲートペアのままエンコードしちゃうと壊れた文字が出力されてしまう。
なんかが起こってしまいますね。
カラー絵文字フォントの互換性
最近のEmojiブームは、iOSがカラー絵文字を表示し始めたあたりからでしょうか。
文字と言うからには、それはフォントファイルを使って描かれているのですが、ではなぜ突然フォントは白黒からカラーの文字を描けるようになったのでしょうか?
結論から言うと、既存のテクノロジーの上に新しい仕組みを作ったからなのです。ただ・・・この業界でありがちなのですが、各社各様の仕様がありまして、単にフォントファイルを持ってくれば描いてくれる、といった代物ではありません。
例えば、AndroidではNoto Color Emojiというカラー絵文字用のフォントが採用されています。このNoto Color Emojiが、どうやってカラー絵文字を実装しているかというと・・・単にPNGファイルが埋め込まれています。実際grepしたらPNGって文字が見えます。
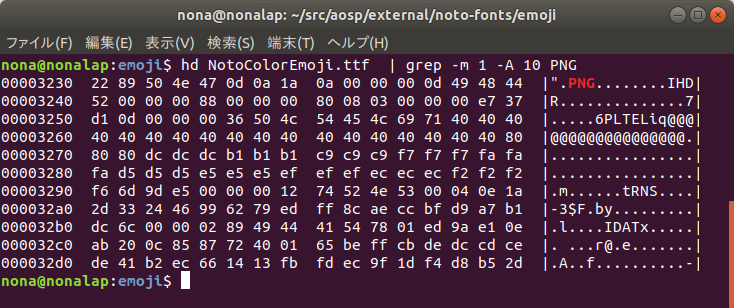
最近では使われることは少なくなりましたが、昔はビットマップフォントと言われる、白黒の絵が実際にフォントファイルの中に入っている形式のフォントファイルがあったのです。Noto Color Emojiはこれを拡張してPNGファイルを埋め込めるようにしたものです。実際の規格はこちら。
じゃあこれを別のプラットフォームに持っていったら、動くのかというと・・・動いたり動かなかったりします。例えばWindowsではWindows 10 Anniversary Updateから動作するようですが、それ以前のWindowsでは動かなさそうです。
Androidは、KitKat以降のデバイスであれば、Noto Color Emojiを読み込ませて表示させることができます。
これはAndroidがFreeTypeと呼ばれるオープンソースのライブラリを採用しており、これのバージョン2.5で絵文字フォントを表示させることができるようになったからです。
(注:一部制限があります。実際に古いAndroidで最新の絵文字を使用する際はEmojiCompatを利用してください。一部の絵文字が表示されません。)
Linux上で動作するChromeも同様の理由でカラー絵文字を表示できます。
ここまで読んでくださった方の何人かは「なんでPNGなんだよ、拡大したら汚くなるじゃないか。」という疑問をもったかもしれません。
おっしゃるとおりです。元データが画像なので、拡大していくとどうしても境界がぼやけてきてしまいます。多分これが一番実装が簡単だったからじゃないでしょうか。
どうしてもベクターデータが良いという方は、SVGを埋め込むとか、カラーパレットを使う(COLR/CPAL)みたいな規格もあります。
ですが、これらは今の所FreeTypeでは動かないです。
カラー?それとも白黒?
最近の絵文字はカラフルです。例えば砂時計(⏳:U+231B)は今記事を書いているLinux Chrome上では白黒ですが、今手元のAndroidで表示させたところカラーになりました。


一方で白黒のままの絵文字もあります。では絵文字をカラーで表示するか、白黒で表示するかの決定は誰がやってるのでしょうか。
それも実はUnicodeがやっています。ここにカラーか白黒かのどちらで表示させるべきかのリストを公開されています。
http://www.unicode.org/Public/emoji/6.0/emoji-data.txt
一部を抜粋します。
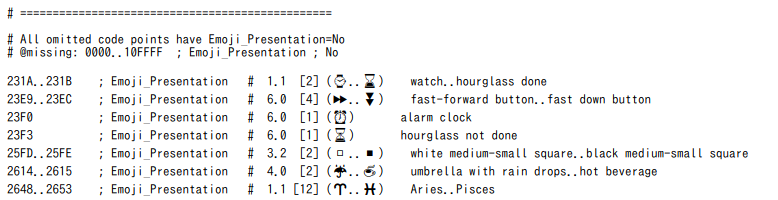
この表のたとえば1列目は「コードポイントU+231AからU+231Bまで、Emoji_Presentationの属性である。」という意味になります。この"Emoji_Presentation"という属性のついたコードポイントは、カラーで表示しなくてはなりません。
「Unicodeなど知らん!俺は全部カラーで表示させたい!」とか「白黒の文字こそ至高だ!カラーなど許さん!」という方がいらっしゃった場合もUnicodeはちゃんと方法を用意しています。
Unicode:「絵文字を全部カラーにしたいと申すか。ではお主の使用している言語の設定を絵文字に切り替えるのだ!」
「何言ってんの?」ってなったあなた、大丈夫です。私も最初「何言ってんの?」って思いました。実は絵文字用の言語(厳密には文字種ですが)ってあるんです!
http://unicode.org/iso15924/iso15924-codes.html
ここにあるZsym、もしくはZsyeをLanguage Tagに指定すると絵文字の表示方法が変わります。具体的にはこんな感じ。
TextView emojiDefault = findViewById(R.id.emojiDefault);
emojiDefault.setTextLocale(Locale.forLanguageTag("ja-Zsye-JP"));
TextView textDefault = findViewById(R.id.textDefault);
textDefault.setTextLocale(Locale.forLanguageTag("ja-Zsym-JP"));
表示させてみるとこんな感じ。

砂時計(⏳:U+231B)はカラーがデフォルト、左上矢印(↖:U+2196)は白黒がデフォルトです。
「いやいや、まてまて、言語設定に絵文字を使ったら、本来の言語設定に使えないじゃないか」。
おっしゃるとおりです。そんなあなたにおすすめなのがこちら、Emoji locale extensionです。
TextView defaultPresentation = findViewById(R.id.defaultPresentation);
defaultPresentation.setTextLocale(Locale.forLanguageTag("en-US-u-em-default"));
TextView emojiDefault = findViewById(R.id.emojiDefault);
emojiDefault.setTextLocale(Locale.forLanguageTag("en-US-u-em-emoji"));
TextView textDefault = findViewById(R.id.textDefault);
textDefault.setTextLocale(Locale.forLanguageTag("en-US-u-em-text"));
表示させてみると

っとなります。。。言語ってなんだっけ・・・
あ、当然ですが、デバイスにフォントがなかったら、いくら設定を変えても出てこないです。念の為・・・
注:この機能はAndroidだとOreo(API26)から使えます。また、この機能は優先度がかなり低めに設定されているため、一部の絵文字はカラーを指定しても白黒で出てくることがあります。必ずカラーで表示させたい場合は後述の異体字セレクタを使用するのをオススメします。
絵文字用の異体字セレクタ(Emoji Variation Selector)とは
一個前のセクションで絵文字のカラーか白黒かについて説明したんですが、
- 設定が「全部カラー」か「全部白黒」は極端すぎて使い勝手が悪い。個別にカラーか白黒か選べるようにしてくれ
- カラーの絵文字と白黒の絵文字を同時に表示させたいんだが、どうすればいいんだ。
って思った方もいたでしょう。
そんなこともあろうかと、Unicodeはちゃんと文字単位で表示を変える方法を用意しています!それも昔からある方法で!
それは日本人の方には馴染みのあるものかもしれません。「異体字セレクタ(Variation Selector)」です。
。。。たぶん普通の人はピンとこないですよね。
あれです、「わたなべ」さんの漢字でいろいろある「邉」の字を表現するための、あれです。
Unicodeは文字を定義しているので、どの「邉」も文字としては同じなので、同じコードポイントのU+9089が割り当てられました。
でも「俺の"なべ"の字は、それじゃないんだけど・・・」っていう問題を解決するために、特殊な文字を後ろにつけて、形を変えられるようになってるんです。
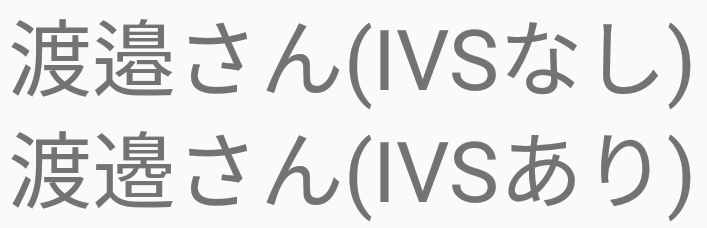
この文字列のユニコード列は順に
U+6E21 U+9089 U+3055 U+3093
U+6E21 U+9089 U+E0104 U+3055 U+3093
上の例だと、U+E0104という異体字セレクタが、邉(U+9089)の直後にあります。IVSは(Ideographic Variation Selectorの略です)
ちなみにこの異体字セレクタは、U+FFFFを超えているので、Javaなんかで使用する際は上で説明したようにサロゲートペアにしないといけません。
TextView tv = findViewById(R.id.textView);
tv.setText("\u6E21\u9089\uDB40\uDD04\u3055\u3093"); // U+E0104 = \uDB40\uDD04
これと同じことが、絵文字でできるようになっています。U+FE0EとU+FE0Fの2つは、絵文字用の異体字セレクタとして登録されていて、U+FE0Eが後ろについている絵文字は白黒に、U+FE0Fが後ろについている絵文字はカラーになります。これは先程の言語設定よりも優先されます。(当然ですがフォントが存在しなければ白黒になってしまいます)

上記の文字列のユニコード列は順に
U+231B U+2196
U+231B U+FE0F U+2196 U+FE0F
U+231B U+FE0E U+2196 U+FE0E
となっています。
合成絵文字
さて、ここまでは絵文字1個あたり1コードポイントでした。まぁ後ろに異体字セレクタがついたとしても2コードポイントでした。
ここからは割と「どうしてこうなった・・・」感のある合成絵文字の紹介をしていきます。これらは複数の絵文字を組み合わせることで別の絵文字になる奇抜な奴らです。
KeyCap
数字(1:U+0031 から 9:U+0039, #:U+0023)の後ろにU+20E3をつけるとボタンになります。

Emoji Modifier
人っぽい絵文字(例えば走ってる人:U+1F3C3)の後ろに肌色選択セレクタ(Skin Tone Selector)をつけると、肌の色が変わります。

旗
U+1F1E6..U+1F1FFをアルファベットに見立て、2文字国コードを作ることで国旗になります。例えば、J + P = JPみたいな。

ZWJシーケンス
複数の絵文字をZWJ(Zero Width Joiner)という見えない文字で繋いで別の絵文字にしてしまう。例えば、「男の人+ZWJ+パレット=男性の画家」 みたいなかんじ。

などなど・・・
このように、もはや1個の絵文字は、1コードポイントではないのです。もし部分文字列を取り出すときに、このような合成文字の途中で切ってしまうと、変な文字が残ったりするかもしれません。でもこれはSurrogate Pairみたいに、どこ切ってよいかどうかはすぐにはわかりません。そこで登場するのが次のグラフィミークラスターです。
ちなみにですが、ZWJシーケンスは「どんな組み合わせでもいいの?」っていう疑問が湧くと思います。
答えは「ZWJの前後の文字がEmoji属性であれば、どんな組み合わせでも良い」です。当然Unicodeとして正しいシーケンスである、というだけで、実際に表示されるかどうかはフォント次第です。MicrosoftのNinjaCatとかが有名ですね。
グラフィミークラスター(Grapheme Cluster)とは
前のセクションで、もはや絵文字は1コードポイントではないと説明しました。つまり、何も考えずに部分文字列を取り出すコードを書くと、絵文字のど真ん中でブチッってやってしまう可能性があるのです。これに関連するお気に入りの面白いバグがあるので紹介します。

これはEditTextに、前のセクションで説明した国旗の絵文字のうち、イスラエルの国旗(IL)を大量に並べて、デリートキーを連打しているだけです。別にコピペを連打しているわけではないですし、Javaコードは一切書いていないです。なのになぜか、突然国旗がリヒテンシュタイン(LI)に変わっている、そしてまたもとに戻っている。
Android M以前で発生するバグなのですが、感が鋭い方は気づいたかもしれません。そう、国旗の絵文字にはサロゲートペアと違い、ペアのうち最初に来る文字と、あとに来る文字の区別がないんです。そんな状態で最初の1コードポイントを削除してしまうと、ILの繰り返しだったものが、突然LIの繰り返し、つまりリヒテンシュタインの国旗の繰り返しになってしまったのです。
わかりやすく図式すると
コードポイント列: ILILILILILILILILILILIL
Androidはこう考える:[IL][IL][IL][IL][IL]...
先頭の1コードポイント削除
コードポイント列: LILILILILILILILILILIL
Androidはこう考える:[LI][LI][LI][LI][LI]...
これは旗の絵文字の規格の不完全さもあるとは思いますが、問題の根本はデリートキーが、間違った文字数を消しているのが原因です。じゃあ正しい文字数っていくつなの?っという疑問に対するUnicodeの答えがグラフィミークラスター(Grapheme Cluster)です。
Unicodeは、グラフィミークラスターのことをこう言っています。
It is important to recognize that what the user thinks of as a “character”—a basic unit of a writing system for a language—may not be just a single Unicode code point. Instead, that basic unit may be made up of multiple Unicode code points. To avoid ambiguity with the computer use of the term character, this is called a user-perceived character. For example, “G” + acute-accent is a user-perceived character: users think of it as a single character, yet is actually represented by two Unicode code points. These user-perceived characters are approximated by what is called a grapheme cluster, which can be determined programmatically. UAX #29
ザックリいうと、ユーザーが考える「1文字」っていうのは複数のコードポイントからできてることもあるので、プログラム上の「1文字」とは別に「ユーザーの考える1文字」っていうのを定義するね。と言っています。
日本語にも実は例があります。ひらがなの「が」です。Unicodeではこの「が」は2通りの表記の方法があるんです。1コードポイントで表記する「が:U+304C」と、「か:U+304B」に濁点「゙:U+3099」がついた「が:U+304B U+3099」の2つです。Macが主に後者を使いますね。でも多分普段文字を書いていて、「か」と濁点の間にカーソルが置けたり、「が」をデリートキーで消そうとしたら濁点だけが残ったりすると、なんとなく「コレジャナイ感」がありますよね。これはユーザーは「が」を1文字としてみており、「か」と濁点の2文字だとは考えていないからです。
同じことが絵文字にも言えます。「男性+ZWJ+パレット」の組み合わせが一個の「男性の画家」の絵文字である以上、これを男性とパレットの2文字(もしくはZWJを入れて3文字)として考えるのはナンセンスです。なのでデリートキーやカーソルはこれら3つのコードポイントが一つの文字であるかのように扱います。
最初の旗が切り替わるバグのケースでは、グラフィミークラスターは[IL][IL][IL][IL]のように分解されますので、デリートキーで消すのは2コードポイントとなります。なので旗はリヒテンシュタインにはならず、イスラエルの旗が1個だけ消えるような動作をします。
実際にグラフィミークラスターがどう定義され、実装されているかは触れませんが、これは結局のところデータベースから文字情報を引っ張ってこないといけないので、素直にICUなどのライブラリを使うのが良いかと思います。
AndroidだとICU4Jが使えるので、このへんが良いかと思います。
バックスペースの動作
前のセクションで、デリートキーが何文字消すかについてのUnicodeの答えを説明しました。ではバックスペースはどうなのでしょう。
実は私の知る限りUnicodeは「よしなにやってね」以上のことを言ってない気がします。
「バックスペースは、デリートキーと同じく、直前のグラフィミークラスターの切れ目まででいいんじゃね?」って思われるかもしれません。
大体の場合それでOKです。ですが、バックスペースの場合は「正しくないUnicodeシーケンスのときに、正しい部分まで消してしまう」リスクがあります。
例えば、Key Capの絵文字の例に考えてみましょう。
1 + KEYCAP(U+20E3)
これは正しいUnicodeシーケンスです。もしKEYCAPの後ろにカーソルが合って、バックスペースが押されたら、全部消して問題ないでしょう。
では
1 + KEYCAP + KEYCAP
の場合はどうでしょう。これはUnicode的には正しくないです。そしてデバイス上では

このように表示されています。もしカーソルが最後のKEYCAPの後ろに合った場合、バックスペースが押されると、どんな結果を期待するでしょう。
1 + KEYCAP
おそらく、後ろの四角だけ消えて、最初の絵文字は残っていてほしいと思うでしょう。ですがグラフィミークラスターのルールを適用すると、この2つに見える文字は一つのクラスターに属するのです。つまりバックスペースですべて消えてしまいます。
この状況で最後のKEYCAPだけを消すためには、グラフィミークラスターに頼らない新たな方法が必要です。
そして、おそらくそれはまだ統一的な手法は提案されていないと思います。
一番安全なのは、自力でバックスペースを実装しようとせず、OSに任せるのが良いとおもいます。
どうしても自力で実装したいというのであれば、Androidの実装はこの辺にあるみたいです。
さいごに
ここで紹介した技術は、実は絵文字専用に開発されたものはカラー絵文字フォントくらいで、それ意外の技術は昔からあるものなのです。
例えばZWJは本来はアラビア語の字形選択用、グラフィミークラスターは、これがないとハングルやタイ語で大変なことになってしまいます。
サロゲートペアに限らず、絵文字を契機に、開発者のみなさんが世界中の多様な言語を表示する技術に興味を持ってくだされば幸いです。




