













画像処理は難しい。
Instagramのキレイなフィルタ、GoogleのPhoto Sphere、そうしたサービスを見て画像は面白そうだ!と心躍らせて開いた画像処理の本。そこに山と羅列される数式を前に石化せざるを得なかった俺たちが、耳にささやかれる「難しいことはOpenCVがやってくれるわ。そうでしょ?」という声に身をゆだねる以外に何ができただろう。
本稿は石化せざるを得なかったあの頃を克服し、OpenCVを使いながらも基礎的な理論を理解したいと願う方へ、その道筋(アイテム的には金の針)を示すものになればと思います。
扱う範囲としては、あらゆる処理の基礎となる「画像の特徴点検出」を対象とします(実践 コンピュータビジョンの2章に相当)。なお、本記事自体、初心者である私が理解しながら書いているため、上級画像処理冒険者の方は誤りなどあれば指摘していただければ幸いです。
画像の特徴点とは
人間がジグソーパズルを組み立てられるのはなぜか?と考えると、私たちはパズルの各ピースの特徴を把握して、それと似た、また連続する特徴を見つけ出して繋ぎあわせているのだ、と考えることができます。同様に、複数の写真をつなげてパノラマ写真にすることができるのは、写真間で共通する特徴を見つけ出して繋ぎあわせているからです。

CS231M Mobile Computer Vision Class,Lecture5, Stitching + Blending, p4~
この「特徴点」をどんどんシンプルに考えていくと、最終的には以下3つに集約できます。

- edge: 差異が認識できる境界がある
- corner: edgeが集中する点
- flat: edgeでもcornerでもない、特徴が何も認識できない点
そして、上記のようなパノラマ写真の合成などを行うことを考えると、この「特徴点」を見つける際には以下のルールにのっとる必要があります。
- 再現性: ある特徴点は常に特徴点として認識される
- 識別性: ある特徴点は、その他の特徴点と明確に異なると識別できる
再現性については、例えば写真をとる角度を変えた場合に認識される特徴点がガラッと変わる、となると特徴点同士をつなぎ合わせるという処理そのものが破たんしてしまいます。

そのため、画像の角度や拡大率などで変化しない、頑健な特徴点を認識できる方がいいことになります。
識別性については、認識した特徴点が一意に識別できないとどれとどれを一致させていいかわからなくなってしまいます。

そのため、各特徴点が一意に識別できる表現方法が重要になります。
これはそのまま、特徴点の検出(Feature Detection)、特徴点の表現方法(Feature Description) 、それぞれに求められることと一致します。つまり、「画像の角度や拡大率などで変化しない、頑健な特徴点」を検出し(Feature Detection)、それをなるべく「一意に識別できる表現方法」で表現すること(Feature Description)が、画像における特徴点の認識の目標になります。
では、特徴点の検出、特徴点の表現方法を順番に見ていきます。
特徴点の検出(Feature Detection)
特徴点を検出する手順としては、概ね「edgeを検出」し、次いでedgeが集中する「cornerを検出」する、という流れになります。
edgeの検出
edgeとは、具体的には「輝度が大きく変化している点」になります。
簡単な例として、真っ黒なタイルに白い円が描かれた画像を考えます。下図の通り真横から引いた赤い線上の輝度を座標軸に沿ってプロットすると、真ん中の白い円の中で輝度が跳ね上がっているようなグラフが得られるはずです。

ここで、私たちが検出したいのはedge、つまりグラフ上で暗い->明るい、明るい->暗いと大きく変化しているポイントになります。ある点における変化の度合いを知るために、その点を中心とした前後の点の値の値から変化率を計算してみます。
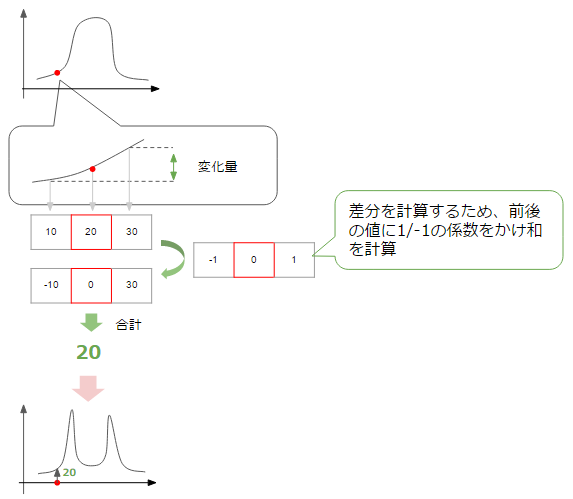
すると、上図のように変化が大きな点、つまりedgeに該当する箇所で変化率が上がっているグラフが得られます(変化量には+-がありますが、ここでは絶対値をプロットしていると思ってください)。今は図の水平方向で変化量を考えていますが、垂直方向の場合にも同様に考えられます。
最終的には、水平方向、垂直方向双方の変化量を合計し(通常は二乗和平方根)、その値があるしきい値(threshold)より大きい点を収集すればedgeの検出ができそうです。
これがedge検出の基本的な考え方で、一応これだけでもedgeの検出は可能ですが、より精度の高い検出を行うためのいくつかのテクニックがあるのでそれを見ていきます。
スムージング
変化量を計算する際に、周辺部分も考慮する方法です。ざっくり言ってしまえば、平均をとるようなイメージです。平均をとれば値の変化をならすことができ(スムージング)、この結果滑らかにつながるedgeを検出することができます。
以下は、水平方向の変化量について、隣接する点の変化量も加味して計算する様子を図で表したものです。計3つの変化量の和をとることで、スムージングが実現されています。
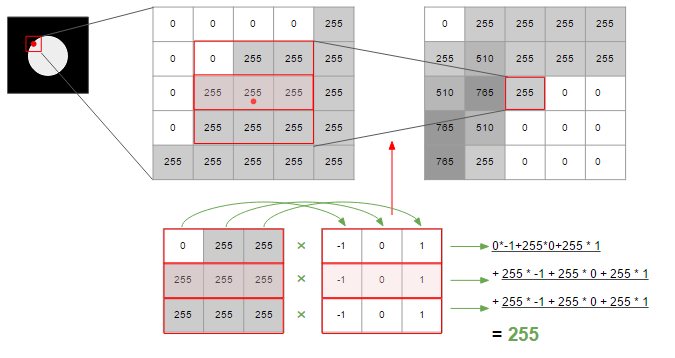
上図では変化量を計算するために3*3の、-1/0/1の値が入った行列を使って計算しています。こうした変化量を計算するための行列や処理をフィルタと呼びます。
このフィルタには様々な種類があり、上図で使っていたのはこのうちのPrewittフィルタになります。SobelフィルタはPrewittより中心に隣接するものを重視したものになり、Gaussianは正規分布の関数を利用し、中心を頂点とし、端に向かってなだらかに係数をかけることができます。edgeの検出でよく利用されるCanny法は、このGaussianフィルタを使った方法になります。

なお、画像の端の部分については、隣接する点がないため補間を行う必要があります。この補間の方法には以下のような手法があります。
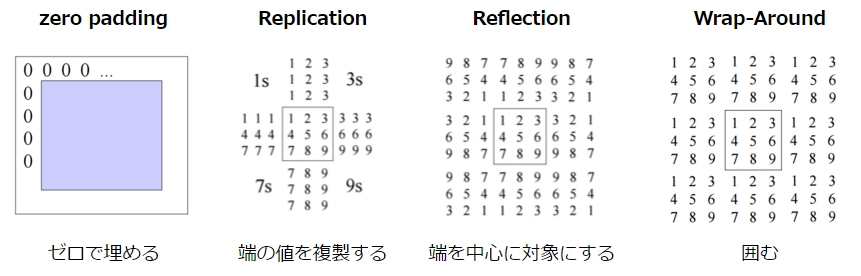
CSE/EE486 Computer Vision I, Lecture3, p26~
edgeの検出については、以上になります。ここまでの内容をまとめておきます。
- edgeを検出するには、画像における輝度の変化量を手掛かりにする
- 変化量は水平方向と垂直方向の2方向でとることができる。この値の二乗和平方根を変化量とし、これをMagnitudeと呼ぶ
- Magnitudeが一定のしきい値を超えた場合にedgeと判定することで、edgeの検出が可能になる
- 変化量を計算する際には、一般的にはスムージングを行う。これは周辺の変化量を加味することで、検出精度を上げるためのものである
- この「周辺」の対象範囲と、それに対する重みづけを定義するのがフィルタであり、様々な種類がある
cornerの検出
続いては、cornerの検出です。ここでは、cornerの検出によく利用されるHarris Corner Detectorについて説明していきます。これは行列の特性を非常にうまく利用した手法で、直観的には主成分分析に近いイメージになります。

主成分分析の細かい説明は他の記事に譲りますが、重要なポイントは以下2点です。
- データの広がる方向をよく説明できる指標を見つける。これは行列の固有ベクトルに相当する。
- 計算の結果得られる固有値は、その指標の説明能力を表す
これをHarrisに当てはめると、「データ」は当然ある点における水平方向・垂直方向それぞれの変化量をまとめたものになります。そうすると、上記の主成分分析の説明から以下のように類推できます。
- 固有ベクトルは「変化量の広がる方向」、つまりedgeの向きを表している
- 固有値が大きい場合は、「変化量の説明能力が高い」、つまりedgeの強さを表している
これによりまずedgeの検出が可能になり、そして「固有値が大きい複数の固有ベクトル」が存在する場合、それは即ち複数のedgeがある、つまりcornerであるということになります。
固有値をそれぞれ、とすると、その値の大きさにより以下のように分類が可能です。

CSE/EE486 Computer Vision I, Lecture 06, Corner Detection, p19
数式の説明もしておきます。まず、画像上のある点と、方向に、方向に移動した点との間の変化量をとすると、式で以下のように表せます。
はウィンドウ関数で、フィルタになります(Gaussian)。変化量がで、これをでスムージングして変化量を算出する、というイメージです。
この式をテイラー展開を使って近似すると以下のようになります(展開式は省略。興味ある方は、上図のリンクの講義資料をご参照ください)。
ここで、は以下になります。
、はそれぞれx軸、y軸での差異でを二乗すると上記の行列部分になります。やっていることは上記の式のと変わりません。そして、これこそが「変化量を記述した行列」で、これを特異値分解することで冒頭で述べたようなedge、cornerの判定が可能になります。
ただ、固有値の計算は結構手間なので、必要ないところではなるべく計算しないようにします。そのために利用されるのが、以下の指標です。
は定数で、だいたい0.04~0.06くらいです。Rの値によって以下のように分類できます。
- Rが大きい: corner
- Rが小さい: flat
- R < 0: edge
図にすると、以下のようになります。
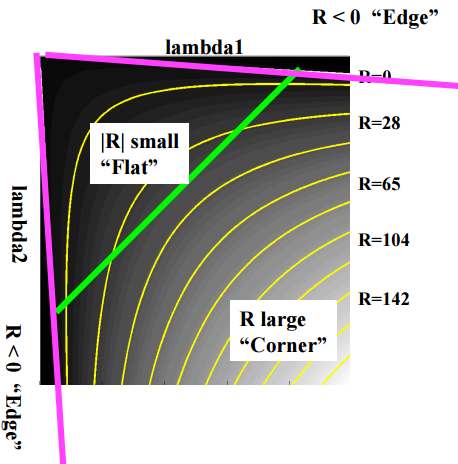
CSE/EE486 Computer Vision I, Lecture 06, Corner Detection, p22
これで手早くcornerを検出できるようになりました。ここで、corner検出についてまとめておきます。
- cornerは複数のedgeが集まる箇所と定義できる
- 変化量をまとめた行列の固有ベクトルからedgeの向き、固有値の大きさから変化量の大きさ(edgeらしさ)がわかる
- 2つの固有値の値を基に、edge、corner、flatを判定できる
- 固有値の計算は手間であるため、判定式を利用し計算を簡略化する
なお、Harrisはedgeの向きである固有ベクトルを考慮するため、画像の傾きなどに対し頑健です。ただ、スケール(拡大)については頑健ではありません。これは、拡大するにつれcornerが緩やかになり、edgeが区別しにくくなるためです。
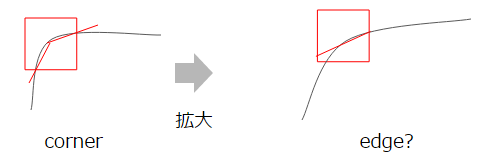
これを克服するための編み出された手法がFASTになります。詳細は割愛しますが、中心点を基準としてそれより暗いor明るいn点の連なりを認識する方法です。これは文字通りFASTな手法でかつ回転・拡大に対し共に頑健です。
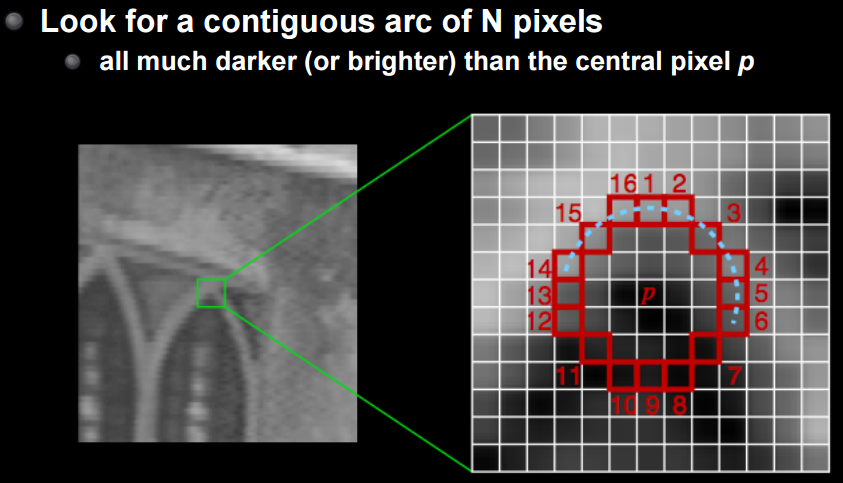
CS231M Mobile Computer Vision Class,Lecture5, Stitching + Blending, p24
特徴点の表現方法(Feature Description)
これで特徴点は検出できるようになりました。今度は、その特徴点を利用してなるべく一意な特徴表現、Feature Descriptionを作成することで画像のマッチングなどが行えるようにしたいです。
今までも少し触れましたが、このFeature Descriptionにとって望ましい特性は以下3点です。
- Translation: 画像のスライドに対して頑健
- Rotation: 画像の回転に対して頑健
- Scaling: 画像の拡大/縮小に対して頑健
Translationは単に位置が変わるだけなので対応は割と簡単で、前項のHarrisでも上げた通りRotationも何とかなります。ただ、Scalingへの対応、これは難しいです。下図から明らかなとおり、画像内の情報は拡大率によって著しく変わってしまうためです。

CSE/EE486 Computer Vision I, Lecture 31, Object Recognition : SIFT Keys, p31
そもそも、拡大をしたのならマッチングさせる範囲もそれに合わせて拡大しなければ、情報が落ちてしまうのは自明です。なぜなら同じ範囲でも収まる領域が変わってくるためです。

つまり、上述の3点の特性を満たすにはスケールを考慮する必要があります。Harrisでは固有ベクトルと固有値から「向き」と「強さ」だけでしたが、ここに「スケール」、つまりどの拡大値で得られるものなのか、を加味するということです。イメージ的には以下のような感じになります。

そして、このスケールを加味した特徴点の検出・記述を可能にするのがSIFTという手法になります。
SIFT (Scale Invariant Feature Transform)
SIFTの肝になっているのが、スケールごとの特徴点抽出になっています。これに使われているのがLoG/DoGという手法です。LogはLaplacian of Gaussianの略で、Gaussianフィルタでスムージングした画像の中の、変化量が最大の点を2回微分(=Laplacian)で求めるというものです。
Gaussianについてはスムージングで述べた通りなので、2次微分(=Laplacian)でなぜ変化量が最大の点が求められるのかについて簡単に説明します。

微分とは、端的にはある点における変化量を求めるものだと思ってください。そうすると、以下のようなことがわかります。
- 1次微分: 元の関数に対する変化量を表す=頂点が、変化量が最大(最小)の点を表す
- 2次微分: 変化量の変化を表す=1次微分の頂点付近では、変化の方向の切り替わりが発生する=1次微分の頂点は、軸と交わる点(zero-crossing point)と等しくなる
つまり、となる点が変化量が最大の点、特徴点として上げられるということです。この2次微分をかけるのに相当するフィルタを「ラプラシアン・フィルタ」と呼び、値が0に近いほど特徴点の可能性が高くなります。
※ただ、2次微分だけでは、1次微分の段階で0(=変化なし)な点と頂点のものとが区別できないので、1次微分の値が十分に大きいかを同時に見る必要あります。このことからもわかる通り、ノイズにとても弱いです。
そして、LoGに戻るとこれはその名の通り、Gaussianフィルタでスムージングをしてから、ラプラシアンフィルタで変化量が最大の点=特徴点を求めるという手法になります。
そして、LoGではGaussianフィルタを使うため、その(分散)を調整することができます。は大きいほどスムージングが強力にかかるため、変化量が大きい点が集まっているところしか検出できなくなります。これは逆もしかりで、感の良い方は気づいたかもしれませんが、これはちょうど拡大率を操作してみているのと同じ役割を果たしています。


CSE/EE486 Computer Vision I, Lecture 11, LoG Edge and Blob Finding, p19
SIFTでは、このを調整した複数の階層を用意して特徴点の検出を行います(スケールスペース)。以下は、その図になります。
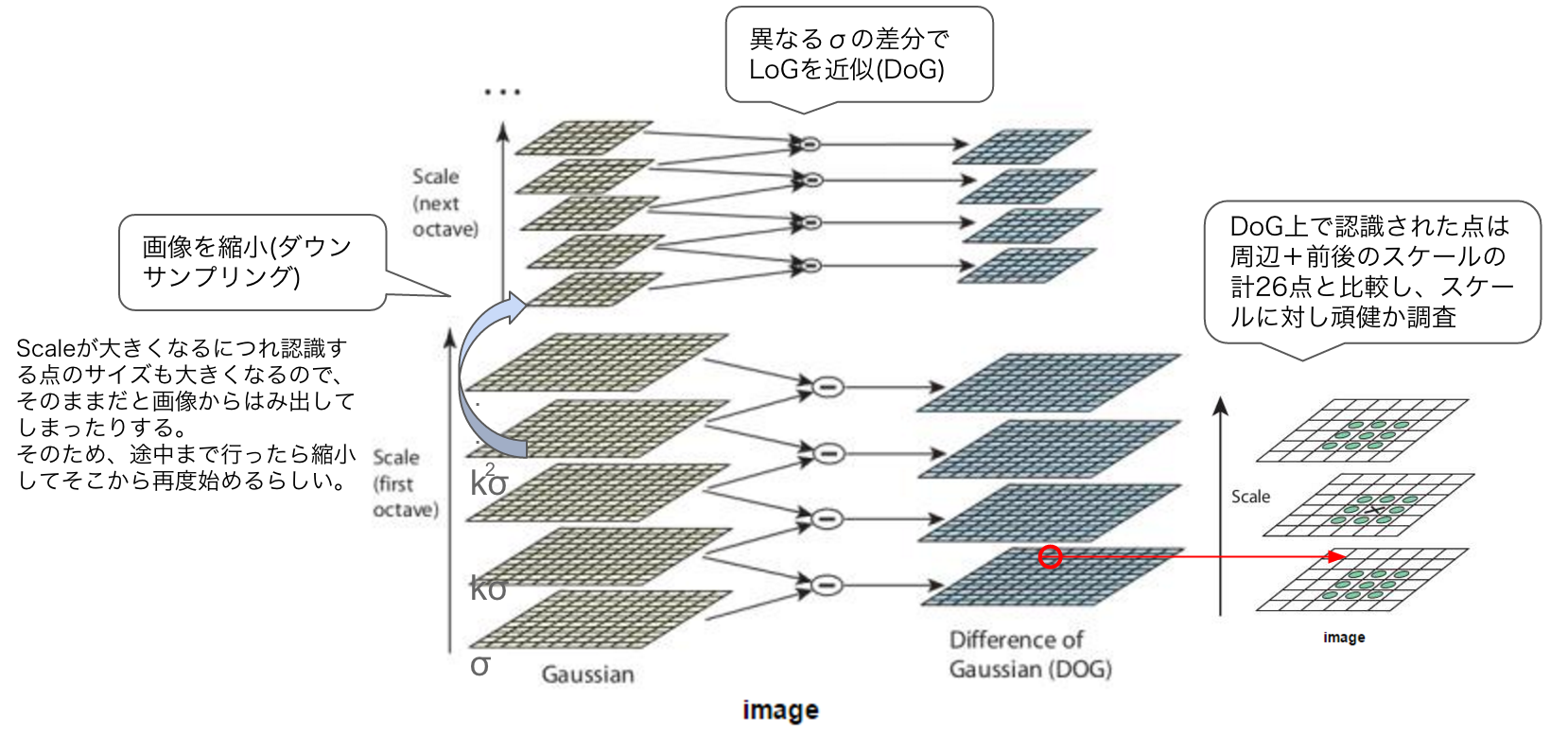
ここでは、LoGの計算を簡略化するために、を変えた2つの層の差分で近似を行っています。これがDoG(Difference of Gaussian)になります。発見された特徴点は、スケールに対し頑健かを見るため前後のスケールと比較します(周辺8点と、前後のスケールにおける各9点、計26点と比較)。
これで、スケールに頑健な特徴点がわかるようになりました。後はこの特徴点における変化量の「強さ」と「向き」ですが、これは変化量とその角度から取得します。
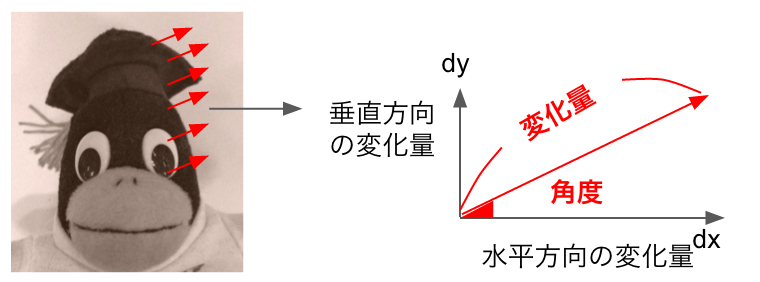
ここで、SIFTでは単一の特徴点だけでなく、それを中心とした16*16のマスを考慮します(この「マス」の大きさをbin sizeと呼びます)。
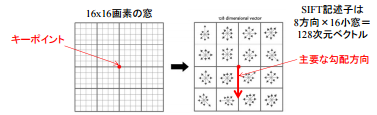
それをさらに4x4の領域に区切っていき、そこで縦軸に変化量(変化量のMagnitude)、横軸に向き(=変化量の勾配の角度)を取ったヒストグラムを作成します。

CSE/EE486 Computer Vision I, Lecture 31, Object Recognition : SIFT Keys, p24
上図は0〜36(360度に対応)でまとめていますが、最終的には8方向にまとめます。そうすると、4*4の各窓が8方向の要素を持つベクトルが出来上がります。この全128次元のベクトルがSIFT Vectorであり、これは「スケール」に対し頑健であり、「強さ」と「向き」がわかるという、3つの特性を備える特徴点記述になります。
このSIFT Vectorを利用することで、非常に精度の高い特徴点のマッチングなどが行えるようになります。
特徴点検出方法の進化
上記で挙げた特徴点の検出や記述の手法は年々進化しています。以下はSIFT登場前後までの手法の進化です。回転・スケールに対し頑健な特徴量を得ていく過程がわかるかと思います。

MIRU2013チュートリアル:SIFTとそれ以降のアプローチ, p5
こちらはSIFT以降の進化になります。SIFTを高速化されたSURFという手法もよく使われます。なお、SIFTもSURFも特許が取られており、利用にあたっては特許料が発生します。そのため、ここまで説明しておいてなんですが、実際利用するにあたってはORBや、OpenCV 3.0で追加されたAKAZEなどが良いようです。何もSIFT/SURFより高速です。

MIRU2013チュートリアル:SIFTとそれ以降のアプローチ, p93
今回ご紹介した基礎的な手法を理解しておけば、今後新しい手法が登場したときも、何が改良されてきたのかがわかり易くなると思います。
特徴点のマッチング
検出した特徴点は、様々な用途に使えます。代表的な例として、画像のマッチングに使用する方法を紹介したいと思います。
まず、画像のマッチングに際しては比較対象とする特徴点の周辺領域を切り出し(この切り出したものをパッチといいます)、それがもう片方の画像にもあるか調べる、というのが基本的な流れになります。このパッチをどう使うかについて、以下の2種類があります。
- Templateベース: もう片方の画像にパッチと一致するものがないか確認する
- Featureベース: パッチから特徴を抽出し、その特徴と一致するものがないか確認する
イメージ的には下図のようになります。

いずれにせよ、比較を行う際には類似度(similarity)を測るための関数が必要になります。※画像の全範囲について類似度を計算していると大変なので、探索範囲を絞る方法も必要になってきますが、ここでは触れません。
類似度を測る代表的な指標としては、以下があります。
- SSD (sum of squared differences): 差の二乗和
- NCC (normalized cross correlation): 正規化した相互相関
SSDは一番単純な指標で、TemplateやFeature同士の差を見て0に近ければ類似しているとする方法です。どれくらいの距離であればよいか、つまり閾値については、最も一致する特徴点との比率が用いられることが多いです。
NCC、というか相互相関は類似性を示す尺度で、内積を計算することで得られます。例えば、全く関係ない(=互いに独立している)ベクトル同士だと直行しているはずで、直行しているベクトルの内積は0になります。逆に0以外であれば正・あるいは負の相関があることになります。そして、正規化(平均0・分散1)した上で相互相関を取ったものが正規化相互相関です。
一応式も書いておきます
NCCは、内積を取るという性質上Templateでフィルタをかけているような処理になります。以下は実際に処理してみた例で、Templateに一致する箇所が反応しているのが分かります。

CSE/EE486 Computer Vision I, Lecture 7, Template Matching, p7
より厳密なマッチングを行いたい場合は、A->BだけでなくB->Aからもマッチングを行い双方で一致していると判断されたもののみ使うという方法もあります。
この特徴点のマッチングを使用することで、パノラマのような写真を作ったり画像の分類や検索などを行うことが可能になります。
OpenCVでの実装
最後に、OpenCVでの実装方法を紹介しておきます。以下のリポジトリに、Jupyter notebookで書いたサンプルをおいています。
icoxfog417/cv_tutorial_feature
なおOpenCVのインストールですが、Windowsの方はAnaconda(conda)がお勧めです。numpyやmatplotlibはもちろんですが、OpenCV本体も以下から一発でインストール可能です。
実装に当たっては、以下のOpenCV公式のチュートリアルを参考にしました。
書くコード自体はほんの数行ですが、パラメーターの調整を行わないとうまく検出できないことが多く(特にSIFT)、そしてパラメーターの調整にはやはり理論的な理解が必要です。そういう意味では、本当の意味でOpenCVを使いこなすには理論的な理解は不可欠だと思います。

今回ご紹介した解説が、石化を解き真の画像処理マスターとなるための手助けとなれば幸いです。
研究動向
最近はConvolutional Neural Network(CNN)が登場し、画像からの特徴抽出という点では古来からの手法とCNN、どちらがどういいのかと言う点がまず気になると思います。
その点についてのサーベイを、まず紹介します。
- SIFT Meets CNN: A Decade Survey of Instance Retrieval
- Object Recognition SIFT vs Convolutional Neural Networks
CNNはやはり学習が必要な点と処理速度の点でハンデがありますが、様々なタスクを高い精度でこなすことができるという点はやはり強いです。SIFTに代表される手法に含まれる考えは未だ有用なものも多いので、組み合わせによってより高みへ行ける・・・というのが上記の論文で提案されています。
DNNを利用した特徴抽出の研究としては、以下のようなものがあります。
-
OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks (ICLR, 2014)
- ImageNet 2013の領域認識のタスクで1位をとった手法。CNNのFeature Mapを単に利用するのでなく、少しずらした(オフセットの異なる)プーリングを複数種類かけて、その結果を統合するというもの。これで位置ずれに対して頑健にしている。GitHubで実装が公開されている
-
Discriminative Learning of Deep Convolutional Feature Point Descriptors (ICCV, 2015)
- 2つの画像パッチを入力し、その間の誤差(似ているor似ていない)で学習させるという手法。
- 上記ページから、GitHub実装を見ることができる。
- 同じ筆者で、ファッション画像の特徴抽出を行うという研究もあり
-
Adversarial Autoencoders (2015)
- 画像の生成で一世を風靡したGANの応用も進んでいます。こちらはVAEの弱点であったサンプルと想定する正規分布の差異の計算にGANを利用したもの。一言まとめはこちら。
-
PN-Net: Conjoined Triple Deep Network for Learning Local Image Descriptors (2016)
- 先ほどのDiscriminative~に似た発想で、画像とそれに対するpositive/negativeの画像のセット(Triple)で学習を行う手法
- 改良版が発表された模様。こちらはtfeat (BMVC, 2016)といい、TensorFlow実装が公開されている。リアルタイムでの領域認識のデモもあり。
-
LIFT: Learned Invariant Feature Points (ECCV, 2016)
- 特徴点検知->(回転)角度推定->(角度独立な)特徴量記述の取得、という特徴検知の基本となる3プロセスを、CNNを組み合わせて実現したもの。
-
Adversarial Feature Learning (NIPS 2016 Workshop)
- Adversarialの応用で、GANがとらえている特徴を逆算して獲得しようというBi-directionalなGANの仕組みの提案(BiGAN)。これ自体の利用は、ほかの分野でも使えそう。
- 似た研究で、Adversarially Learned Inferenceがある。解説サイトを見るとわかるが、ほぼ同様の発想。
参考文献
-
実践 コンピュータビジョン
説明は正直かなりぶっきらぼうな感じで、初学者がこれ単体で理解するのは難しいと思う。 -
Computer Vision I
ペンシルベニア州立大学のComputer Visionのコース。とても丁寧でわかりやすい -
Mobile Computer Vision
StanfordのモバイルでComputerVisionを行うコース。IntroductionからしばらくはAndroidの開発の仕方などの説明で、Stitching + BlendingからComputer Visionの説明。モバイルに組み込みたい人には特におすすめ。 -
OpenCV公式
かなりわかりやすくまとまっており、かつOpenCVベースのコードサンプルがある。おすすめ。 -
電気通信大学大学院 情報理工学研究科 の資料
第9回から画像処理の話。図解が豊富でわかりやすい。最も基礎となる画像の微分の基礎を理解するならここ。 -
意味的マルチメディア処理 第A2回(2013年10月15日)
SIFTについて理解するならこちら。非常にわかり易い -
MIRU2013チュートリアル:SIFTとそれ以降のアプローチ
SIFTの解説中心だが、後半(92~)に手法の体系的・歴史的な背景が整理されている -
VLFeat Documentation
Cなどで使える画像の特徴点抽出のライブラリのドキュメント。英語だがかなりわかりやすい。 - Can any one help me understand Deeply SIFT ?
- 固有ベクトル、主成分分析、共分散、エントロピー入門

人気の投稿
ORGANIZATION











とてもいい記事でした。ありがとうございます。
ひとつ質問ですが、「cornerの検出」の項でプロットしているのは何ですか?
いきなりベクトルが出てきたけれど、これって一体何のベクトルだろうと、そこが理解できませんでした。
Harris Corner Detectionの方でプロットされているのは、文中にもあるとおり「ある点(周辺)における水平方向・垂直方向それぞれの変化量の分布」になります。この変化量の「方向性」を示すのが、固有ベクトルになります。
左の主成分分析の方は、似ていることを示すためのものなので特に何をプロットしているということはないです。
ご回答ありがとうございます。
おかげさまで理解できたと思います。
注目画素と、その周辺画素に関して水平(x)方向、垂直(y)方向の輝度値変化量をプロットし、そのデータの広がり方を見てコーナーかどうかを判定するのがHarris Corner Ditectionであり、
データの広がり方(方向性と量=エッジの方向と強さ)を分析するための道具が固有ベクトル。分析指標が本文中のR……と理解しました。
とても勉強になる記事をありがとうございます。