
Richard Feldman
Author of Elm in Action.
People often ask me if I can point them to an open-source Elm Single Page Application so they can peruse its code.
Ilias van Peer linked me to the Realworld project, which seemed perfect for this. They provide a back-end API, static markup, styles, and a spec, and you build a SPA front-end for it using your technology of choice.
Here's the result. I had a ton of fun building it!
4,000 lines of delicious Elm single page application goodness 😋
Fair warning: This is not a gentle introduction to Elm. I built this to be something I'd like to maintain, and did not hold back. This is how I'd build this application with the full power of Elm at my fingertips.
If you're looking for a less drink-from-the-firehose introduction to Elm, I can recommend a book, a video tutorial, and of course the Official Guide.
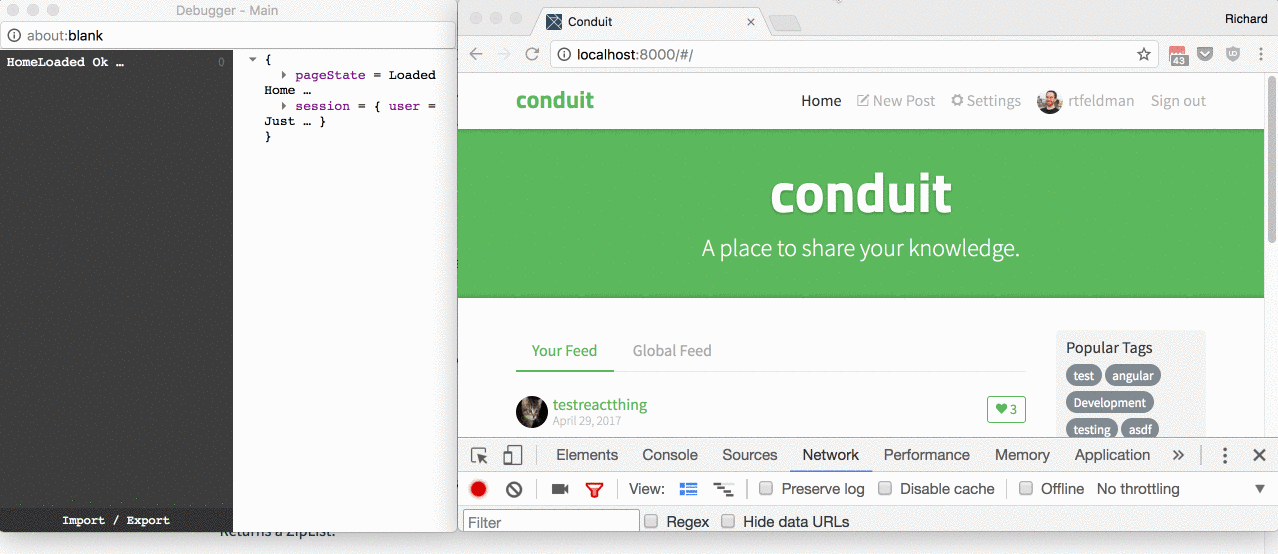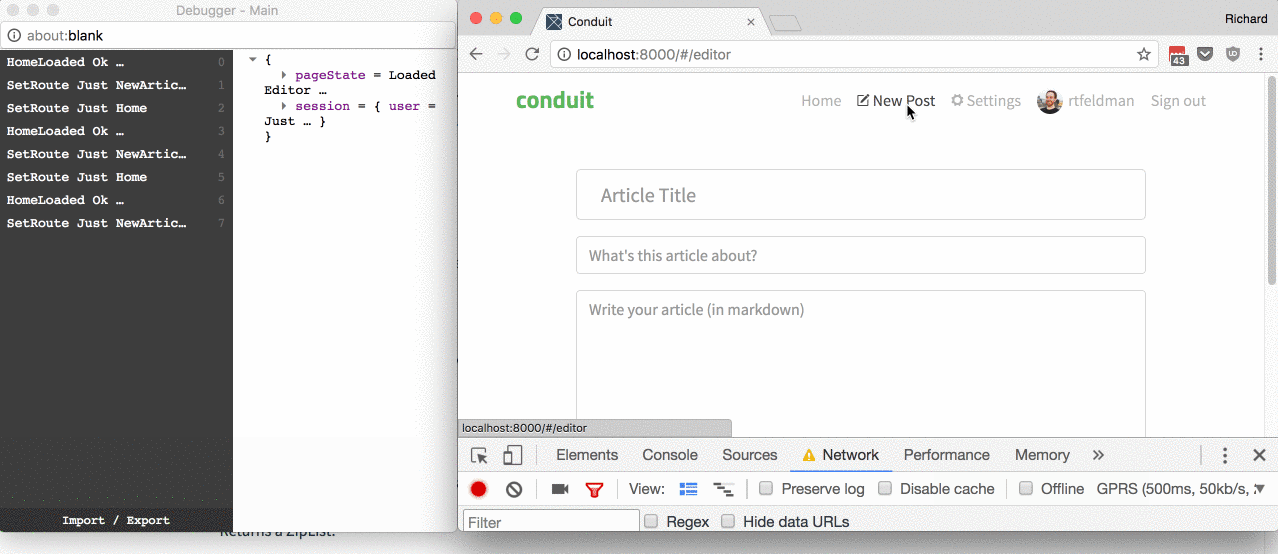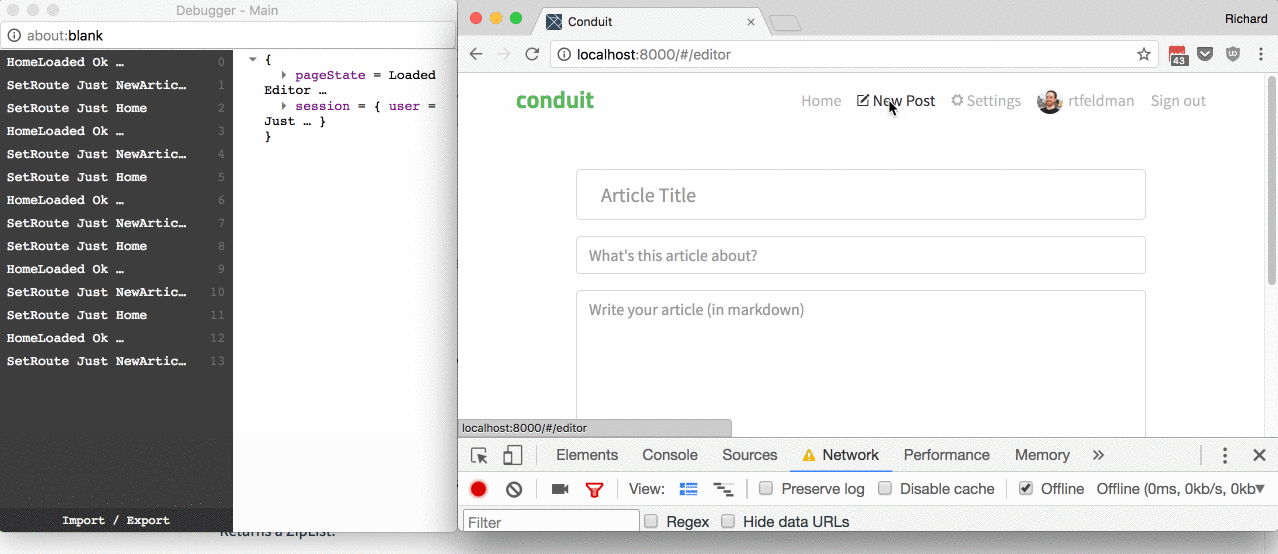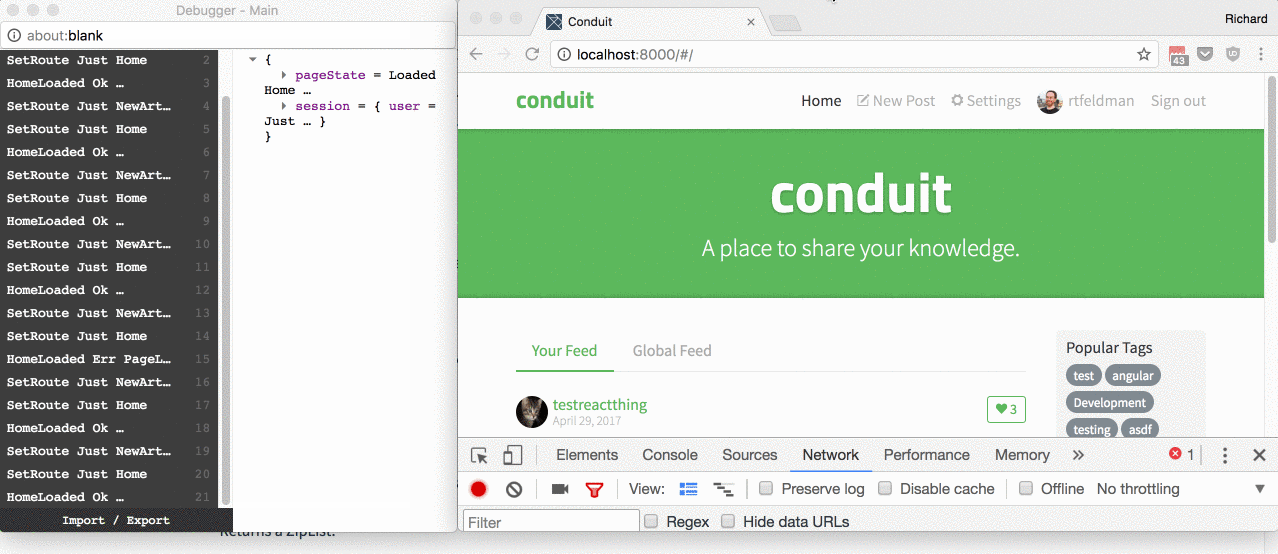
I went with a routing design that optimizes for user experience. I considered three use cases, illustrated in this gif:
The use cases:
On fast connections, I want users to transition from one page to another seamlessly, without seeing a flash of a partially-loaded page in between.
To accomplish this, I had each page expose init : Task PageLoadError Model. When the router receives a request to transition to a new page, it doesn't transition immediately; instead, it first calls Task.attempt on this init task to fetch the data the new page needs.
If the task fails, the resulting PageLoadError tells the router what error message to show the user. If the task succeeds, the resulting Model serves as the initial model necessary to render 100% of the new page right away.
No flash of partially-loaded page necessary!
On slow connections, I want users to see a loading spinner, to reassure them that there's something happening even though it's taking a bit.
To do this, I'm rendering a loading spinner in the header as soon as the user attempts to transition to a new page. It stays there while the Task is in-flight, and then as soon as it resolves (either to the new page or to an error page), the spinner goes away.
For a bit of polish, I prevented the spinner from flashing into view on fast connections by adding a CSS animation-delay to the spinner's animation. This meant I could add it to the DOM as soon as the user clicked the link to transition (and remove it again once the destination page rendered), but the spinner would not become visible to the user unless a few hundred milliseconds of delay had elapsed in between.
I'd like at least some things to work while the user is offline.
I didn't go as far as to use Service Worker (or for that matter App Cache, for those of us who went down that bumpy road), but I did want users to be able to visit pages like New Post which could be loaded without fetching data from the network.
For them, init returned a Model instead of a Task PageLoadError Model. That was all it took.
We have over 100,000 lines of Elm code in production at NoRedInk, and we've learned a lot along the way! (We don't have a SPA, so our routing logic lives on the server, but the rest is the same.) Naturally every application is different, but I've been really happy with how well our code base has scaled, so I drew on our organizational scheme when building this app.
Keep in mind that although using exposing to create guarantees by restricting what modules expose is an important technique (which I used often here), the actual file structure is a lot less important. Remember, if you change your mind and want to rename some files or shift directories around, Elm's compiler will have your back. It'll be okay!
Here's how I organized this application's modules.
Page.* modulesExamples: Page.Home, Page.Article, Page.Article.Editor
These modules hold the logic for the individual pages in the app.
Pages that require data from the server expose an init function, which returns a Task responsible for loading that data. This lets the routing system wait for a page's data to finish loading before switching to it.
Views.* modulesExamples: Views.Form, Views.Errors, Views.User.Follow
These modules hold reusable views which multiple Page modules import.
Some, like Views.User, are very simple. Others, like Views.Article.Feed, are very complex. Each exposes an appropriate API for its particular requirements.
The Views.Page module exposes a frame function which wraps each page in a header and footer.
Data.* modulesExamples: Data.User, Data.Article, Data.Article.Comment
These modules describe common data structures, and expose ways to translate them
into other data structures. Data.User describes a User, as well as the
encoders and decoders that serialize and deserialize a User to and from JSON.
Identifiers such as CommentId, Username, and Slug - which are used to
uniquely identify comments, users, and articles, respectively - are implemented
as union types. If we used e.g. type alias Username = String, we could mistakenly pass a Username to an API call expecting a Slug, and it would still compile. We can rule bugs like that out by implementing identifiers as union types.
Request.* modulesExamples: Request.User, Request.Article, Request.Article.Comments
These modules expose functions to make HTTP requests to the app server. They expose Http.Request values so that callers can combine them together, for example on pages which need to hit multiple endpoints to load all their data.
I don't use raw API endpoint URL strings anywhere outside these modules. Only Request.* modules should know about actual endpoint URLs.
Route moduleThis exposes functions to translate URLs in the browser's Location bar to
logical "pages" in the application, as well as functions to effect Location
bar changes.
Similarly to how Request modules never expose raw API URL strings, this
module never exposes raw Location bar URL strings either. Instead it exposes
a union type called Route which callers use to specify which page they want.
Ports moduleCentralizing all the ports in one port module makes it easier to keep track
of them. Most large applications end up with more than just two ports, but
in this application I only wanted two. See index.html for the 10 lines of JavaScript code they connect to.
At NoRedInk our policy for both ports and flags is to use Value to type any values coming in from JavaScript, and decode them in Elm. This way we have full control over how to deal with any surprises in the data. I followed that policy here.
Main moduleThis kicks everything off, and calls Cmd.map and Html.map on the various
Page modules to switch between them.
In Elm 0.19, most of this file should become unnecessary thanks to some new asset management language features.
Util moduleThese are miscellaneous helpers that are used in several other modules.
It might be more honest to call this Misc.elm. 😅
elm-css to style it. However, since Realworld provided so much markup, I ended up using html-to-elm to save myself a bunch of time instead.elm-test in progress, and I'd like to use the latest and greatest for tests. I debated waiting until the new elm-test landed to publish this, but decided that even in its untested form it would be a useful resource.I hope this has been useful to you!
And now, back to writing another chapter of Elm in Action. 😉
This is so amazing, Richard.
Awesome! And you wrote the whole thing in 5 hours!
This is very informative. I think this definitely deserves a mention on Elm roadmap under "How do I make a single page app".
Great Job.
haha I didn't actually write the whole thing in 5 hours 😄 - I just didn't want to publish it until it was done, so I developed it locally and then copied everything over at the last minute after creating the repo. 😉
(It actually took closer to a week.)
This is awesome Richard. Especially your setup with variations for fast-slow-no connection with Task is great. Thanks for sharing!
Really great article. This is really inspiring and you had some very fine solutions to some potentially hard problems. Good job.
Thanks for the nice example, I'm borrowing some ideas for my open source Elm SPA I'm developing as I'm still a Elm newbie.
But I'm wondering about the use of Task,map instead of Cmd.batch, it seems that causes all requests to be done in sequence instead of in parallel. For example the list of articles and the list of tags are loaded after each other instead of in parallel. Is there anyway to fix that and keep using Tasks?
Not yet, but I expect there will be something in
Httpto parallelize HTTP requests in the future.Since it's just a performance optimization and performance is fine as-is, I thought it'd be prematurely optimization to go out of my way to use
Cmd.batchinstead, but in a world where I can parallelize viaHttpI'd reach for that instead ofTask.map2assuming it would be an easy upgrade. :)Thanks for posting this. I am currently working on an SPA, and I have run into scaling problems with my update function and model. Your example shows exactly how to split update and the model across pages, and how to solve some other problems I have seen. This is the example needed to go past the good but simple intro material and to a real application.
This is great.
I was thinking about doing the init thing for pages that return a task, but I was a bit stuck because I use remotedata, and it's
sendRequestwrapper.Thank you very much
You, sir, are a gem!
Can't wait for the tests :)
This is badass, 🙏
Great article & great job!