AnalyticBridge
A Data Science Central Community

12 Statistical and Machine Learning Methods that Every Data Scientist Should Know
Below is my personal list of statistical and machine learning methods that every data scientist should know in 2016.
- Statistical Hypothesis Testing (t-test, chi-squared test & ANOVA)
- Multiple Regression (Linear Models)
- General Linear Models (GLM: Logistic Regression, Poisson Regression)
- Random Forest
- Xgboost (eXtreme Gradient Boosted Trees)
- Deep Learning
- Bayesian Modeling with MCMC
- word2vec
- K-means Clustering
- Graph Theory & Network Analysis
- (A1) Latent Dirichlet Allocation & Topic Modeling
- (A2) Factorization (SVD, NMF)
From my experience in the data science industry for 4 years, I think that currently these 12 methods are the most popular, useful and suitable for various problems requiring data science.
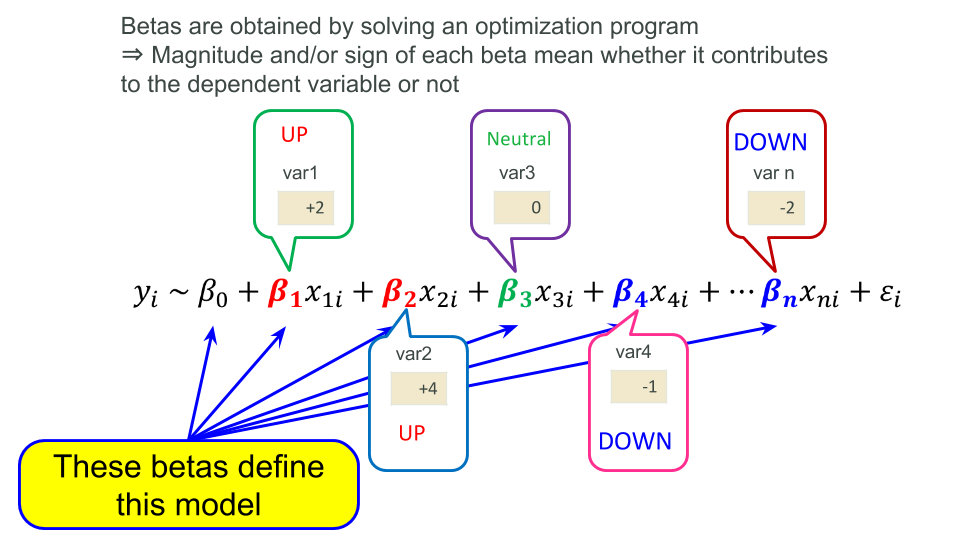
As far as I've known, there have been not a few lists of "representative methods in data science" ever. However, I feel some of them are already out-of-date because they appear to neglect the latest advance of data science in the industry. Thus I made this list as the one by business person, who knows practical matters and solutions with data science, including statistics and machine learning in the industry.
In addition to the list itself, I showed R or Python scripts of an experiment on sample datasets for each method, in order to enable readers to try it easily.
The original post is here, including R or Python scripts and experiments on sample datasets.
Comment
-
 Comment by Priya on March 8, 2017 at 4:23am
Comment by Priya on March 8, 2017 at 4:23am -
Please suggest a link for budding data scientists
Follow Us
On Data Science Central
- Deep Learning Cheat Sheet for Beginners
- Weekly Digest, October 5
- The Role of AI in Assisting Customer Experience
- Introduction to ggplot2 — the grammar
- 27 Great Articles About Machine Learning Algorithms
- For AI to Change Business, It Needs to Be Fueled with Quality Data
- Big Data for FinTech & InsureTech
- 5 Steps to Building a Big Data Business Strategy
- Best practices of orchestrating Python and R code in ML projects
- Poker and AI: The Rise of Machines Against Humans (Infographics)
- The Success Story of The Biggest Online Payment System -PayPal
- Deep Diving the Data Lake – Automatically Determining What’s In There
- 17 Great Blogs Posted in the last 12 Months
- Deep Learning versus Machine Learning in One Picture
- Is Data the New Oil?

Top Content
On DataViz
- Kim versus Donald in one Picture
- Mortality and causes of death in 2015 and 2030 - Infographics
- What is the future of Data visualization and Dashboard solutions?
- What Happens in 60-Seconds Online? - Infographics
- Taxonomy of 3D DataViz
- 3D Data Visualisation Survey
- 7 Top Data Visualization Books for Inquisitive Minds
- Why Your Brain Needs Data Visualization
- 10 Dataviz Tools To Enhance Data Science
- The Top 5 Benefits of Using Data Visualization
On Hadoop
- Google Spanner : The Future Of NoSQL
- 8 Hadoop articles that you should read
- What is Hadoop - An Easy Explanation For Absolutely Anyone
- Top 10 Commercial Hadoop Platforms
- Batch vs. Real Time Data Processing
- Is Big Data Harmful or Good?
- Lambda Architecture for Big Data Systems
- Why is there a huge buzz today around Analytics though the field has been there for decades?
- Leveraging your GPS data using Geospatial analytics
- HDFS vs. HBase : All you need to know
© 2017 AnalyticBridge.com is a subsidiary and dedicated channel of Data Science Central LLC
Powered by![]()

You need to be a member of AnalyticBridge to add comments!
Join AnalyticBridge