セクションナイン の 吉田真吾(@yoshidashingo)です。
昨今のサーバーレスアーキテクチャの実装パターンについて5つの分野のユースケースでまとめました。
今回の実装方法はほとんどAWSがベースですが、クラウド各社やOSSで提供されているFunctionsのサービスにはさほど機能差はなく(そもそもシンプルなコンセプトですし)、連携するサービスまで含めて自分のアプリケーションのユースケースに合っていることのほうが大事になってきます。また、そもそもいくつかは実装自体がPaaSのオプション機能として組み込まれている事業者もあります。よって、この先連携先の機能強化などによりもっと多くのパターンが発見されることになると思っています。
【1】Webアプリケーション
シングルページアプリケーション
クライアント->APサーバー->データベースという従来の3層構造における「APサーバー」が不要になるデザインです。その分慣れているMVCのバランスが変わったり(ViewとController、およびModelの一部をフロントに実装する必要がでてきたり)、DAO層のようなコネクションプーリングやページ制御などのDBMSへの効率的なアクセス方法がなかったり、入力内容のバリデーションの実装がクライアント側/サーバー側で冗長になったりという変更点はあります。ただし、認証やストレージ、ロジックなどを役割別に分割してスケール管理しなくて済むサービスにオフロードすれば、運用やサービスレベル管理のコストが最小化できるようになります。
ex. Serverless Single Page Apps
- 目的:WebアプリケーションのLessOps化
- 説明:クライアントにビュー、ルーターを実装して、認証、データベース、ロジック、キュー、メールなどのサーバー側の処理に外部サービスを利用することでサーバー側のリソースをアウトソースする。
- 実装:SPAから直接「認証サービス(ユーザープール、認証フェデレーション、認可)」「データベースサービス」「ロジック(バリデーション、集計処理、検索機能など)」「キュー」「通知(SMS、メール送信、電話など)」が実現可能なサービスを利用する。
Serverless Single Page Apps: Fast, Scalable, and Available
- 作者: Ben Rady
- 出版社/メーカー: Pragmatic Bookshelf
- 発売日: 2016/06/24
- メディア: ペーパーバック
- この商品を含むブログを見る
Web API
あらかじめ定義されたHTTP(S)インタフェースで通信を行い、必要なデータへのアクセスを可能にします。
REST API
RESTfulなAPIでは「https://(Endpoint)/resource/dog」や「https://(Endpoint)/search/tokyo」といった一意に特定可能なURIに対して、HTTPメソッドを使いGET(データの読取り)/PUT(更新)/DELETE(削除)といった制御を行います。
GraphQL
最近盛り上がりつつある GraphQL においてはHTTP(S)のPOSTメソッドでリクエスト内容と欲しいレスポンス内容を構造とともに宣言的に記述して送信することで、REST APIよりもリッチなデータアクセスを可能にしています。
Serverless GraphQL - Kevin Old | Full-Stack JavaScript Engineer | React.js | Node.js
Nodeであればすでにライブラリ化されているnpmでインストールできる他、OSX上で動作するGraphiQLというクライアントアプリケーションを使って(GraphQL版postmanみたいなもの)テストすることも可能です。
非同期Webジョブ
伝統的な3層構造は、APサーバー上で「プロセスやスレッドの管理」「セッション管理」「O/Rマッパー」「DBコネクション管理」「エラー制御」などで、あらかじめ組込みの機能が使えます。 これは開発者にとっては非常に都合が良く、ビジネスロジックに集中しやすくなる反面、便利がゆえに通常のWebアクセスのワークロードと、たとえばCSVアップロードによるデータベース洗替えるような大きいワークロードを同一プロセス(アプリ)に実装してしまいリソース逼迫などの問題を引き起こす場合があります。
フレームワークにもよりますが、一般的に、アプリケーションのプロセス(やスレッド)に割り当てる最大メモリサイズやワーカープロセス数は無限には設定できないので、いずれもインスタンスとワークロードを天秤にかけて適切な値にチューニングすることで有効活用できるようにしないといけないのですが、Web表示のワークロードとバッチ級のワークロードが同一アプリ内に混在していると、よりリソース食いなほうを意識した設定にせざるを得ないため非効率になってしまいます。インスタンス台数を並べた割に実際の稼働率が低くなってしまうというもったいない現象が起きてしまいます。また、そのワークロードがスパイキーだったとすると、そもそも湯水のようにサーバーを並べたところで処理しきれないという事態さえ起きてしまいます。
「同一アプリケーション内」に限らず、オンプレにありがちな「別アプリケーション(プロセス)だが同一インスタンスに載せてしまっている」ものについても物理的なりソースに対して似たような課題を引き起こすことになります。
そもそもそのような処理はキューを使った非同期処理にしておくのが定石ですので、これを機に「大きいワークロード、またはスパイキーなワークロード、あるいはその両方の性質を持つワークロード」をモノリシックな構成から外出ししてサーバーレスな実装に置き換えることで、それらのスケールやコストを気にしなくてよくなるだけでなく、既存のWebアプリにとって邪魔者を追い出せるという都合の良い結果になります。
「CSVインポート/エクスポート」「画像のサムネイル生成や動画のサイズ変換処理」などを代表例としていますが、分析系のジョブなど複数の実行環境がリソースを食い合ってしまっているようなパターンが皆さんの身近にもあるのではないでしょうか。
ex. CSVインポート/エクスポート
- 目的:リソースの有効活用、スパイキーかつメモリ消費量がWebアプリとは違うジョブの切り出し
- 実装:ファイルアップロード画面(認証つき)からS3に直接ファイルをアップロードする。アップロードしたオブジェクトをトリガーにしてデータベースへのインポートやETL処理をおこなう。逆方向のエクスポート処理は既存のWeb画面からボタンを押されたことをトリガーにして、SQSにキューイングする。ワーカーがデータのアンロード処理を行いファイル作成を行い、S3に格納し、DynamoDB上のステータスを更新する。
ex. 画像のコンテンツ生成ジョブ
- 目的:ワーカーのスケール管理からの解放
- 実装:S3の特定バケットに画像ファイルがアップロードされたら、発火したトリガーを契機にImageMagikでリサイズや切り出しを行う。
日経新聞さんの例
※切り出したワークロードがFaaSに乗らない大きなものである場合(処理の対象量が不定である場合も含めて)、イベント処理はFaaSで行いますが、バッチ本体であるワーカー処理はElastic Beanstalk上のワーカーティアやAWS Batch(ECS上でマイクロバッチを実行できるサービス)といったバッチ基盤を用意することを考えてみましょう。
CMSのコンテンツ管理と配信を分離する
ex. Serverless CMS
- 目的:コンテンツ管理と配信の分割とイベント連携
- 説明:コンテンツ管理のワークロードと配信のワークロードのアンバランスさ(投稿はしないがたくさん読まれる、投稿はよくするが読まれない)を解消し、必要なリソースのみ調達するために、CMSで生成・更新されるコンテンツをトリガーで連携して、配信プラットフォームと同期する。配信プラットフォームと分割されたCMSはデマンドベースで利用できればよいためコンテナ化して必要に応じて起動することで、コスト削減だけでなく、セキュリティ的にCMSがつねに攻撃にさらされることを避けられる。
- 実装:WordPressからS3へアップロードするプラグイン StaticPress を用いてコンテンツを生成して配信用のS3やCDNにアップロードする。あるいはそれをサービス化している Shifter を使うことで、WordPressのインスタンス自体を常駐不要にする。
Shifterの例)
【2】運用業務
監視 - Monitoring
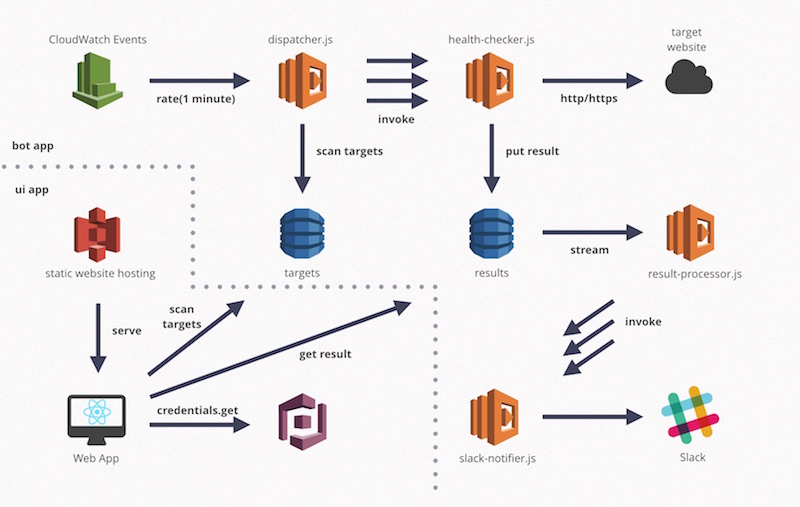
ex. Webサイト監視
- 目的:サーバーなどのリソース監視ではなく、ユーザーから見えるURLベースの動作確認を行うことで、サイトの健全性を担保する
- 実装:CloudWatch Eventsによる定期的なトリガーで監視対象の管理プロセスや実際のヘルスチェックプロセスをLambdaで実装。結果もbotから通知を行うことで一連の流れをサーバーレスに実装する。ヘルスチェックのプロセスの内容や受け先に専用ページを用意(専用のトークンがあるときのみ通すなど)することでディープヘルスチェックすることもできる。
ちなみに、Functionを使わなくても、Application Insightsというサービスを使えば、複数リージョンのポイントからURL監視など(対象はURLなのでオンプレでもAWSでもOK)が実現できるようです。
ex. オンコールシステム
- 目的:「アラートをトリガーに電話を鳴らす」「電話口の番号入力でリモートコマンドを実行する」「ローテーションにより電話を鳴らす相手を制御する」「電話に出ない場合は次の人にエスカレートする」「それらの状況をインシデントDBにすべて記録する」といった高機能なアプリを自作する。
- 実装:ここでは監視システムにZabbixなどを想定するが、td-agentなどで収集したアプリケーションログやSyslogを監視しアラートを発見した際に、DynamoDBから輪番のリストを取得してHTTPSでTwilioなどをキックし、レスポンス内容からZabbixに登録されているリモートコマンドを実行することで、アラートの一次対応が可能なシステムを構築する。
また、Twilio自体にもNode.jsで書けるFunctionsが搭載されたため、Twilio側で用意されている便利なライブラリと合わせて独自の制御が可能になりました。
Introducing Twilio Functions — Public Beta Now Open
先日ローンチした Amazon Connect でも、同様に電話を鳴らしてリモートコマンドの実行まで組込みできるようです。
ex. 不正なリクエストの遮断
- 目的:不正なリクエスト(4xx系)を送ってくるIPアドレスを自動的に遮断する。
- 実装:CloudFrontのログから不正なリクエストを送ってきているIPを読取り、IPブラックリストを作成してWAFのWebACLで遮断する。
これを応用して、短時間に同一IPから閾値以上のアクセスを受けている(DDoSの可能性)場合の遮断もできます。(が、素早く検知して遮断できるわけではないのと、単純な集計結果からブラックリストを作成するので、実用上はしっかり吟味する必要があります)
How to Configure Rate-Based Blacklisting with AWS WAF and AWS Lambda | AWS Security Blog
ということを書いていたらAWS WAFで上記をオプション機能として組み込めるレートベースのリクエスト遮断機能が追加されました。
AWS Announces Rate-Based Rules for AWS WAF
レートベースのブラックリスト作成、ELBのログからLambdaで生成して入れ替えるの入れてもらっちゃったところあるからWAFの機能に早速置換えだな。便利便利。
— Shingo Yoshida (@yoshidashingo) 2017年6月22日
保守 - Maintenance
ex. リソースの自動拡張
- 目的:リソースのプロビジョニングの自動化
- 説明:Kinesis Streamsのシャード拡張など、オンデマンドにスケールしないリソースを監視して閾値に応じて自動的にスケールさせる。
Scale Your Amazon Kinesis Stream Capacity with UpdateShardCount | AWS Big Data Blog
ちなみに同様に性能を自分で管理しなければいけなかったDynamoDBのキャパシティユニットはついにAuto Scalingできるようになりました。
新機能 – Auto Scaling for Amazon DynamoDBについて | Amazon Web Services ブログ
運用 - Operation
ex. Step Functionsを使ったバッチジョブの運行制御
- 目的:バッチ処理のスケーラビリティ、LessOps化
- 実装:Step Functionsを使い、時間起動の処理やエラー時の処理などを制御するステートマシンを実装する。
www.slideshare.net
現状UIが貧弱なので、Amazon States LanguageでJSONを手書きするというのがツラいポイントですかね。
https://states-language.net/spec.htmlstates-language.net
同様にステートマシンを定義でき、 IFTTT や Zapier のようなUIを提供しているAzureのLogic Appsではシンプルなアプリケーション連携だけでなく、Office 365やBoxなどをイベントソースにして各種サービス(もちろんAzure Functionsも)と連携できたりもします。
ex. EC2インスタンスの自動起動・停止
- 目的:開発環境や決まった時間に負荷の上がる業務用のEC2インスタンスを平日日中以外には停止しておくことで、コストを節約する。
- 実装:CloudWatch Events + Lambda。CloudWatch EventsでCron形式に実行タイミングを指定し、起動や停止のLambda関数を実行する。ただしこれだとインスタンスごとの細かい起動/停止時刻を分けにくい(できるがフィルターするタグルールが複雑になる)ため、CloudWatch Eventsは(空振りでも)定期的に実行し、EC2インスタンスのタグにCron形式の指定を行い、Lambda関数がタグの内容から時刻を判断(起動されてるべき時刻であれば起動、停止されているべき時刻であれば停止)する実装もできる。(以下参照)
www.slideshare.net
CW EventsのARN別に起動/停止処理を振り分ける以下の方法は冴えてるが、この場合実行はセキュアだがその分テストがしにくい(ARNの偽装はできないので)ことになる点は注意しておきたい。
ex. EBS/AMIの自動バックアップ
- 目的:EBSやAMIのように自動的にバックアップが取られないが、中にデータを持っており復元ポイントとしてのバックアップを作成しておく必要が有る場合に自動取得されるようにしておく。
- 実装:EC2インスタンスの自動起動・停止とほぼ同じでできる。(実行対象のAPIが違うくらい)
ex. STNSを使ったOSユーザー管理
- 目的:サーバーのユーザー管理の簡易化
- 説明:サーバー管理用のOSユーザーをADやLDAPと連携することで、退職時などにAD上のユーザーとともに消すことができる
- 実装:DynamoDBで管理するアカウント情報を使い、STNSクライアント(サーバー上)のユーザーアカウントを管理する
その他
CloudTrailやInspectorなどのログを定期分析し、アラームするタスク、Elasticsearchへの画像などの検索データのインデクシングなどに活用できるのではないでしょうか。
【3】ストリームデータ処理
クリックストリームやアプリケーションログの収集&ロード
- Webアプリケーションのページ遷移履歴やWeb APIのログをKinesis StreamやFirehoseを経由してRedshiftやS3, Elasticsearch Serviceにロードします。Kinesis FirehoseはRedshiftなどに直接ロードすることもできますし、Lambdaを呼び出すこともできるので、特定の行を無視したり、データ形式を変換(Apacheのログ形式からJSONなどに変換)したり、DynamoDBなどにロードする処理も実装可能です。マスター表を使ったデータの展開などが必要な場合はイベントドリブンな連携はできませんが、Kinesis Streamでデータを受けカスタムアプリケーションを作成してデータ変換をすることもできます。
【4】モバイル・IoT
Mobile 2-Tier Architecture
- モバイルアプリケーションから直接認証トークンを持ってクラウド上のサービスを利用することで、サーバーレスな実装ができます。体験の向上のためにサーバー側のデータのフェッチを非同期にするためのデータベースをアプリ内に持つソリューション(SQLite、Realm)を利用することも有効です。
モバイルユーザー向けのコンテンツ生成
- 上記と似ていますが、ユーザーのデータの読み書きだけでなく、ランキング処理などバックエンドでのデータ集計バッチ処理をLambdaを用いて作成してレポート用のデータとして保存しておくことが可能です。さらにバッチでデータを定期的に作るのではなく、Redshift Spectrumを用いてS3にリアルタイムに保存されるFACTデータ(トランザクションデータ)とディメンジョン(マスターデータ)とJOINするクエリをオンデマンドに実行可能なので、API Gatewayを通じてLambdaでリアルタイムにクエリ実行して結果を返すようなAPIにしておくことも可能です(これは上で示した Web API のパターンになりますが)
Edge Computing
- 目的:CDNエッジにおいて同一URLでA/Bテストのために一定の重み付けで別のオリジンにルートしたり、ヘッダでCookie判定をしてリダイレクトしたりする。
- 実装:Lambda@Edgeを使い、CloudFrontのディストリビューションにトリガーの種別(クライアントからのリクエスト時、オリジンへのリクエスト時、オリジンからのレスポンス時、クライアントへのレスポンス時)とともにLambda関数を紐付ける。
実行環境にはメモリ128MB、実行時間50ms以内という制約があるのでファットな実装はできない。
IoTアプリケーション
- 目的:IoTデバイスから上がる生データすべてをクラウドに集約することが非効率であるためGatewayデバイス上でデータを加工することで、データのフィルタリングや整形、通信タイミングの断続化による通信料や消費電力の節約をしたい。また、Gateway配下のデバイス群のイベントへの対応(障害検知、デバイス間の同期など)をローカルで行うことでクラウドとのインターネット接続状態に左右されない制御を搭載したい。
- 実装:Gatewayデバイス上にAWS Greengrassを搭載し、AWS IoT Device SDKが搭載されているIoTデバイスをグループ化して管理する。
【5】アプリケーション連携
最後はAlexaやChatbotアプリです。インタフェースは別モノ(Alexaは音声認識、ChatbotはChatアプリケーション上)ですが、
Alexaアプリ
- 目的:音声認識でアプリケーションを実行する
- 実装:Alexa Skills Kitを用いてAmazon上に音声認識のインタラクションの定義と、ビジネスロジック(Lambda)をホストする。
Amazon Echoで稼働するアプリケーションは、Amazon の Developer Portal から新規アプリ作成し、音声認識のパターンや構造を定義したら、LambdaのARNを指定してロジックとの紐づけを行い、パブリッシュする。ここで指定するLambdaで外部APIとの連携や、独自の処理を行うことができます。
また、現在は音声のインタラクションの設計についてβ版ですが Skill Builder というのを使って画面から指定していくことができます。
また、最近はAlexaの音声認識エンジンがAlexa以外でも使えるAmazon Lexというサービスもローンチしています。
Chat Botアプリ
FBアプリでメッセンジャー上に生息するBotを作成し、API Gateway経由でLambdaのビジネスロジックを動かすなど行うことで、バックエンドの処理をチャットのインタフェースを通じて実行できるアプリケーションが流行っています。
FBメッセンジャー以外でも、SlackやTelegramなどのチャットを通じてBotに作業を依頼することができ、上記Alexaアプリ同様、テキスト分析をして適切な情報を返したり、外部APIを実行したりということができます。
ちなみにAWSでは今年もBot Challemngeを開催しており、今年はLexも使ってBotを作ろうということみたいです。
AWS チャットボットチャレンジを開催 – Amazon Lex と AWS Lambda を使用した対話式でインテリジェントなチャットボットを作成 | Amazon Web Services ブログ
AWSに限らず、たとえばMySQL CasualコミュニティではAzure Functions上にデプロイして、Microsoft Translatorで投稿内容を日本語から英語に翻訳して英語での投稿を促すというBotがSlack上にいるそうです。
まとめ
- サーバーレスはプラットフォーム事業者がホストのサーバー運用をやってくれるうえでのベストプラクティスに乗っかってコードを実行するアプローチです。多少の制約があってもベストプラクティスに乗って可用性やスケーラビリティの運用品質をプラットフォームに頼るか、あるいは自分たちですべて担保すべきかの判断は組織の構成によりさまざまです。それにしても我々がこの先たくさんのサービスを作成して、ビジネスロジックを書いて、周辺システムと連携していく場合において、少人数で素早く開発と運用を行っていくうえでとても強力なツールになるのは間違いないでしょう。
- 今回はユースケースの提示と実装内容などにそれぞれのケースでさらっと触れているものからそれなりの実装を提示しているものまで結構開きがあったので、今後はそれぞれのユースケースに対する実装内容やつまづきどころなどを1つ1つ深掘りしてみたいと思います。