John Hattie developed a way of ranking various influences in different meta-analyses related to learning and achievement according to their effect sizes. In his ground-breaking study “Visible Learning” he ranked 138 influences that are related to learning outcomes from very positive effects to very negative effects. Hattie found that the average effect size of all the interventions he studied was 0.40. Therefore he decided to judge the success of influences relative to this ‘hinge point’, in order to find an answer to the question “What works best in education?”
Hattie studied six areas that contribute to learning: the student, the home, the school, the curricula, the teacher, and teaching and learning approaches. But Hattie did not only provide a list of the relative effects of different influences on student achievement. He also tells the story underlying the data. He found that the key to making a difference was making teaching and learning visible. He further explained this story in his book “Visible learning for teachers“.
John Hattie updated his list of 138 effects to 150 effects in Visible Learning for Teachers (2011), and more recently to a list of 195 effects in The Applicability of Visible Learning to Higher Education (2015). His research is now based on nearly 1200 meta-analyses – up from the 800 when Visible Learning came out in 2009. According to Hattie the story underlying the data has hardly changed over time even though some effect sizes were updated and we have some new entries at the top, at the middle, and at the end of the list.
Below you can find an updated version of our first visualization of effect sizes related to student achievement. You can compare the entries from Visible Learning (red), Visible Learning for Teachers (green) and Hattie 2015 (blue). Hattie constantly updates this list with more meta studies. Here is a backup of our first visualisation of 138 effects.
Hattie Ranking of Effect Sizes
Click on the image for an interactive visualization of the effect size lists.

Diagram by Sebastian Waack, founder of Edkimo.
Follow me on Twitter. Always happy to talk!
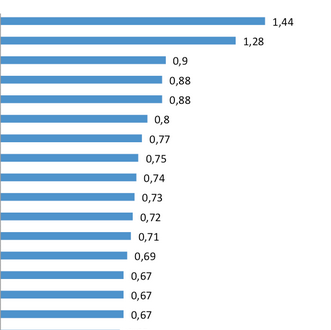
Hi there – thanks for sharing the graphic – not sure if someone has already pointed out to you the error. You have “Classroom Behavioural” with an effect size of 0.8
I was looking for Classroom Discussion and assume you must have got those mixed up. Classroom Behavioural has an effect size of only 0.62.
Hope this helps with a revision of the graphic – cheers
Hi Tom,
Thanks for pointing that out! I double checked the issue with Hattie’s two books about “Visible Learning”.
The list I visualized for this website is related to Hattie (2009) Visible Learning.
Hattie constantly updates his list with more meta studies. I suggest that your comment relates to an updated list in Hattie (2011) Visible Learning for Teachers?
Cheers, Sebastian
Can someone help me please? I have seen many different tables of Hattie’s effect sizes and the order and effect size seems to differ quite significantly between them. Why is this? I am trying to use them for an evaluative model and I am confused as to which order and effect size I should use.
With thanks for any clarification you can offer.
Hi Clare,
As Hattie has updated the ranking in his newer books I would recommend to use the latest version of the list in “Visible Learning for Teachers” which cites over 900 meta studies.
Could you please explain the negative probabilities in the work that I’ve read about here:
https://ollieorange2.wordpress.com/2014/08/25/people-who-think-probabilities-can-be-negative-shouldnt-write-books-on-statistics/comment-page-1/#comment-545
Hello,
the CLE calculations have been wrong in earlier editions of Visibible Learning. The Common Language Effect Size (CLE) is a probability measure and by definition must be between 0% and 100%. This error has been corrected in newer editions and translations of the book. From the very beginning the story of Visible Learning is mainly based on the effect size (Cohen’s d) which are correct.
Here’s what John Hattie says about about it: “At the last minute in editing I substituted the wrong column of data into the CLE column and did not pick up this error; I regret this omission. In each subsequent edition the references to CLE and their estimates will be dropped – with no loss to the story.” http://leadershipacademy.wiki.inghamisd.org/file/view/Corrections%20in%20VL2.pdf/548965844/Corrections%20in%20VL2.pdf
That is not the main issue. The bigger problem is conceptual. For example, ‘instructional strategies’ is not a strategy … no more than vehicle is a specific vehicle. A child’s wagon, a wheelbarrow, a half ton truck, a five ton truck are vehicles. If we used ‘vehicles’ to move gravel from point A to point B … and we calculated an effect size on vehicles … we suffer from ‘regression towards the mean’; the child’s wagon will look more powerful than it is (a higher effect size) and the 5 ton truck will look worse (a lower effect size). The same issue is with Cooperative Learning. Cooperative learning is a label for a belief system about how students learn; it has approximately 200 group structures that go from simple to complex (Numbered Heads to Think Pair Share to Jigsaw to Group Investigation). To provide an effect size for cooperative learning is imprecise … same problem …. regression towards the mean.
Also, Concept Mapping (Joseph Novak’s work) is an example of an instructional strategy … he wisely does not provide an effect size for ‘graphic organizers’ — because graphic organizers is not a specific instructional method (that would included, flow charts, ranking ladders, Venn diagrams, Fishbone diagrams, Mind Maps and Concept Maps).
For a ‘drug’ example, imagine calculating the effect size for 10 mg, 50 mg., 100 mg., and 150 mg of that drug … then averaging them to tell people that this ‘pain medicine’ has an effect size of say .58. Clearly, that is imprecise. cheers, bbb
I am looking at this graph and am curious as to what age group this study was done on when it comes to education.
Dear Erica,
in an interview John Hattie explains: “I was interested in 4-20 year olds and for every influence was very keen to evaluate any moderators – but found very few indeed. The story underlying the data seems applicable to this age range.”
Best wishes,
Sebastian
http://visible-learning.org/2013/01/john-hattie-visible-learning-interview/
Hi,
I’ve been reading a book called Spark, by John Ratey. In it, he argues that cardio exercise has a large influence on student success. Does anyone know where this might fit into Hattie’s effects, or any related studies?
I note that peer tutoring has a 0.55 effect but mentoring which Hattie states is a form of peer tutoring has a 0.15 effect. How can there be this level of difference? One could assume from this that mentoring is not a particularly worthwhile investment but there would be few people who have achieved eminence in their fields who were not heavily influenced by a mentor.
“Peer mentoring” is a specific kind of program. Likewise, I’m guessing Hattie’s “mentoring” isn’t what you have in mind. If you look at mentoring programs, it’s not like having a single brilliant individual who intimately guides you throughout a period of life. This is very hard to do well in the broader school system. You need way too many mentors to be practical, not to mention paying them and matching them up. Also, not all students respond well. Great people have generally relied on and responded to mentors in their development. But try fixing up a typical student with a typical mentor, and you’ll see it hard to predict the outcome.
Hello, I am about to buy the book but I wondered if someone could just quickly fill me in here on what statistic is being used to represent the effect size, e.g. r or r^2 or z? Thanks.
Hello Daniel,
Hattie uses Cohen’s d to represent the effect size. Cohen’s d is defined as the difference between two means divided by a standard deviation of the pooled groups or of the control group alone.
Cheers, Sebastian
So in a group with a large standard deviation (e.g wide range of abilities) the effect size for the same improvement in mean always looks smaller than a group with a smaller standard deviation (lower range of abilities)? Hardly seems a valid tool for comparison..
Hello Mark,
effect size d isn’t a perfect measure (that doesn’t exist) but it’s a good and practical approach to compare different sample sizes. Moreover, taking into account the standard deviation helps to better interpret mean differences. Taking your example of a large standard deviation before the intervention (e.g. wide range of abilities): imagine an intervention that results in only a small mean difference. Maybe your intervention has a large effect size d if you manage to bring the group of learners together and lower the standard deviation.
OK. I am not a statistician but I have some questions about Hattie’s explanation as to how publication bias does not affect his results. You can find the questions here:
https://sites.google.com/a/lsnepal.com/hattie-funnel-plot/
Hi Brad,
I found this paper with a more detailed funnel plot. It’s a follow-up on Hattie’s “reading methods”:
http://ivysherman.weebly.com/uploads/1/7/4/2/17421639/post_-_edd_1007_final_paper_pr.pdf
Comprehensive school entry screening is not specifically mentioned
by Prof. John Hattie. However certain elements are:
Feedback, Evaluation, Classroom Behaviour, Interventions for
the Learning Disabled, Prior Achievement, Home Environment, Early Intervention, Parent Involvement, Preterm Birth Weight, Reducing Anxiety, SES. But others are missing eg. The division of Behaviour into Internal and External, the effects of below average Speech-Language level, Resilience, etc.
The validity of the 20 years research on Parent, Teacher and Child-based school entry screening is contained in Reddington & Wheeldon (2009)which can be sent to Prof. Hattie (also presented at the International Conference on Applied Psychology, Paris, July, 2014).
Prof. Hattie’s hierarchies are an extremely helpful guide, and checklist, against which to compare the Parent, Teacher and Child based items of the school entry screening system.
I purchased the Visible Learning book and appreciate the ranking and effect sizes.
Although, there isnt a place anywhere in the book where the intervention labels are explained in detail.
For instance, what does Piagetian programs mean; what do creativity programs entail; how are repeated reading programs executed?
Is there a way I can find out more information on what the labels mean to John Hattie?
This might be of some help: http://visible-learning.org/glossary/#2_Piagetian_programs
The explanation in this link is backed up with another link – that second link is to an abstract about a study that compared Piagettian test with IQ tests so see was the better predictor of school performance. It is not very surprising that Piagetian tests were better predictors (since these correspond to school tasks more closely than those of IQ tests).
The main problem for me is that the study does not deal with ‘Piagetian programs’ (sic) just a test. I am struggling to find an endorsement of ‘Piagetian programs’, though I can find plenty of studies that points out gaps in Piaget’s approach – including Piaget’s own admission (late in life, but all the more creditworthy to acknowledge at that stage) that he was wrong about language being secondary to learning.
Where are these studies that show strong effect sizes for Piagetian programmes?
Hi Mr. Hattie,
How was your ranking calculated mathematically?
Do you use the data from visible learning to make your calculations?
Would you take video submissions to run through your visible learning process complete with transcripts and data analysis?
Is there a charge for visible learning?
How long does it take to get feedback?
I’m fascinated by the idea that you are quantifying teaching strategies and want to better understand the process.
Thanks,
Kendra Henry
Here are some thoughts on Hatties use of statistics mathematically http://literacyinleafstrewn.blogspot.no/2012/12/can-we-trust-educational-research_20.html
…and here https://ollieorange2.wordpress.com/2014/08/25/people-who-think-probabilities-can-be-negative-shouldnt-write-books-on-statistics/
Hello GL,
Thank you for the links discussing the issues related to Hattie’s use of CLE.
The CLE calculations have been wrong in earlier editions of Visible Learning. The Common Language Effect Size (CLE) is a probability measure and by definition must be between 0% and 100%. This error has been corrected in newer editions and translations of the book. From the very beginning the story of Visible Learning is mainly based on the effect size (Cohen’s d) which are correct.
Here’s what John Hattie says about about it: “At the last minute in editing I substituted the wrong column of data into the CLE column and did not pick up this error; I regret this omission. In each subsequent edition the references to CLE and their estimates will be dropped – with no loss to the story.” http://leadershipacademy.wiki.inghamisd.org/file/view/Corrections%20in%20VL2.pdf/548965844/Corrections%20in%20VL2.pdf
Best wishes, Sebastian
Dear Kendra,
For transcripts and data analysis you might check out the Visible Classroom project: http://visibleclassroom.com
For a better understanding of the process I would recommend reading the book “Visible Learning for Teachers”.
Best wishes, Sebastian
Hi Mr. Hattie,
Is it possible to get access to your powerpoint?
Thanks,
Kendra Henry
Well, I (stupidly) rented a Kindle version of the VL for Teachers that your link led me to on Amazon. I am trying to learn precisely what is meant by the new top two effects. I didn’t notice that it was the 2012 version, which I already own. (Old eyes shouldn’t buy books on a smartphone, I suppose.)
If the 2012 list was the Gold Standard of effect sizes, how is it that the 2015 list is topped by two brand-new effects?
Dear Chuck,
Thanks for your comment! I also think about these two brand new effects since I have visualized the new list. Unfortunately John Hattie gives little detail in his paper from 2015. I found this a short introduction video “Collective teacher efficacy” helpful: https://www.youtube.com/watch?v=FUfEWZGLFZE. And I think this is one of the meta-analysis Hattie relates to: Eels (2011): “Meta-Analysis of the Relationship Between Collective Teacher Efficacy and Student Achivement” http://ecommons.luc.edu/cgi/viewcontent.cgi?article=1132&context=luc_diss
Best regards, Sebastian
It is great to be reading about research from the horses mouth and linking to the practices of our school which our strongly influenced by Hattie
I’m just wondering way diagnotic and remediation programs to overcome students’weaknesses on science concepts and other diciplines has not been included this review. I have working in this area since 1990. one of this work was appears in may Ph D thesis at Monash, 1990. ‘Remediation of weaknesses in physiscs concencepts’.
Regards
Did I miss ‘focus’? To those of us ‘on the front lines’ one of the most important variables in learning is Focus/lack thereof. Add the co-morbidity of anxiety and depression, it effects that student-teacher relationship, contributes to the lack of retention and big picture learning. Focus, and it’s deficit, will impact not only the student, but the home, the school, the curricula, the teacher, and learning approaches..sigh…