



2017-08-17号では、プロキシサーバのログなどに含まれるマルウエアDatperの通信を検知するためのPythonスクリプトを紹介しました。今回は、それを活用し、ログ分析ツールでDatperの通信を調査するための環境設定方法を紹介します。利用するログ分析ツールに応じて使い分けられるよう、Splunk編とElastic Stack編を用意しました。
Splunk編
まず、SplunkでDatperの通信ログを抽出するため、次に述べる方法でカスタムサーチコマンドを作成します。この方法で作成したコマンドはSplunk 6.3以降で使用できることを確認しています。
Splunkのカスタムサーチコマンド作成と調査
カスタムサーチコマンドを次の手順で作成してください。より詳細な手順につきましては、Splunk Documentatio[1]を参考にしてください。
-
Splunklibの設置
次のWebページからSplunkSDK (SoftwareDevelopmentKit)for Pythonをダウンロードし、その中に含まれているsplunklibフォルダを$SPLUNK_HOME/etc/apps/search/binへコピーします。
Splunk SDK for Python
http://dev.splunk.com/goto/sdk-python
-
カスタムサーチコマンド用スクリプトの設置
カスタムサーチコマンド用スクリプトdatper_splunk.py を$SPLUNK_HOME/etc/apps/search/bin へ保存します。
なお、カスタムサーチコマンド用スクリプトはGitHub上で公開していますので、次のWebページからダウンロードして、ご利用ください。
JPCERTCC/aa-tools · GitHub
https://github.com/JPCERTCC/aa-tools/blob/master/datper_splunk.py
-
コンフィグの設定
$SPLUNK_HOME/etc/apps/search/localに2つのコンフィグファイルを作成し、それぞれ以下のように記述します。すでにファイルが存在する場合にも、同様の内容を追記します。
commands.conf
[datper] filename = datper_splunk.py streaming = true chunked = true local = true
authorize.conf
[capability::run_script_datper] [role_admin] run_script_datper = enabled
なお、上の例ではdatperという名称のカスタムサーチコマンドを作成する設定をしています。
-
Splunkの再起動
変更したコンフィグを反映させるために、Splunkを再起動します。再起動後、datperという新たなカスタムサーチコマンドを利用できるようになります。
-
実行
作成したカスタムサーチコマンドを実行します。カスタムサーチコマンド datperを実行すると、Splunkの各イベント(インデックスしたログ)に対して "is_datper" というフィールドが生成され、判定結果"yes" または "no"が付与されます。プロキシログから日時やDatperの判定結果、通信先IPアドレス、URLを表示するサーチ文を実行した結果の例を図 1に示します。サーチ文内のindexやtableはそれぞれの環境に合わせて変更してください。
index=proxy_log | datper | search is_datper=yes | table _time,is_datper,dst_ip,url
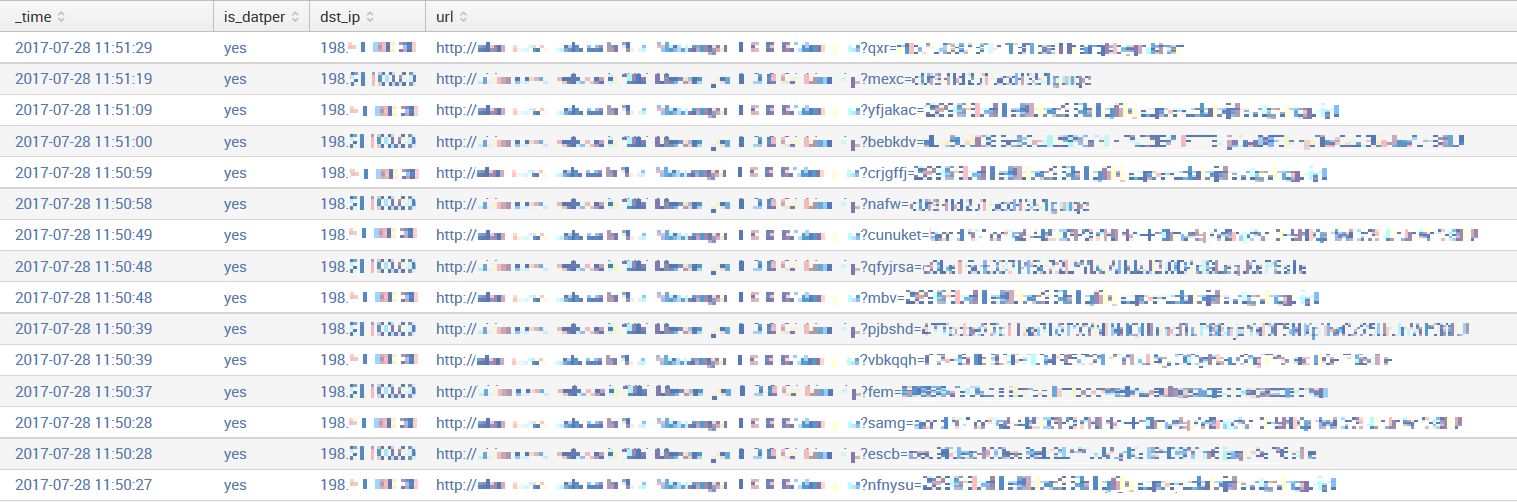
図 1:カスタムサーチコマンド datper 実行結果
クリックすると拡大されます
Elastic Stack編
次に、構築済みのElastic Stackの環境が既にあるものとして、Datperの通信を調査するための設定を追加する手順を紹介します。なお、プロキシログはSquidを対象としています。また、検証に使用したElastic Stackのバージョンは5.5.1です。
Elastic Stackの設定
-
スクリプトの設置
次のWebページからdatper_elk.pyをダウンロードし、任意のディレクトリに設置します。
JPCERTCC/aa-tools · GitHub
https://github.com/JPCERTCC/aa-tools/blob/master/datper_elk.py
以降では、スクリプトを/opt/binに設置したものとします。
-
Logstashの設定
Logstashでプロキシログを読み込み、スクリプトでDatperの通信かどうか判定した結果のフィールドを追加するよう、コンフィグファイルを作成します。
すでにプロキシログを読み込む設定が作成済みの場合には、2.1の設定を飛ばして2.2に進んでください。
2.1. inputの設定
input { file { type => "squid" start_position => "beginning" path => ["/var/log/squid3/access.log"] } }Logstashは、デフォルトではログに新しく追加された行を処理するようになっており、ログファイル全体を取り込む場合は、「start_position => "begining"」の設定が必要となります。
"path"には、取り込むログファイルを記述します。
2.2. filterの設定
filter { if [type] == "squid" { grok { match => [ "message", "%{NUMBER:timestamp}\s+%{NUMBER:response_time} %{IP:src_ip} %{WORD:squid_request_status}/%{NUMBER:http_status_code} %{NUMBER:reply_size_include_header} %{WORD:http_method} %{WORD:http_protocol}://%{HOSTNAME:dst_host}%{NOTSPACE:request_url} %{NOTSPACE:user} %{WORD:squid}/(?:-|%{IP:dst_ip}) %{NOTSPACE:content_type}" ] add_tag => ["squid"] } date { match => ["timestamp", "UNIX"] } ruby { code => 'require "open3" message = event.get("message") cmd = "/opt/bin/datper_elk.py \'#{message}\'" stdin, stdout, stderr = Open3.popen3(cmd) event.set("datper", stdout.read) ' } } }
上記の設定では、grokフィルタでSquidのログから各フィールドを抽出し、dateフィルタでUNIX時間のタイムスタンプを日付のフォーマットに変換しています。上記の例はSquidのデフォルトログ形式の場合の設定であり、ログ形式がcombinedの場合は、以下のようにCOMBINEDAPACHELOGパターンなどを使用してフィールドを抽出し、dateフィルタのパターンを変更する必要があります。
grok { match => { "message" => "%{COMBINEDAPACHELOG} %{WORD:squid_request_status}:%{WORD:squid}" } } date { match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"] }
rubyフィルタではスクリプトを実行し、スクリプトが返す結果をdatperフィールドとして追加しています。rubyフィルタのcodeにある、cmdのスクリプトの場所は、「1. スクリプトの設置」で設置した場所を記述します。また、上記のrubyフィルタのcodeは、Logstash5.0以降のEvent APIに合わせた記述となっており、それ以前のバージョンでは以下のように記述する必要があります。
code => 'require "open3" message = event["message"] cmd = "/opt/bin/datper_elk.py \'#{message}\'" stdin, stdout, stderr, status = Open3.popen3(cmd) event["datper"] = stdout.read '
2.3. outputの設定
output { elasticsearch { hosts => "localhost:9200" index => "squid-access" } }
hostsにElasticsearchのホスト名、index名に任意の名前を設定します。
Logstashに2.1から2.3の設定を記載したコンフィグファイルを読み込ませて実行し、ログファイルが問題なく取り込まれると、Elasticsearchにインデックスが作成されます。
-
Kibanaでのインデックスパターンの作成とログ検索
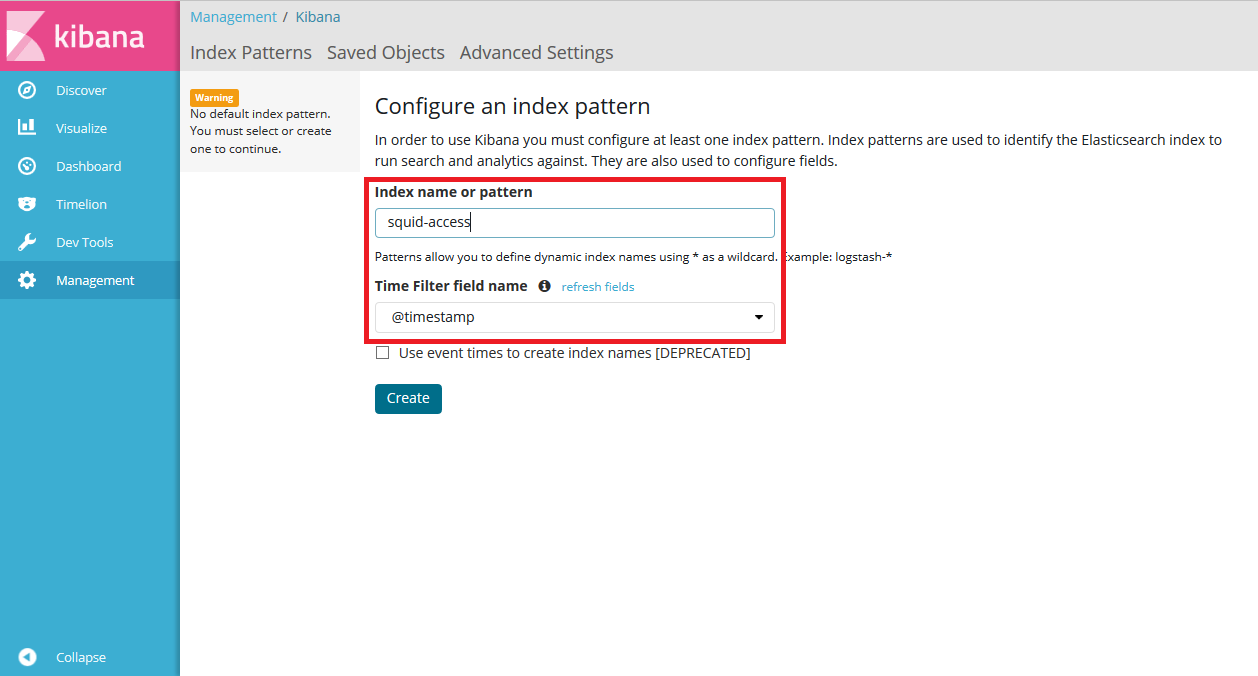
KibanaのWeb UIにアクセスし、インデックス名を入力してパターンを作成します。図 2では、「2. Logstashの設定」の説明で示したとおり、インデックス名をsquid-access、time filterフィールドをtimestampとしています。
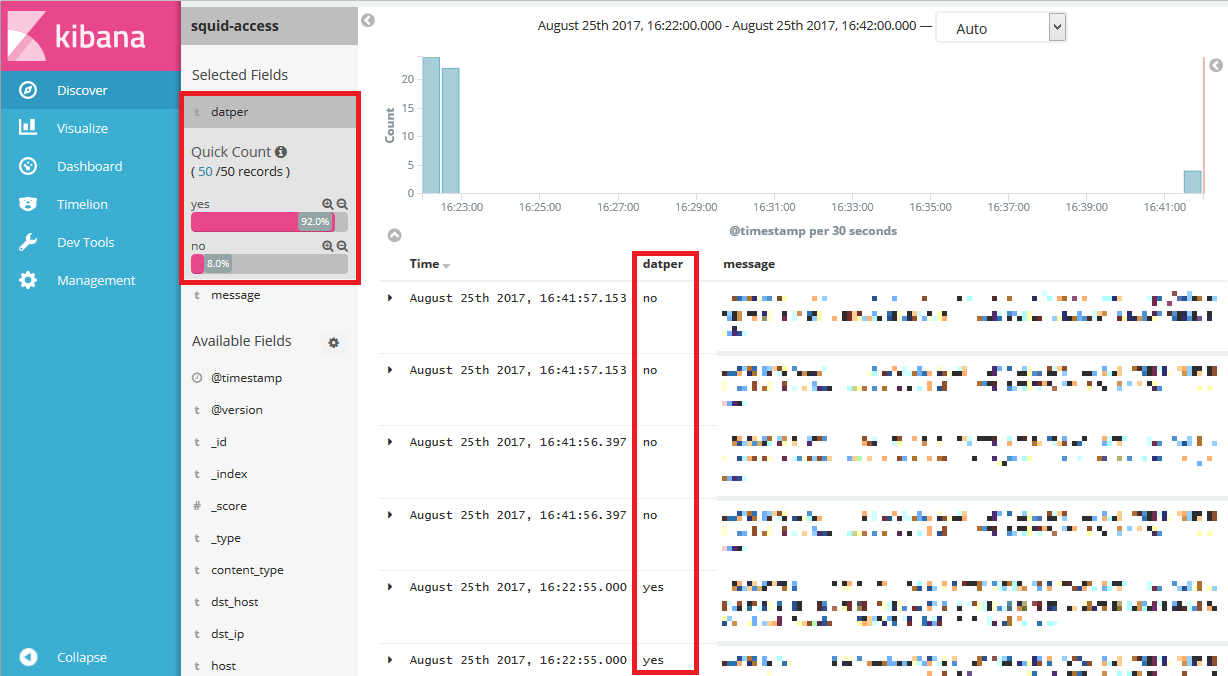
Discover画面を見ると、datperフィールドに、スクリプトによる判定結果が図 3のとおり入っています。
図 2:インデックスパターンの作成
クリックすると拡大されます

図 3:Discover画面
クリックすると拡大されます
なお、既存のインデックスにdatperのフィールドを追加したい場合には、ElasticsearchのURLとインデックス名を指定してdatper_elk.pyを実行することで、フィールドを追加することができます。ElasticsearchのURLがhttp://localhost:9200、プロキシログのインデックス名がsquid-accessの場合の実行例は次のとおりです。
/opt/bin/datper_elk.py http://localhost:9200 squid-access
おわりに
インシデントレスポンスにおいて、最も重要な点に早期発見が挙げられます。紹介した方法を応用することで、Datperの通信が発生したときにアラートを発報させるなど、早期発見の助けとなる、さまざまな仕組みを実装できます。また、過去のログを調査することにより、これまで明らかになっていなかった攻撃を発見できる可能性もあります。紹介した調査方法をとおして、不審な通信を発見した場合には、Datperによる攻撃の影響を最小限にとどめるために、より詳細な調査を実施するとともに、JPCERT/CC(https://form.jpcert.or.jp/ または、info@jpcert.or.jp)までご一報ください。
インシデントレスポンスグループ 谷 知亮 (Splunk編)
添田 洋司 (Elastic Stack編)
添田 洋司 (Elastic Stack編)
参考情報
| [1] | Splunk |
| How to create custom search commands using Splunk SDK for Python (Splunk Documentation) | |
| http://dev.splunk.com/view/python-sdk/SP-CAAAEU2 |
