













概要
ECSで本番運用を始めて早半年。ノウハウが溜まってきたので公開していきます。
設計
基本方針
基盤を設計する上で次のキーワードを意識した。
Immutable infrastructure
- 一度構築したサーバは設定の変更を行わない
- デプロイの度に新しいインフラを構築し、既存のインフラは都度破棄する
Infrastructure as Code (IaC)
- インフラの構成をコードで管理
- オーケストレーションツールの利用
Serverless architecture
- 非常中型プロセスはイベントごとにコンテナを作成
- 冗長化の設計が不要
アプリケーションレイヤに関して言えば、Twelve Factor Appも参考になる。コンテナ技術とも親和性が高い。
ECSとBeanstalk Multi-container Dockerの違い
以前に記事を書いたので、詳しくは下記参照。
Beanstalk Multi-container Dockerは、ECSを抽象化してRDSやログ管理の機能を合わせて提供してくれる。ボタンを何度か押すだけでRubyやNode.jsのアプリケーションが起動してしまう。
一見楽に見えるが、ブラックボックスな部分もありトラブルシュートでハマりやすいので、素直にECSを使った方が良いと思う。
ALBを使う
ECSでロードバランサを利用する場合、CLB(Classic Load Balancer)かALB(Application Load Balancer)を選択できるが、特別な理由がない限りALBを利用するべきである。
ALBはURLベースのルーティングやHTTP/2のサポート、パフォーマンスの向上など様々なメリットが挙げられるが、ECSを使う上での最大のメリットは動的ポートマッピングがサポートされたことである。
動的ポートマッピングを使うことで、1ホストに対し複数のタスク(例えば複数のNginx)を稼働させることが可能となり、ECSクラスタのリソースを有効活用することが可能となる。
※1: ALBの監視方式はHTTP/HTTPSのため、TCPポートが必要となるミドルウェアは現状ALBを利用できない。
アプリケーションの設定は環境変数で管理
Twelve Factor Appでも述べられてるが、アプリケーションの設定は環境変数で管理している。
ECSのタスク定義パラメータとして環境変数を定義し、パスワードやシークレットキーなど、秘匿化が必要な値に関してはKMSで暗号化。CIによってECSにデプロイが走るタイミングで復号化を行っている。
ログドライバ
ECSにおいてコンテナはデプロイの度に破棄・生成されるため、アプリケーションを始めとする各種ログはコンテナの内部に置くことはできない。ログはイベントストリームとして扱い、コンテナとは別のストレージで保管する必要がある。
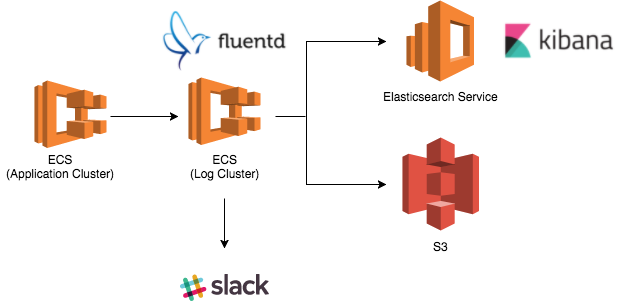
今回はログの永続化・可視化を考慮した上で、AWSが提供するElasticsearch Service(Kibana)を採用することにした。
ECSは標準でCloudWatch Logsをサポートしているため、当初は素直にawslogsドライバを利用していた。CloudWatchに転送してしまえば、Elasticsearch Serviceへのストリーミングも容易だったからである。

しかし、Railsで開発したアプリケーションは例外をスタックトレースで出力し、改行単位でストリームに流されるためログの閲覧やエラー検知が非常に不便なものだった。
Multiline codec plugin等のプラグインを使えば複数行で構成されるメッセージを1行に集約できるが、AWS(Elasticsearch Service)ではプラグインのインストールがサポートされていない。
EC2にElasticsearchを構築することも一瞬考えたが、Elasticsearchへの依存度が高く、将来的にログドライバを変更する際の弊害になると考えて止めた。
その後考案したのがFluentd経由でログをElasticsearch Serviceに流す方法。この手法であればFluentdでメッセージの集約や通知もできるし、将来的にログドライバを変更することも比較的容易となる。
ジョブスケジューリング
アプリケーションをコンテナで運用する際、スケジュールで定期実行したい処理はどのように実現するべきか。
いくつか方法はあるが、1つの手段としてLambdaのスケジュールイベントからタスクを叩く方法がある(Run task)。この方法でも問題はないが、最近(2017年6月)になってECSにScheduled Taskという機能が追加されており、Lambdaに置き換えて利用可能となった。Cron形式もサポートしているので非常に使いやすい。
運用
ECSで設定可能なパラメータ
ECSコンテナインスタンスにはコンテナエージェントが常駐しており、パラメータを変更することでECSの動作を調整できる。設定ファイルの場所は /etc/ecs/ecs.config。
変更する可能性が高いパラメータは下表の通り。他にも様々なパラメータが存在する。
| パラメータ名 | 説明 | デフォルト値 |
|---|---|---|
| ECS_LOGLEVEL | ECSが出力するログのレベル | info |
| ECS_AVAILABLE_LOGGING_DRIVERS | 有効なログドライバの一覧 | ["json-file","awslogs"] |
| ECS_ENGINE_TASK_CLEANUP_WAIT_DURATION | タスクが停止してからコンテナが削除されるまでの待機時間 | 3h |
| ECS_IMAGE_CLEANUP_INTERVAL | イメージ自動クリーンアップの間隔 | 30m |
| ECS_IMAGE_MINIMUM_CLEANUP_AGE | イメージ取得から自動クリーンアップが始まるまでの間隔 | 1h |
パラメータ変更後はエージェントの再起動が必要。
$ sudo stop ecs
$ sudo start ecs
クラスタのスケールアウトを考慮し、ecs.configはUserDataに定義しておくと良い。
以下はfluentdを有効にしたUserDataの記述例。
#!/bin/bash
echo ECS_CLUSTER=sandbox >> /etc/ecs/ecs.config
echo ECS_AVAILABLE_LOGGING_DRIVERS=["fluentd\"] >> /etc/ecs/ecs.config
CPUリソースの制限
現状ECSにおいてCPUリソースの制限を設定することはできない(docker runの--cpu-quotaオプションがサポートされていない)。
タスク定義パラメータcpuは、docker runの--cpu-sharesにマッピングされるもので、CPUの優先度を決定するオプションである。従って、あるコンテナがCPUを食いつぶしてしまうと、他のコンテナにも影響が出てしまう。
尚、Docker 1.13からは直感的にCPUリソースを制限ができる--cpusオプションが追加されている。是非ECSにも取り入れて欲しい。
ユーティリティ
実際に利用しているツールを紹介。
- awslabs/ecs-logs-collector ECSに関する各種ログを集約して出力
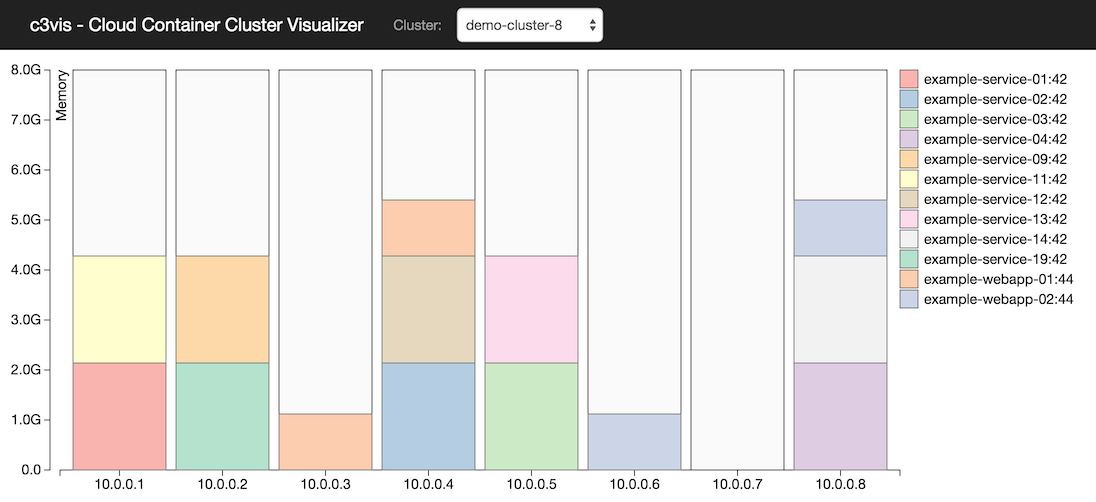
- ExpediaDotCom/c3vis ECSクラスタのリソース使用状況をビジュアライズ化
ルートボリューム・Dockerボリュームのディスク拡張
ECSコンテナインスタンスは自動で2つのボリュームを作成する。1つはOS領域(/dev/xvda 8GB)、もう1つがDocker領域(/dev/xvdcz 22GB)である。
クラスタ作成時にDocker領域のサイズを変更することはできるが、OS領域は項目が見当たらず変更が出来ないように見える。
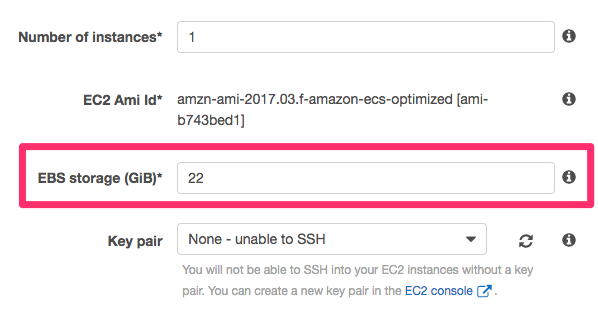
どこから設定するかというと、一度空のクラスタを作成し、EC2マネージメントコンソールからインスタンスを作成する必要がある。
また、既存ECSコンテナインスタンスのOS領域を拡張したい場合は、EC2マネージメントコンソールのEBS項目から変更可能。スケールアウトを考慮し、Auto scallingのLaunch Configurationも忘れずに更新しておく必要がある。
補足となるが、Docker領域はOS上にマウントされていないため、ECSコンテナインスタンス上からdf等のコマンドで領域を確認することはできない。
デプロイ
ECSのデプロイツールは色々ある(ecs_deployerは自分が公開している)。
- aws/amazon-ecs-cli
- openfresh/ecs-formation
- silinternational/ecs-deploy
- eagletmt/hako
- naomichi-y/ecs_deployer
社内で運用する際はECSでCIを回せるよう、ecs_deployerをコアライブラリとしたCIサーバを構築した。
デプロイ方式
- コマンド実行形式のデプロイ
- GitHubのPushを検知した自動デプロイ
- Slackを利用したインタラクティブデプロイ
デプロイフロー
ECSへのデプロイフローは次の通り。
- リポジトリ・タスクの取得
- イメージのビルド
- タグにGitHubのコミットID、デプロイ日時を追加
- ECRへのプッシュ
- タスクの更新
- 不要なイメージの削除
- ECRは1リポジトリ辺り最大1,000のイメージを保管できる
- サービスの更新
- タスクの入れ替えを監視
- コンテナの異常終了も検知
- Slackにデプロイ完了通知を送信
現在のところローリングデプロイを採用しているが、デプロイの実行から完了までにおよそ5〜10分程度の時間を要している。デプロイのパフォーマンスに関してはまだあまり調査していない。
ログの分類
ECSのログを分類してみた。
| ログの種別 | ログの場所 | 備考 | |
|---|---|---|---|
| サービス | AWS ECSコンソール | サービス一覧ページのEventタブ | APIで取得可能 |
| タスク | AWS ECSコンソール | クラスタページのTasksタブから"Desired task status"が"Stopped"のタスクを選択。タスク名のリンクから停止した理由を確認できる | APIで取得可能 |
| Docker daemon | ECSコンテナインスタンス | /var/log/docker | ※1 |
| ecs-init upstart ジョブ | ECSコンテナインスタンス | /var/log/ecs/ecs-init.log | ※1 |
| ECSコンテナエージェント | ECSコンテナインスタンス | /var/log/ecs/ecs-agent.log | ※1 |
| IAMロール | ECSコンテナインスタンス | /var/log/ecs/audit.log | タスクに認証情報のIAM使用時のみ |
| アプリケーション | コンテナ | /var/lib/docker/containers | ログドライバで変更可能 |
※1: ECSコンテナインスタンス上の各種ログは、CloudWatch Logs Agentを使うことでCloudWatch Logsに転送することが可能(現状の運用ではログをFluentdサーバに集約させているので、ECSコンテナインスタンスにはFluentdクライアントを構築している)。
サーバレス化
ECSから少し話が逸れるが、インフラの運用・保守コストを下げるため、Lambda(Node.js)による監視の自動化を進めている。各種バックアップからシステムの異常検知・通知までをすべてコード化することで、サービスのスケールアウトに耐えうる構成が容易に構築できるようになる。
ECS+Lambdaを使ったコンテナ運用に切り替えてから、EC2の構築が必要となるのは踏み台くらいだった。
トラブルシュート
ログドライバにfluentdを使うとログの欠損が起きる
ログドライバの項に書いた通り、アプリケーションログはFluentd経由でElasticsearchに流していたが、一部のログが転送されないことに気付いた。
構成的にはアプリケーションクラスタからログクラスタ(CLB)を経由してログを流していたが、どうもCLBのアイドルタイムアウト経過後の最初のログ数件でロストが生じている。試しにCLBを外してみるとロストは起きない。

ログクラスタ(ECSコンテナインスタンスの/var/log/docker)には次のようなログが残っていた。
time="2017-08-24T11:23:55.152541218Z" level=error msg="Failed to log msg \"...\" for logger fluentd: write tcp *.*.*.*:36756->*.*.*.*:24224: write: broken pipe"
3) time="2017-08-24T11:23:57.172518425Z" level=error msg="Failed to log msg \"...\" for logger fluentd: fluent#send: can't send logs, client is reconnecting"
同様の問題をIssueで見つけたが、どうも現状のECSログドライバはKeepAliveの仕組みが無いため、アイドルタイムアウトの期間中にログの送信が無いとELBが切断してしまうらしい(AWSサポートにも問い合わせた)。
という訳でログクラスタにはCLBを使わず、Route53のWeighted Routingでリクエストを分散することにした。
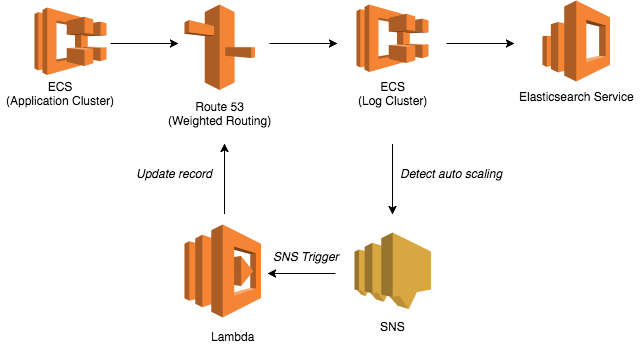
尚、この方式ではログクラスタのスケールイン・アウトに合わせてRoute 53のレコードを更新する必要がある。
ここではオートスケールの更新をSNS経由でLambdaに検知させ、適宜レコードを更新する仕組みを取った。
コンテナの起動が失敗し続け、ディスクフルが発生する
ECSはタスクの起動が失敗すると数十秒間隔でリトライを実施する。この時コンテナがDockerボリュームを使用していると、ECSコンテナエージェントによるクリーンアップが間に合わず、ディスクフルが発生することがあった(ECSコンテナインスタンスの/var/lib/docker/volumesにボリュームが残り続けてしまう)。
この問題を回避するには、ECSコンテナインスタンスのOS領域(※1)を拡張するか、コンテナクリーンアップの間隔を調整する必要がある。
コンテナを削除する間隔はECS_ENGINE_TASK_CLEANUP_WAIT_DURATIONパラメータを使うと良い。
※1: DockerボリュームはDocker領域ではなく、OS領域に保存される。OS領域の容量はデフォルトで8GBなので注意が必要。
また、どういう訳か稀に古いボリュームが削除されず残り続けてしまうことがあった。そんな時は次のコマンドでボリュームを削除しておく。
# コンテナから参照されていないボリュームの確認
docker volume ls -f dangling=true
# 未参照ボリュームの削除
docker volume rm $(docker volume ls -q -f dangling=true)
ECSがELBに紐付くタイミング
DockerfileのCMDでスクリプトを実行するケースは多々あると思うが、コンテナはCMDが実行された直後にELBに紐付いてしまうので注意が必要となる。
bundle exec rake assets:precompile
このようなコマンドをスクリプトで実行する場合、アセットがコンパイル中であろうがお構いなしにELBに紐付いてしまう。
時間のかかる処理は素直にDockerfile内で実行した方が良い。










