コンピューターが賢くなって、人間がやる仕事が減るといいなと思っているkitabatakeです。 今流行りのニューラルネットワークについて説明したいと思います。
ニューラルネットワークとは
脳神経系をモデルにした情報処理システムで、
文字認識や、音声認識など、コンピュータが苦手とされている処理に対して有効です。
脳の中には多数のニューロン(神経細胞)が存在していて、 各ニューロンは多数の他のニューロンから信号を受け取り、他の多数のニューロンへ信号を受け渡していて、 信号の伝搬によって、様々な情報処理を行っています。
こういった脳内の情報処理の仕組みを真似することで、複雑な情報処理を行おうというものです。
神経細胞の仕組み
神経細胞は下記の画像になっています。

ニューラルネットワーク入門 1.1 神経細胞より参照 http://www-ailab.elcom.nitech.ac.jp/lecture/neuro/neuro1.html
樹状突起 ニューロンへの入力端子
軸索 ニューロンの出力端子
シナプス ニューロン間を繋ぐ役割. 軸索から他のニューロンの樹状突起を通して伝達される
入力信号が加わると電位があがりはじめ、 閾値を超えると一時的にニューロンの電位が急激にあがり、シナプスを通じて結合しているニューロンへ出力されます(ニューロンが発火すると表現される)
ニューロンの発火イメージ

ニューロンの概要とそのモデル より参照 http://kazoo04.hatenablog.com/entry/agi-ac-3
こういったニューロンの仕組みをモデル化すると

ニューラルネットワーク入門 1.2 ニューロンモデルより参照 http://www-ailab.elcom.nitech.ac.jp/lecture/neuro/neuro1.html
ニューロンは入力端子ごとにその入力の重要性を表す結合荷重があり、発火のしやすさを表す閾値を持っていて、 閾値を超えると出力端子から出力信号が出力されるようにモデリングできます。
このニューロンモデルの出力と入力を複雑に連携させて、ネットワーク化することで、複雑な情報処理が可能になります。
階層型ネットワークモデル
ネットワークモデルの1例で、入力層と出力層があり、その間に中間層があります。 ある層のニューロンは前の全てのニューロンからの出力を受け取り、次の層の全てのニューロンに対して出力を行います。

画像処理・理解研究室 第5章 ネットワークの形態についてから参照 http://ipr20.cs.ehime-u.ac.jp/column/neural/chapter5.html
実装に入ります
上記で説明したニューロンモデルとネットワークモデルを実装に落とし込んでみたいと思います。
まずは単純パーセプトロン
パーセプトロンとは1957年に考案されたニューロンモデルで、入力層と出力層のみの2層からなるものが単純パーセプトロンと呼ばれます。

rubyで単純パーセプトロンより参照 http://ogidow.hateblo.jp/entry/2016/06/24/184801
各入力ごとに重みと閾値を持ち、入力値 * 重みの総和が閾値を超えると 1 超えないと 0 が出力されます。
重みにマイナスを掛けたものをバイアスと表し、常に入力値が1の入力と考えることで、ニューロンの発火条件をシンプルに表現することができます。

機械学習ざっくりまとめ~パーセプトロンからディープラーニングまで~ から参照 http://qiita.com/frost_star/items/21de02ce0d77a156f53d
b + x1 * w1 + x2 * w2 が 0以上であれば発火というように表現できるようになります。
ではパーセプトロンでシンプルな回路を実装してみましょう
OR回路とAND回路を考えてみると、OR回路は発火しやすい(どちらかの入力が1であれば発火)もので、 AND回路は発火しにくい(両方の入力が1で発火)ものと考えることができ、そのようにバイアスと重みを設定すると実現できます。
例えば、
OR回路: バイアス: -1, 重み1: 2, 重み3
AND回路: バイアス: -1, 重み1: 0.5, 重み2: 0.5
と表現できます。
NAND回路はAND回路の設定値を全て正負を反転すると表現できます。
単純パーセプトロンの限界
XOR回路を考えると単純パーセプトロンでは表せないことが解ります。 2つの入力どちらも1の場合に発火しないという条件は表現できません。
そこで多層化
XOR回路は、OR回路とNAND回路をANDにつなげることで表せるので、パーセプトロンを多層化することで表現できます。
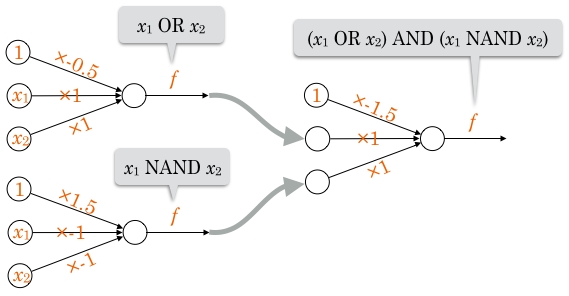
高卒でもわかる機械学習 (3) 多層パーセプトロン より参照 http://hokuts.com/2015/12/04/ml3-mlp/
コンピュータはNAND回路の組み合わせでできているということで、パーセプトロンを多層化していくことで、かなり複雑な情報処理が行えると言えると思います。
次に活性化関数
今まで見てきたパーセプトロンでは、バイアス + 入力値 * 重みの総和の入力に対して、1か0を出力するという考えでした。 この入力から出力を生成する関数が活性化関数を呼ばれます。
パーセプトロンのような1か0で出力するものはステップ関数と呼ばれています。
ステップ関数とは別によく使われている活性化関数として、シグモイド関数というものがあります。

wikipediaより参照 https://ja.wikipedia.org/wiki/%E3%82%B7%E3%82%B0%E3%83%A2%E3%82%A4%E3%83%89%E9%96%A2%E6%95%B0
ステップ関数とは違い、0から1の間の値に収まる形で多様な値が出力されます。 シグモイド関数のこの特性は入力値の細かい調整が出力に反映されるということになるので、バイアス、重みの細かい調整(学習)に都合がいいということで、 一般的にこちらの方が使用されているようです。
シグモイド関数を活性関数に使用したニューロンをシグモイドニューロンと呼ぶことがあるようです。
手書き数字の認識
今までの知識をもとに手書き数字を認識するニューラルネットワークを実装してみたいと思います。
こちらの本が提供している学習データ、コードをベースに見ていきたいと思います。
MNISTとは
MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
MNISTとは6万の手書き数字の学習用画像と、1万のテスト用画像を提供しているサービスで、python用に画像を取得するライブラリも提供されています。 MNISTから取得した学習用画像で学習したデータをもとに、テスト画像の予測の精度を出力するプログラムを見ていきたいと思います。
ネットワークの設計
MNISTの画像は 28px * 28px の画像なので、入力層のニューロンの数としては、784となり、 出力層は各数字の確率なので、0 - 9 までの個数で、10となります。
中間層は2層で、100, 50 とします。 この辺りは学習方法をまだ理解していないので、この設定する意味は理解できていないのですが、結構複雑なニューラルネットワークになっていると思います。
プログラム
配列の計算を簡単に行うために、numpy.array を使用しています。
ゼロから作るDeep Learning で提供されているコードにコメントを追加したものです。
import sys, os, pickle sys.path.append(os.pardir) from dataset.mnist import load_mnist from common.functions import sigmoid, softmax import numpy as np # MNISTの学習用データとテスト用データを取得する def get_data(): (x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False) # *_trainが学習用のデータで、*_testがテスト用のデータです # 今回はテスト用のデータしか使いません # x_testがテスト用の画像データで、t_testがテスト用画像に対応した答えの数値です return x_test, t_test # 学習済みのネットワーク(バイアスと重み)のデータを取得する def init_network(): with open('sample_weight.pkl', 'rb') as f: network = pickle.load(f) return network # ネットワークと入力(画像データ)から数字の予測を行う def predict(network, x): W1, W2, W3 = network['W1'], network['W2'], network['W3'] b1, b2, b3 = network['b1'], network['b2'], network['b3'] # 各層の各ニューロンへの入力値の計算(入力 * 重み + バイアス)したものをシグモイド関数に通しています。 a1 = np.dot(x, W1) + b1 z1 = sigmoid(a1) a2 = np.dot(z1, W2) + b2 z2 = sigmoid(a2) a3 = np.dot(z2, W3) + b3 # 最終的に出来上がるデータは出力層の長さが10の配列で、keyが対象数字でvalueがその数字である確率が入っています return a3 x, t = get_data() network = init_network() # 正答率の計算 accuracy_cnt = 0 for i in range(len(x)): y = predict(network, x[i]) p = np.argmax(y) # 確率が一番高いものがニューラルネットワークが予測した数字で、 if p == t[i]: accuracy_cnt += 1 # 予測した数値と提供されている答えが一致していると、正解数をインクリメントします print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
これを実行すると
Accuracy:0.9352 と出力されます。
MNISTのテスト用画像は人間が見ても判別が難しい画像も含まれているので、結構高い精度が出ていると言えると思います。
次は学習アルゴリズムを勉強したいと思います!