はじめに
今回は、機械学習の応用「画像処理」編です。
画像処理という言葉でピンと来ない人もいるかも知れないので、簡単に画像処理について説明します。
画像処理とは、ある画像を処理して、別の画像に変形したり、画像から何らかの情報を取り出すために行われる処理全般のことを言います。
そうはいっても抽象的になりすぎているので、具体的な事例は以下のものがあります。
- ノイズ除去
- 輪郭抽出
- 傾き補正
- 顔認識(Facebookが有名)
- フィルター(Instagramなど)
そのパーツ自体では製品にはならないのが画像処理ですが、機能としては非常に魅力的であり、デジタルカメラといった直接的に関わる分野にとどまらず、FacebookやInstagramといった写真を多用するアプリケーションでも積極的に活用されています。
特に、最近は医療の領域で画像処理が注目を浴びています。
MRIの画像から超微細な癌の部分を人工知能が見つけ出すといった応用例まで出ており、その応用範囲は今後さらに増えていくと予想されます。
食の分野では、Rettyが食べ物の画像からカテゴリーを自動的に分類しているといった技術の話が最近紹介されていました(解説記事はこちら)。
ファッションの画像からカテゴリー分類も同じように考えれば実現することができます。
そして、医療の分野の応用例と食の分野の応用例を見た際に、画像処理+機械学習により実現できることは、大きく以下の2つがあります。
- 画像内から特定の部分を検出(画像内にある顔や癌といった一部分)
- 画像を特定のクラスに分類(画像全体を日本食やイタリアンといったジャンルに分類)
この2つを実現できるようになると、応用範囲は非常に広いと言えます。
そこで、キカガクの「画像処理」編では、この2つを実現するための手順を全て紹介します。
画像処理の基礎
画像処理の数学
そもそも画像とはどのようにこれから数値として扱っていけば良いのでしょうか。
機械学習は万能ですが、前提として数値で扱える必要があります。
まず、基本的にみなさんの考えておられる画像は カラー画像 だと思います。
画像処理の世界では、カラー画像を表現するために、RGB という3つの部分に分けて考えます。
RGB とは Red、Green、Blueの単なる頭文字であり、特に難しいものではありません。
中学校の頃の美術の時間に色の3原則(光)で習ったことを覚えていらっしゃるかも知れませんが、カラーの色は RGB のそれぞれの組み合わせにより、大体の色を表現することができます。
※ RGBのイメージ
そして、各色ごとに ピクセル と呼ばれる画素単位の区切りで色の強さ(厳密には輝度)を表現します。
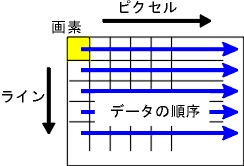
このように各色ごとにピクセル単位で区切ることで画像をコンピュータ内に取り込んで構成することができます。
そして、基本的に画像の色の強さ(以降、輝度)は 0〜255 で値で表現することが多いです。
これをビット数で表現するならば 8bit ($2^{8}=256$ となり、0〜255までの256パターンを表現可能)となります。
※ この表現が曖昧な方は2進法を少し復習してみてください。
例えば、縦5ピクセル(height)×横5ピクセル(width)のカラー画像の場合、以下の画像のように値が格納されることになります。
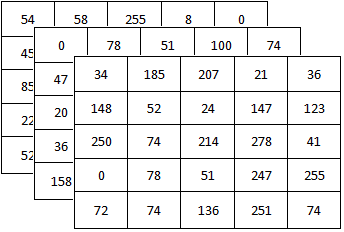
なぜ、3つのあるかは大丈夫ですよね?
それぞれ前から Red、Green、Blue に対応しています。
画像の色を表現する方式には RGB 以外に HSV もありますので、気になった方は調べてみてください。
OpenCV:画像処理の超万能ライブラリ
OpenCV は Python と C++ で提供されている画像処理用のライブラリです。
Rubyなどでもラッパーが提供されており、使用することができます。
Pythonでは、Numpyの形式で扱うことができるため、行列演算としても非常に柔軟に扱うことができます。
OpenCVでよく使うには以下のようなものがあります。
- 2値化:画像のピクセル値を0か1などの2つの値に変換する操作
- エッジ検出:画像からモノの輪郭だけを抽出する操作
- ハフ変換:画像から直線や曲線を抽出する操作
- 傾き補正:ハフ変換で検出した直線を利用して画像内の傾きを補正
- モルフォロジー演算:画像内の幾何学的な構造を解析(ノイズ除去、平滑化、テクスチャ解析)
- ヒストグラム:ピクセル値のヒストグラムを算出し、画像同士の類似度の計算等に使える
- テンプレートマッチング:予め指定した画像との部分一致を検出
- 特徴点抽出:画像中の先の端点や交差点、角を検出
- オプティカルフロー検出:映像の前後のフレームから移っている物体の動きを検出
- 物体追跡:特徴点をもちいて動きのある物体を追跡
- カメラキャリブレーション:カメラに入力される画像の歪みを補正
- 物体検出:映像から人物や顔や眼、車両の特定の部分といった物体を検出
ご覧いただいてわかるように、単なる画像の前処理だけでなく、一機能として十分動作するものがあり、ディープラーニングなどの機械学習を使用する前に、OpenCVだけで希望する機能を実現できないか検討してみることをおすすめします。
そして、OpenCVだけでは実現が難しいとなった場合に、機械学習の前処理としてOpenCVを使用することをおすすめします。
参考書
OpenCVに関しては、リファレンスを見ながら進めていくことがおすすめです。
こちらを一冊持っておくと、OpenCVでできる処理についてざっと知ることができます。
現在、OpenCVの3シリーズが出ておりますが、基礎的な画像処理のアルゴリズムに関しては、上記の書籍がおすすめです。
また、OpenCVに関してはPythonで書かれている本と、C++で書かれている本があるので、気をつけてください。
ソースコード
今回のソースコードはこちらのGitHub上にアップロードしてあるため、ご活用ください。
前処理
今回の授業では、機械学習でカテゴリ分類や部分抽出を行うための前処理を学びます。
機械学習では、入力となる変数(画像など)に対して、出力となる変数(カテゴリなど)の対応付けがされたデータが必須です。
このデータを集められない限りは、いくら機械学習のアルゴリズムを勉強したとしても実用化ができないため、非常に重要な作業となります。
それと同時に、この手作業であり、根気強く行う必要があります。
ひとつひとつ手作業で情報を抽出し、エクセルなどのデータに格納していくこともできますが、せっかくですので、少しでも前処理の作業を楽にできるような簡単なアプリケーションを作ってみましょう。
今回は10枚程度しか画像の前処理を行わないため、ひとつひとつ手作業で情報を抽出するほうが早いと言えますが、将来的には10,000枚以上平気で扱う機械学習の分野で使うことを考えると、こういった前処理のアプリを作るだけでも、解析作業のプロセスを効率化することができます。
分類する画像を準備
まず、画像単位でどのカテゴリに属すかといったカテゴリ分類からやっていきましょう。
今回は非常に単純に考え、画像が黄色カテゴリに属すか、青色カテゴリに属すかを判定してきます。
今回は、以下のような画像を20枚準備したので、GitHubからダウンロードしてください。
黄色カテゴリの画像

青色カテゴリの画像

今回はすごく単純な画像であり、人間の目で見てもひと目でわかりますが、これをイタリアンや日本食といったように考えれば食の分野に応用できますし、ジャケットやボトムスといったように考えればファッションの分野に応用できます。
ラベル付けアプリを作成
それではラベル付けを行うためのアプリケーションを作っていきましょう。
ここで作るアプリケーションに必要な機能は以下のとおりです。
- 画像を読み込み、表示する
- 画像に対応するラベルを入力し、保存する
- 保存したラベルのデータをファイルに出力する
このようにアプリケーションを作る際は、最小限でも必要な機能を書き出しておきましょう。
それでは、各機能の作り方について、ひとつひとつ説明していきます。
画像を読み込み、表示する
ここでは、フォルダの中に入っている画像に対して、読み込みを行い表示し、次の画像に移る操作を行います。
PythonのFlaskを使って、内部の動作を細かく記述していきますが、まず、HTMLのみで画像を表示するだけの大枠を作っていきましょう。
HTMLで画像を表示する
特に凝ったことはしないので、非常にプレーンですが、以下のようにHTMLファイルを作成すれば画像を表示する大枠ができます。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>画像処理の前処理アプリs</title>
</head>
<body>
<h1>画像処理の前処理アプリ</h1>
<img src="images/image01.png">
</body>
</html>
これをGoogle Chromeブラウザで確認してみると、このように表示されます。
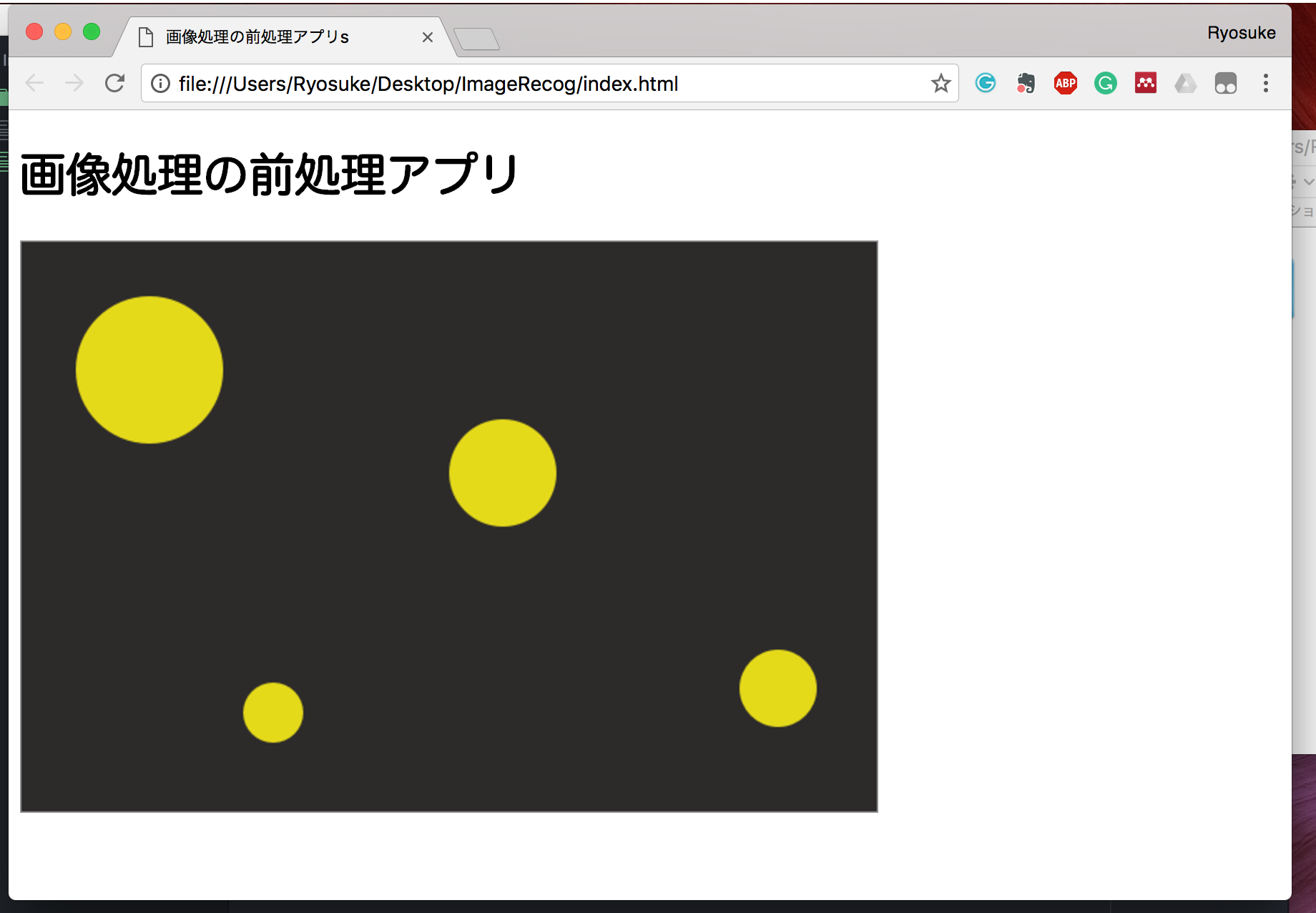
簡単ですが、うまく表示されていますね。
Flaskと連携
さきほどは単純なHTMLファイルのみでしたが、これから操作をDB(データベース)に保存したり、表示する画像ファイルを切り替えたりといったシステム側での操作(サーバーサイドと呼んだりします)があるため、PythonのWebフレームワークであるFlaskを使っていきます。
Python(Flask)とHTMLを連携させるなんて大変じゃないの?と思うかもしれませんが、Flask内でHTMLは表示に専念、Pythonはサーバーサイドに専念といったように、それぞれ極力独立して機能を持つため、そこまで難しくはありません。
まず、Flaskがインストールされていない方は、以下をコマンドで打って Flask をインストールするようにしてください。
$ pip3 install flask
そして、先ほど作成していた index.html を Flask内で扱うために、新しく templates というフォルダ(ディレクトリ)を作成し、そちらに移動しておきましょう。
$ mkdir templates # templatesというディレクトの作成 (mkdir: make directory)
$ mv index.html templates/ # templates内に移動 (mv: move)
$ ls templates # templatesディレクトリ内のファイルを表示して確認
index.html # <- index.html が正しく移動している
そして、Flaskを使ったPythonのWebアプリケーション用のプログラムは以下のようになります。
# coding: utf-8
from flask import Flask
app = Flask(__name__)
@app.route("/")
def index():
return render_template("index.html")
if __name__ == "__main__":
app.run()
これを保存し、以下のコマンドによりローカルのWebサーバーを立ち上げます。
$ python3 app.py
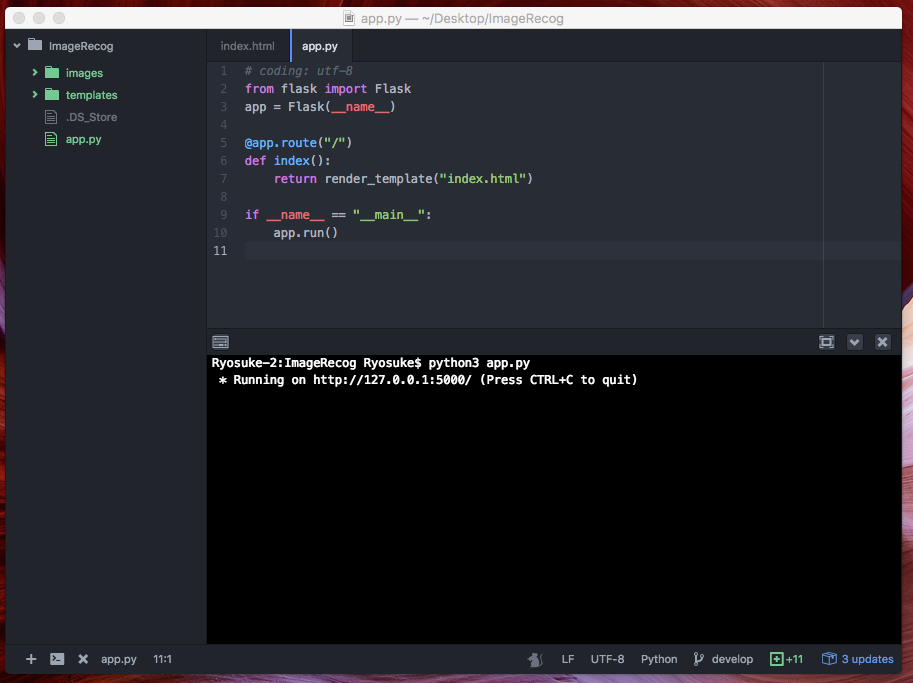
正しく動作すると、上記のように * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) と表示されて、ローカル環境でWebサーバーが立ち上がります。
これは、Webブラウザで http://127.0.0.1:5000/ にアクセスすると、いま開発しているWebアプリにアクセスできるよという意味であり、また、(Press CTRL+C to quit) はWebサーバーを終了したい場合は、このキーを押してねという意味になります。
それでは、http://127.0.0.1:5000/ にGoogle ChromeのWebブラウザでアクセスしてみてください。
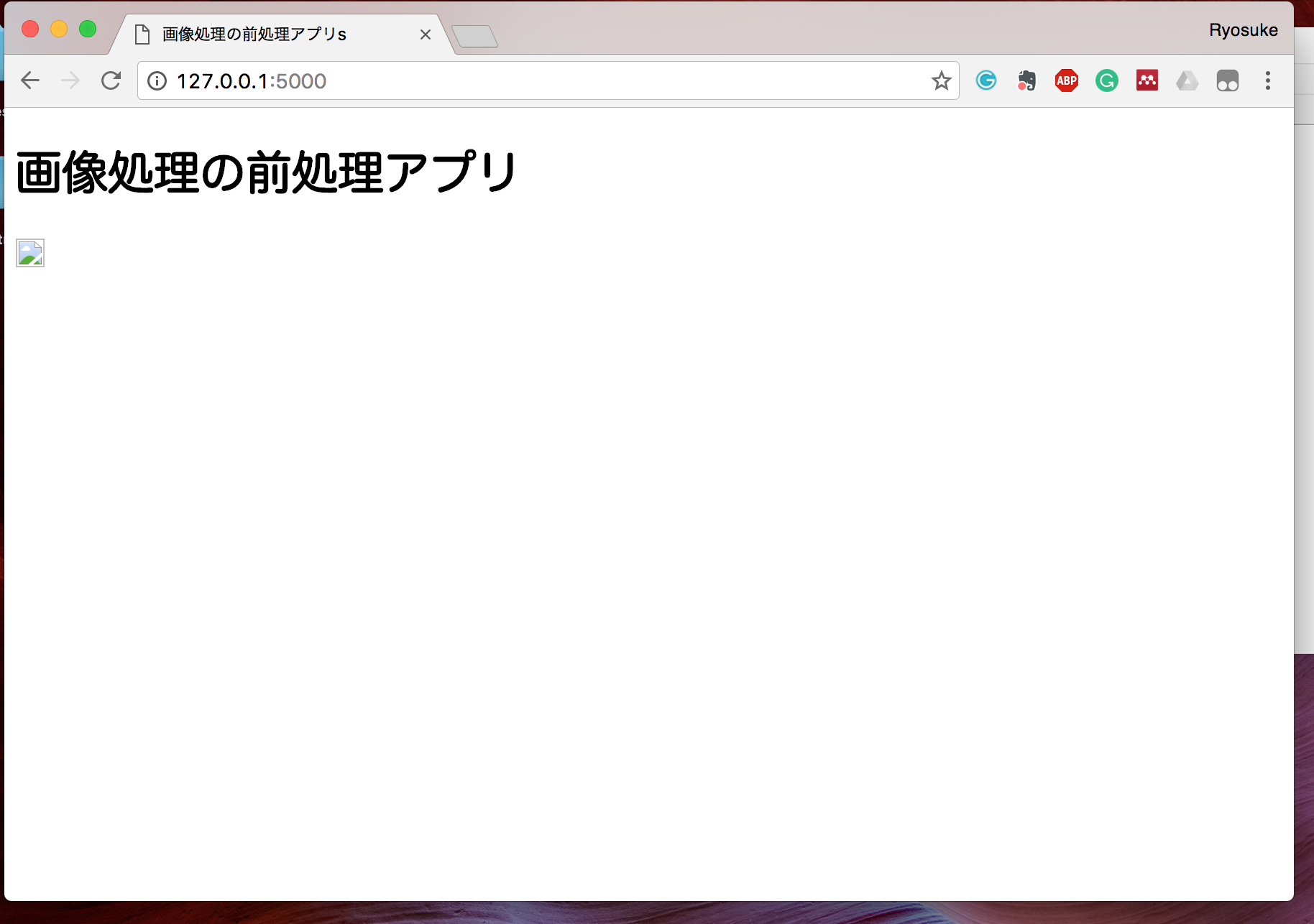
Webページとしては、うまくアクセスできていそうですが、画像がうまく表示されていません。
これは、Flaskでは画像などのファイルは static フォルダに格納するように決まっているらしく、フォルダごと移動します。
$ mkdir static
$ mv -f images static/ # -f はフォルダごと全て移動するためのオプション
そして、この移動後のディレクトリの構成は以下のようになります。
image_recog
├── app.py
├── static
│ └── images
└── templates
└── index.html
そして、index.html も読み込む画像の場所が変わったため、内容を変更します。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>画像処理の前処理アプリs</title>
</head>
<body>
<h1>画像処理の前処理アプリ</h1>
<img src="static/images/image01.png">
</body>
</html>
上記の img src に static/ を追加しています。
これで、もう一度Webサーバーを立ち上げて、確認してみましょう。
$ python3 app.py
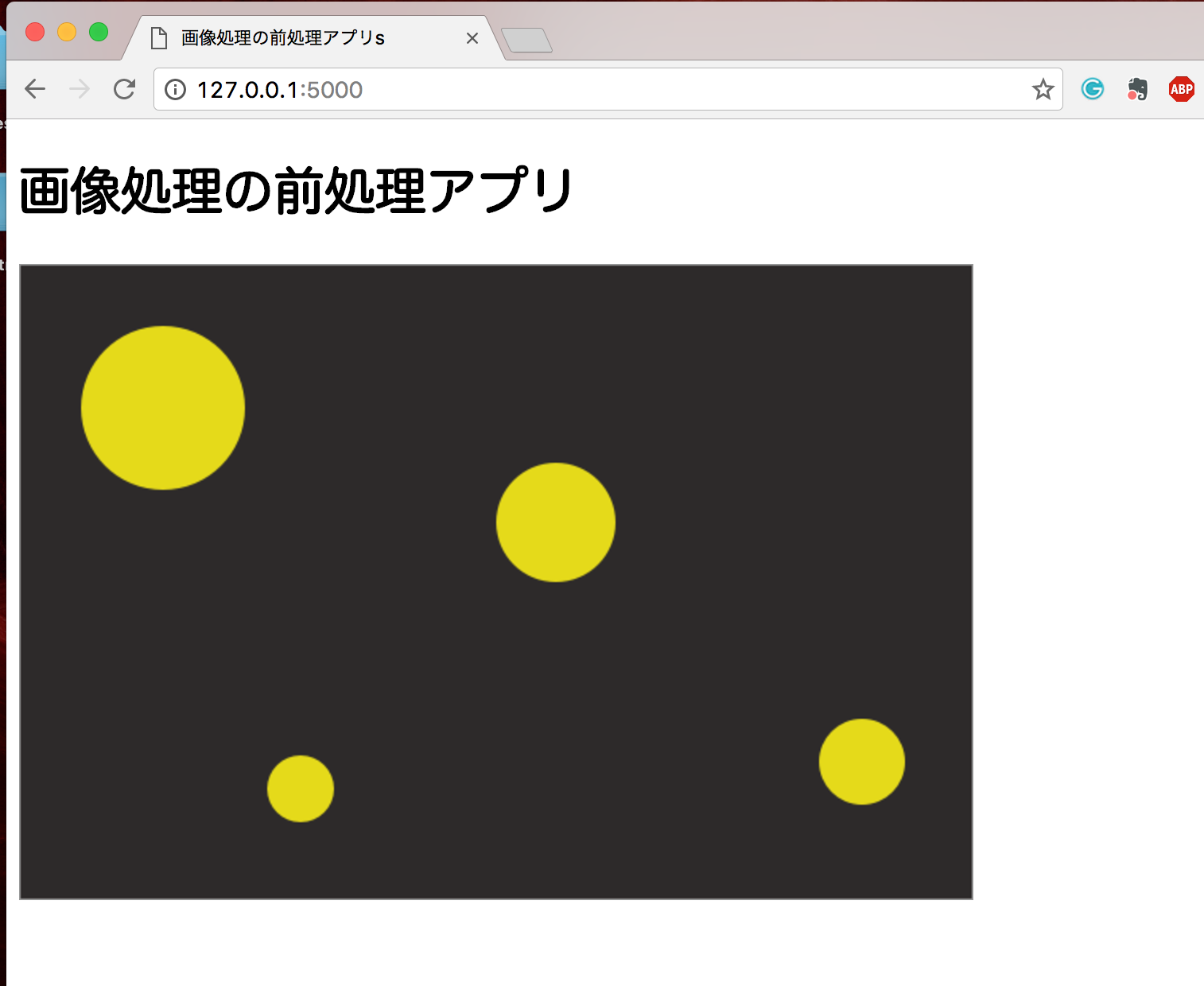
これでうまく画像も表示されました。
FlaskなどのWebフレームワークを利用する際は、ある程度の決まりごとがあるため、うまくいかないときはGoogleで調べてみると stack overflow などで回答を見つけることができます。
ちなみに、今回は こちら で回答を見つけました。
画像に対する操作を保存するDBを作成
それでは、サーバーサイドを開発するメリットの一つと言える、DBとのやりとりを見ていきましょう。
Webで使われているHTTPというプロトコルは ステートレス と呼ばれ、次のページへ移動する際に情報を渡すことができません。
こうすることによって、Webの通信を非常にシンプルにできるためだそうですが、こちらは次の画像へといった情報を渡したりしたい立場としては、非常に迷惑な話です。
そこで、次のページへ移動した際に、これまでの情報を受け渡しするために、データベース(DB)と呼ばれる場所に格納し、そこから情報を読み出したり、書き込んだりします。
DBアプリケーションの種類
DBのアプリケーションにもいくつか種類があり、Webアプリでよく使われるのは以下の3つではないでしょうか。
- Sqlite ← 今回はこれ
- PostgreSQL
- MySQL
今回は Sqlite と呼ばれるデータベース用のアプリケーションを使用します。
Sqlite の導入が非常に簡単であることが使用する理由であり、少し大きなアプリケーションを作る際は PostgreSQL か MySQL を使用することをおすすめします。
後者のふたつは導入が多少面倒なのですが、高速に動作するため、数十人以上のユーザーが使用する場合は、こちらの方が良いと言えます。
まず、データベースを作成する場合は、どのような情報を保存するかといったデータベースの構造を最初に決めてしまうことが非常に重要になります。
※ この方法論については、基本情報処理技術者などで出題されるデータベースの正規化と呼ばれる処理を勉強すると良いと思います。
DBの構造
今回のデータベースに以下のようなテーブルを作成することにします。
※ データベースがエクセルファイル、テーブルがシートに対応します。
Image
| 名前 | 型 | 初期値 |
|---|---|---|
| id | integer | |
| filename | string | null |
| label | integer | null |
| is_complete | boolean | false |
filenameは単純にファイル名を格納し、labelはどのカテゴリーに属するかを整数値(integer)で割り振ります。
たとえば、「0を黄色、1を青色」のように決めておくことで、簡単にカテゴリーを数字で表現することができます。
そして、is_complete はすでにラベル付けが終わっているかを判定し、初期値に false を入れておくことで、最初はラベル付けが終わっていない状況から始めることができます。
DBの初期化
Sqliteの文法で書いても良いのですが、PythonにはSQLAlchemyというORマッパー(データベースを簡単に操作できるもの)があり、これを使うことで、Sqlite や PostgreSQL、MySQL であってもほとんど気にすることなく扱うことができます。
まず、Flaskでは慣習として、DBを扱うためのディレクトリ flaski を作成しておき、その中でDB用の操作を行ってきます。
$ mkdir flaski
$ touch flaski/__init__.py # これがあると、flaskiモジュールとして読み込みが可能になる
そして、多少複雑にはなってしまうのですが、以下のようにDB構成を記述していきます。
こちらに関しては慣れてきてから理解するので大丈夫なため、コピペでも構いません。
# coding: utf-8
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session, sessionmaker
from sqlalchemy.ext.declarative import declarative_base
import os
database_file = os.path.join(os.path.abspath(os.path.dirname(__file__)), 'image_recog.db')
engine = create_engine('sqlite:///' + database_file, convert_unicode=True)
db_session = scoped_session(
sessionmaker(
autocommit = False,
autoflush = False,
bind = engine
)
)
Base = declarative_base()
Base.query = db_session.query_property()
def init_db():
import flaski.models
Base.metadata.create_all(bind=engine)
# coding: utf-8
from sqlalchemy import Column, Integer, String, Boolean
from flaski.database import Base
from datetime import datetime
class Image(Base):
__tablename__ = 'images'
id = Column(Integer, primary_key=True)
filename = Column(String(128), unique=True)
label = Column(Integer)
is_complete = Column(Boolean)
def __init__(self, filename=None, label=None, is_complete=False):
self.filename = filename
self.label = label
self.is_complete = is_complete
そして、Pythonの対話モードを利用して、データベースを作成します。
$ python3
>>> from flaski.database import init_db
>>> init_db()
これにより flaski のディレクトリ内に image_recog.db というDBのファイルが作成されたでしょうか。
この中身を Sqlite で確認してみます。
$ sqlite3 flaski/image_recog.db # sqlite3 #{db名} でdbの内容を確認できる
sqlite> .schema # テーブルの中身を確認するコマンド
CREATE TABLE images (
id INTEGER NOT NULL,
filename VARCHAR(128),
label INTEGER,
is_complete BOOLEAN,
PRIMARY KEY (id),
UNIQUE (filename),
CHECK (is_complete IN (0, 1))
);
sqlite> .exit # sqliteの対話モードを終了
このようにして、DBの作成ができました。
ちなみに、現時点でのディレクトリ構成は以下のようになっています。
image_recog
├── app.py
├── flaski
│ ├── __init__.py
│ ├── __pycache__
│ ├── database.py
│ ├── image_recog.db
│ └── models.py
├── static
│ └── images
└── templates
└── index.html
対話モードでDB操作の練習
データベースの操作も兼ねて、まずPythonの対話モードでデータの挿入の練習をしてみましょう。
# DB操作に必要なモジュールのインポート
>>> from flaski.database import db_session
>>> from flaski.models import Image
# 格納したいデータを宣言
>>> col1 = Image(filename="sample01.png", label=1)
# そのままではオブジェクトのため中身を確認できない
>>> col1
<flaski.models.Image object at 0x10983aef0>
# . を付けてその後に属性名を記述すれば内容を確認できる
>>> col1.filename
'sample01.png'
>>> db_session.add(col1)
>>> db_session.commit() # この時点でDBに反映される
>>> col2 = Image(filename="sample02.png", label=0)
>>> col3 = Image(filename="sample03.png", label=1)
>>> db_session.add(col2)
>>> db_session.add(col3)
>>> db_session.commit()
>>> exit() # 対話モードの終了
ポイントは db_session.commit() されるまではDBには反映されていないというところです。
そして、これがDB内で反映されているか確認してみましょう。
$ sqlite3 flaski/image_recog.db # DBに接続
sqlite> select * from images; # selectは抽出で、*は全てという意味。imagesテーブルから全て表示ということになる
1|sample01.png|1|0 # <- DBに正しく登録されていることが確認できる
2|sample02.png|0|0
3|sample03.png|1|0
sqlite> .exit # 対話モードを終了
BooleanのTrueは1、Falseは0で表示されるようで、defalutをFalseにしているため、is_completeはすべて0となっています。
それでは、今度は登録したデータを削除してみましょう。
例えば、2番目に登録したデータを削除してみましょう。
# DB操作に必要なモジュールのインポート
>>> from flaski.database import db_session
>>> from flaski.models import Image
# query.filter_by で特定条件のカラムの絞込が可能
>>> col = Image.query.filter_by(filename="sample02.png").first() # 配列形式で渡されるため、.first() で一つに絞る
>>> col
<flaski.models.Image object at 0x107755da0>
>>> col.filename
'sample02.png'
# DBから削除
>>> db_session.delete(col)
>>> db_session.commit() # この時点でcommitされて反映される
>>> exit() # 対話モードの終了
それでは、DB内で正しく削除されているか確認してみましょう。
$ sqlite3 flaski/image_recog.db
sqlite> select * from images;
1|sample01.png|1|0
3|sample03.png|1|0
sqlite> .exit
2番目の sample02.png が削除されていることがわかります。
このようにして、Python内での扱いが分かりました。
最後に練習で使用したデータは不必要なので、すべてのデータを削除しましょう。
$ python3
>>> from flaski.database import db_session
>>> from flaski.models import Image
>>> Image.query.delete()
2
>>> db_session.commit()
>>> exit()
# sqliteで確認
$ sqlite3 flaski/image_recog.db
sqlite> select * from images; # 何も表示されない
sqlite> .exit
DBに画像を一括登録
DBの操作方法がわかったので、static/images/ に入っている画像ファイルをDB内に一括登録しましょう。
ここで、/reset にアクセスした際に、DB内を全て更新するように設定していきましょう。
まず、python内で static/image/ 内のファイルを全て把握するプログラムを書き、そのView側に反映させたりして挙動を確認しながら、進めていきましょう。
ディレクトリ内のファイルを検索するには、glob というメソッドを使えばOKです。
# coding: utf-8
from flask import Flask, render_template
from glob import glob # <- globメソッドを読み込み
app = Flask(__name__)
@app.route("/")
def index():
return render_template("index.html")
# 新しく /reset を追加!
@app.route("/reset")
def reset():
# 指定ディレクトリ内のファイルを取得
images = glob("static/images/*.png")
return render_template("reset.html", images=images)
if __name__ == "__main__":
app.run()
render_template内で images=images という風に引数として渡しているのですが、これはView側である reset.html 内で images というPythonの変数を扱うことができるようになります。
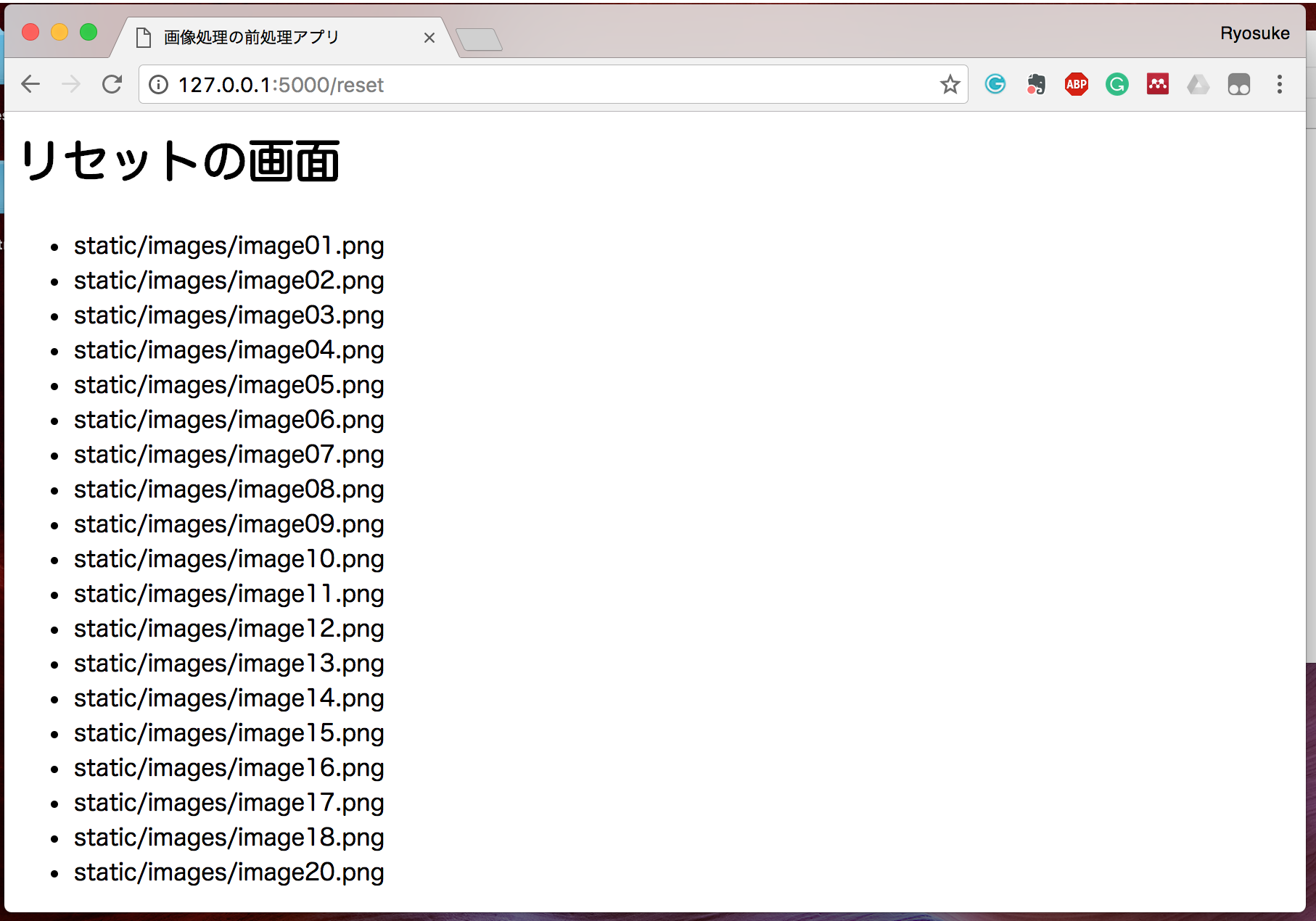
まず、reset.html から images を呼び出してみて、どのような値が渡されているのか確認してみましょう。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>画像処理の前処理アプリ</title>
</head>
<body>
<h1>リセットの画面</h1>
{{images}}
</body>
</html>
Pythonのrender_templateから渡される変数 images は View側(HTML)では、{{...}} のように囲むことで使用することができます。
こういったサーバーサイドとの連携により、少しずつWebアプリケーションとして自由度が高まってきました。
それでは、ローカル環境でWebサーバーを立てて、どのように表示されるか確認してみましょう。
$ python3 app.py
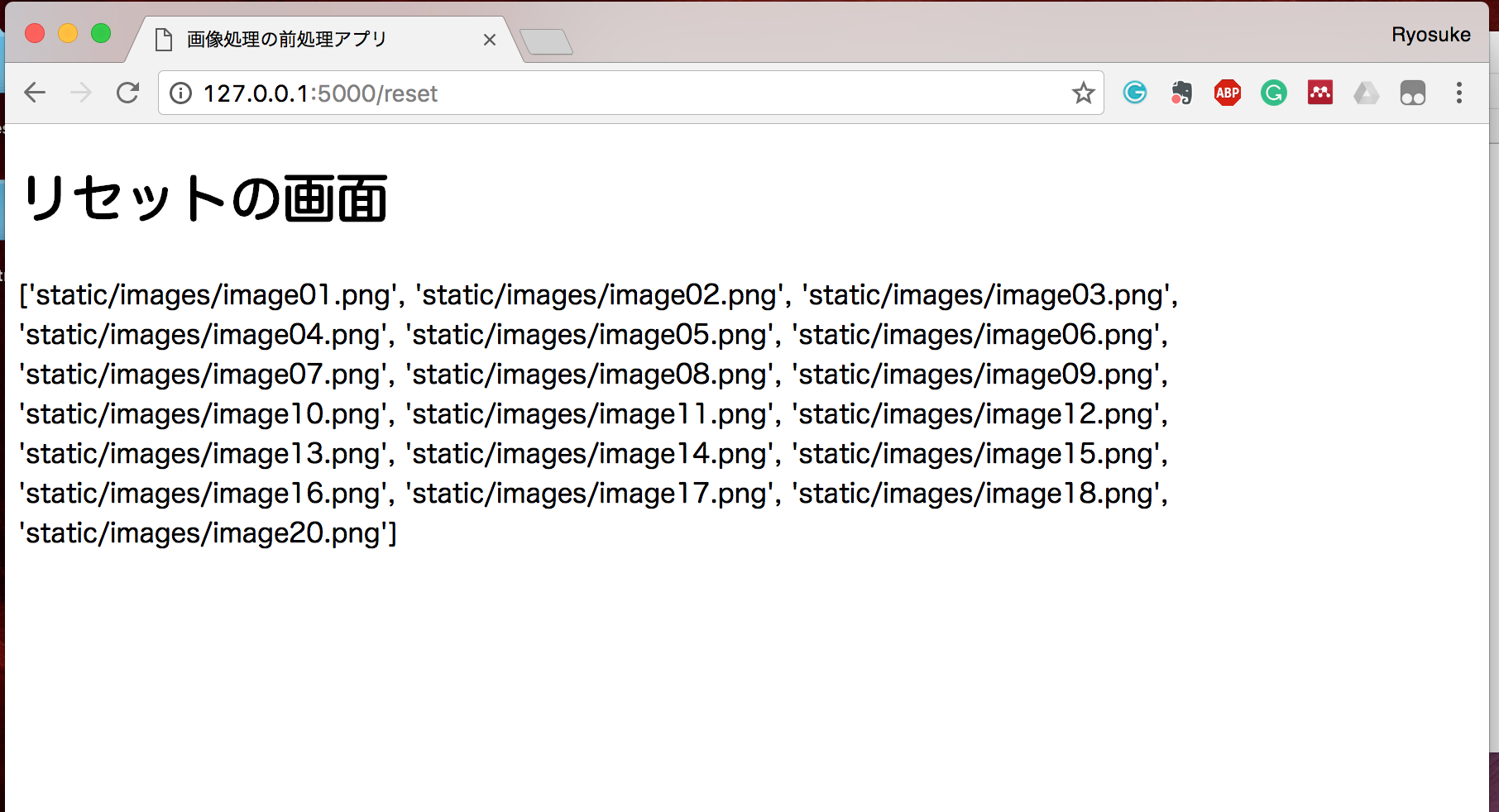
いかがでしょうか。
Python内の配列がView側にうまく引き渡されていることがお分かりいただけるでしょうか。
せっかく配列ならば、for文 も使って、もう少し上手く表示させたいですよね?
少し手を加えてみましょう。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>画像処理の前処理アプリ</title>
</head>
<body>
<h1>リセットの画面</h1>
<ul>
{% for image in images %}
<li>{{ image }}</li>
{% endfor %}
</ul>
</body>
</html>
このように {% ... %} の間で囲むことによって、Pythonの制御構文(forやif)が使えるようになります。
とっても便利ですね。
では、Viewに表示させることがゴールではなく、一括でこれらのファイルをDBに登録することが今回のゴールであったため、DBにファイル名を登録していきます。
Python側を編集していきましょう。
基本は対話型で行ったDBへの登録と同じです。
# coding: utf-8
from flask import Flask, render_template
from glob import glob
from flaski.database import db_session
from flaski.models import Image
app = Flask(__name__)
@app.route("/")
def index():
return render_template("index.html")
@app.route("/reset")
def reset():
# 指定ディレクトリ内のファイルを取得
images = glob("static/images/*.png")
# DB内を一括で削除
Image.query.delete()
# 新たにDBへ登録
for image in images:
col = Image(filename=image)
db_session.add(col)
db_session.commit() # 更新をDBに反映
return render_template("reset.html", images=images)
if __name__ == "__main__":
app.run()
これで完了です。
再度ローカルサーバーを立ち上げて、/reset にアクセスしましょう。
$ python3 app.py
特に表示側が変わることはありません。
それでは、DB側に正しく反映されているかサーバーを止めて確認していきましょう。
$ sqlite3 flaski/image_recog.db
sqlite> select * from images;
1|static/images/image01.png||0
2|static/images/image02.png||0
3|static/images/image03.png||0
4|static/images/image04.png||0
5|static/images/image05.png||0
6|static/images/image06.png||0
7|static/images/image07.png||0
8|static/images/image08.png||0
9|static/images/image09.png||0
10|static/images/image10.png||0
11|static/images/image11.png||0
12|static/images/image12.png||0
13|static/images/image13.png||0
14|static/images/image14.png||0
15|static/images/image15.png||0
16|static/images/image16.png||0
17|static/images/image17.png||0
18|static/images/image18.png||0
19|static/images/image20.png||0
sqlite> .exit
このように正しくDBへ書き込まれているでしょうか。
それでは、index.htmlで is_complete=False のファイルをDBから検索し、その一番最初の画像を表示するようにしてみましょう。
# coding: utf-8
from flask import Flask, render_template
from glob import glob
from flaski.database import db_session
from flaski.models import Image
app = Flask(__name__)
@app.route("/")
def index():
image = Image.query.filter_by(is_complete=False).first() # DBからファイルの読み込み
return render_template("index.html", filename = image.filename) # filenameにDBから読み込んだファイル名を渡す
@app.route("/reset")
def reset():
# 指定ディレクトリ内のファイルを取得
images = glob("static/images/*.png")
# DB内を一括で削除
Image.query.delete()
# 新たにDBへ登録
for image in images:
col = Image(filename=image)
db_session.add(col)
db_session.commit() # 更新をDBに反映
return render_template("reset.html", images=images)
if __name__ == "__main__":
app.run()
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>画像処理の前処理アプリs</title>
</head>
<body>
<h1>画像処理の前処理アプリ</h1>
<p>ファイル名:{{ filename }}</p>
<p><img src="{{ filename }}"></p>
</body>
</html>
これでファイルを確認してみると、以下のように表示されたでしょうか。
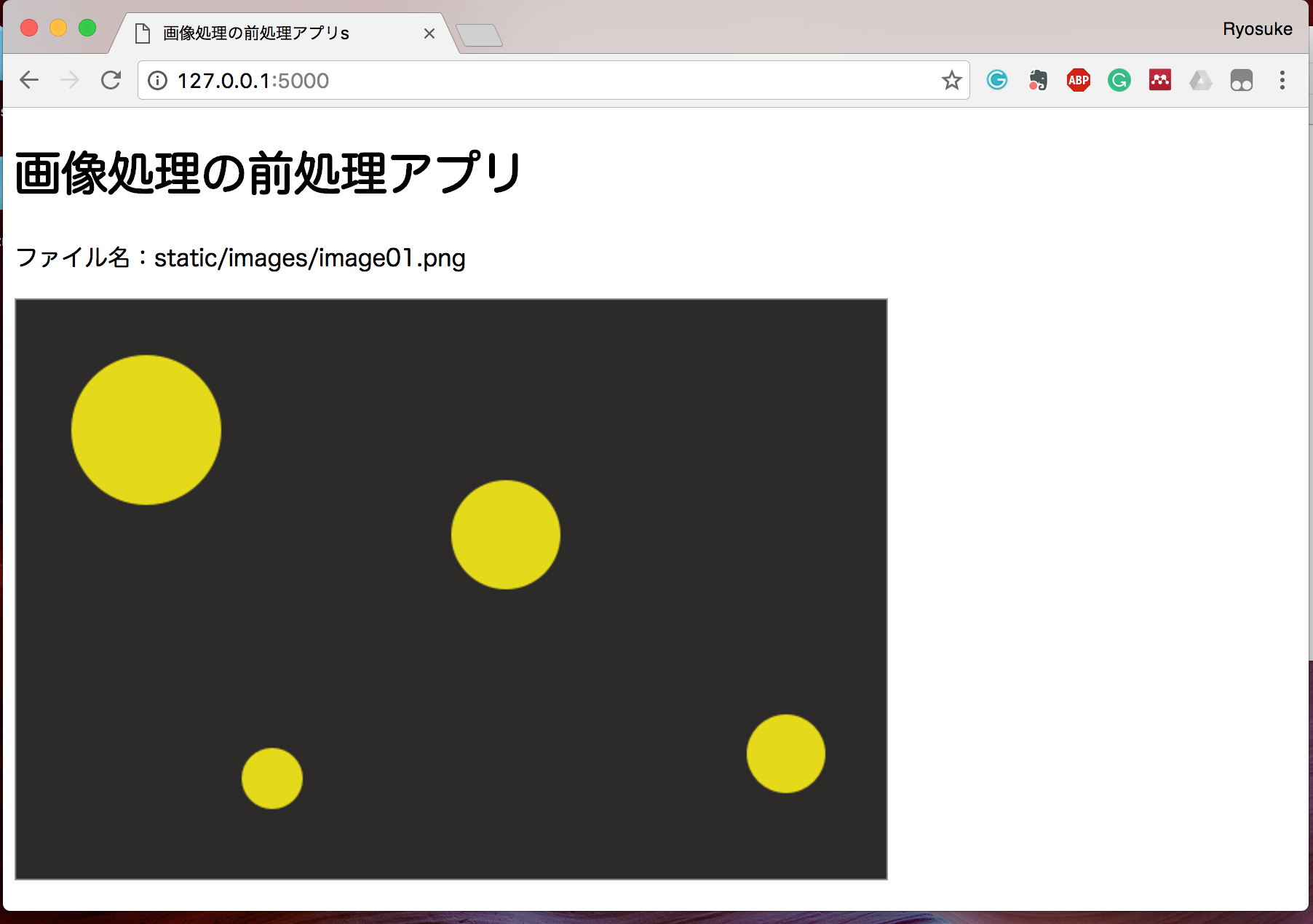
今回は確認用にファイル名も同時に表示させていますが、img の src 部分にpythonから渡された filename が格納されているため、DBから抽出したデータをうまくHTMLファイル内で反映させられていることがわかります。
このようにすれば、ステートレスで各ページごとに情報を保持できないHTTPにおいても、うまく情報を保持することができます。
画像に対するラベルを保存
DB内からファイル名を読み込んで表示することができるようになったため、次の画像に対するラベルを付け、DBに保存できるようにしていきましょう。
Flask内でフォームを扱うために便利な wtforms を使用するため、pip3 でインストールしましょう。
$ pip3 install wtforms
この wtforms を使って、Formの部分を作ります。
# coding: utf-8
from flask import Flask, render_template, request
from glob import glob
from flaski.database import db_session
from flaski.models import Image
from wtforms import Form, TextField
app = Flask(__name__)
# Label用のFormをクラスで宣言
class LabelForm(Form):
label = TextField('Label')
@app.route("/", methods=["GET", "POST"])
def index():
image = Image.query.filter_by(is_complete=False).first() # DBからファイルの読み込み
form = LabelForm(request.form) # formを追加
if request.method == "POST" and form.validate(): # POSTの場合の処理を追加
image.label = form.label.data # formから渡ってきたデータを受け取る
image.is_complete = True # 書き込みを完了
db_session.commit() # DBに保存
image = Image.query.filter_by(is_complete=False).first() # DBからファイルの再読み込み
return render_template("index.html", filename=image.filename, form=form) # filenameにDBから読み込んだファイル名を渡す
@app.route("/reset")
def reset():
# 指定ディレクトリ内のファイルを取得
images = glob("static/images/*.png")
# DB内を一括で削除
Image.query.delete()
# 新たにDBへ登録
for image in images:
col = Image(filename=image)
db_session.add(col)
db_session.commit() # 更新をDBに反映
return render_template("reset.html", images=images)
if __name__ == "__main__":
app.run()
```<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>画像処理の前処理アプリs</title>
</head>
<body>
<h1>画像処理の前処理アプリ</h1>
<p>ファイル名:{{ filename }}</p>
<!-- ラベル付のフォーム部分 -->
<form method=post>
<p>
ラベル:{{form.label}}
<input type=submit value=Register>
</p>
</form>
<!-- 画像の表示 -->
<p><img src="{{ filename }}"></p>
</body>
</html>
少し規模が大きくなってきましたが、基本的には form の部分を追加しただけです。
View側はこのようになっているでしょうか。
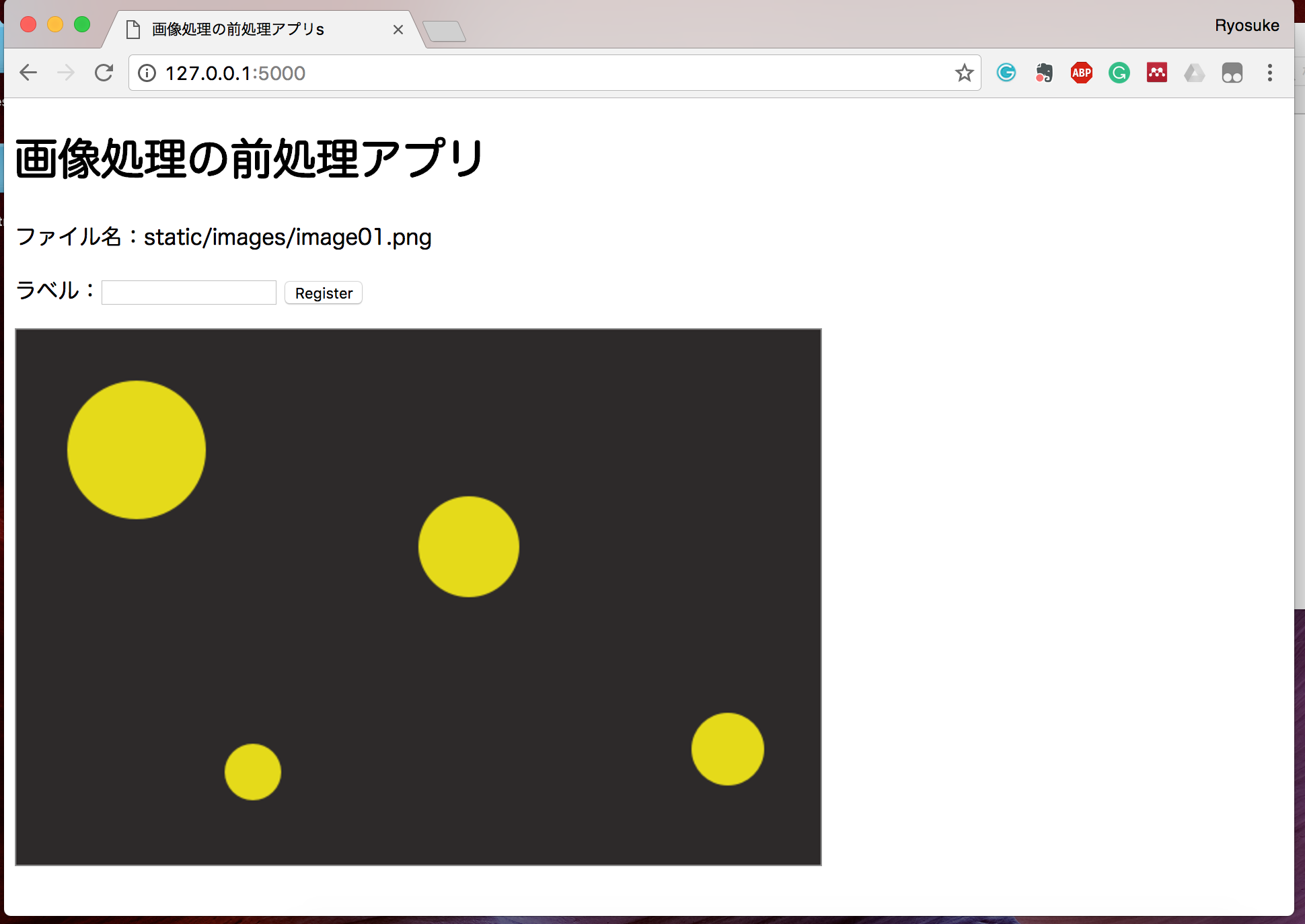
Methodの GET と POST について説明をしておくと、基本的にWebページにアクセスした際にはHTTPの GET というメソッドを使ってアクセスすることになります。
それに対し、フォームなどの処理を投げるときに POST というメソッドを使ってアクセスします。
もう少し違いはあるのですが、Formで投げたあとには POST でそれ以外は GET なんだなと覚えておいてもらえると最初は大丈夫です。
したがって、一番最初にURL経由でアクセスするときは GET になり、フォームにラベルの値を入力して Register を押すと、POST メソッドでアクセスすることになります。
そこで、Registerをした場合のみ、受け取ったラベルの情報をDBに書き込みたいので、app.py の中で if request.method == "POST" のように記述しているというわけです。
では、ラベルを付けて、Registerを押してみましょう。
黄色カテゴリーのラベルは0であったため、0と入力して Register を押しましょう。
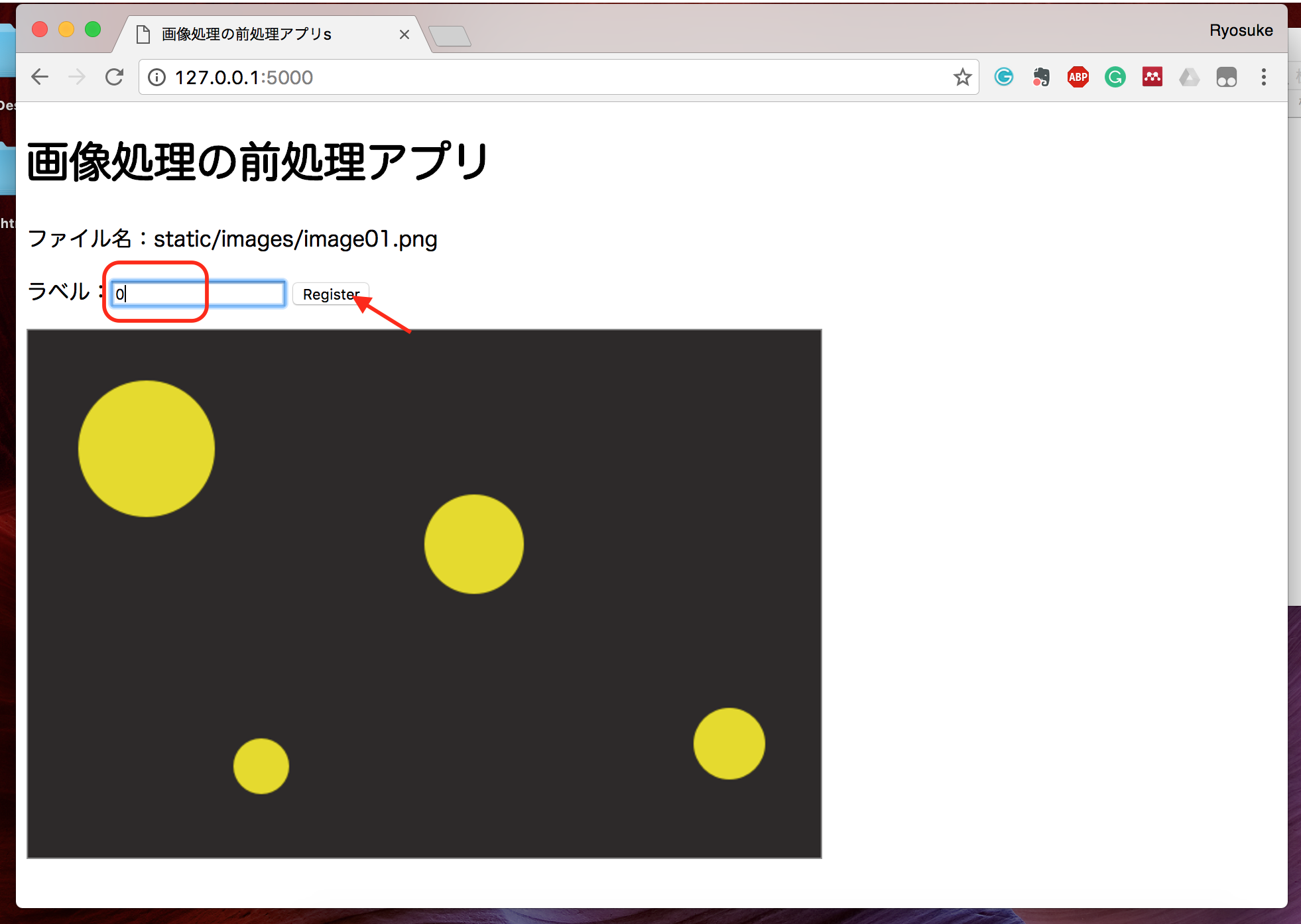
そうすると、次の画像に移行するはずです。
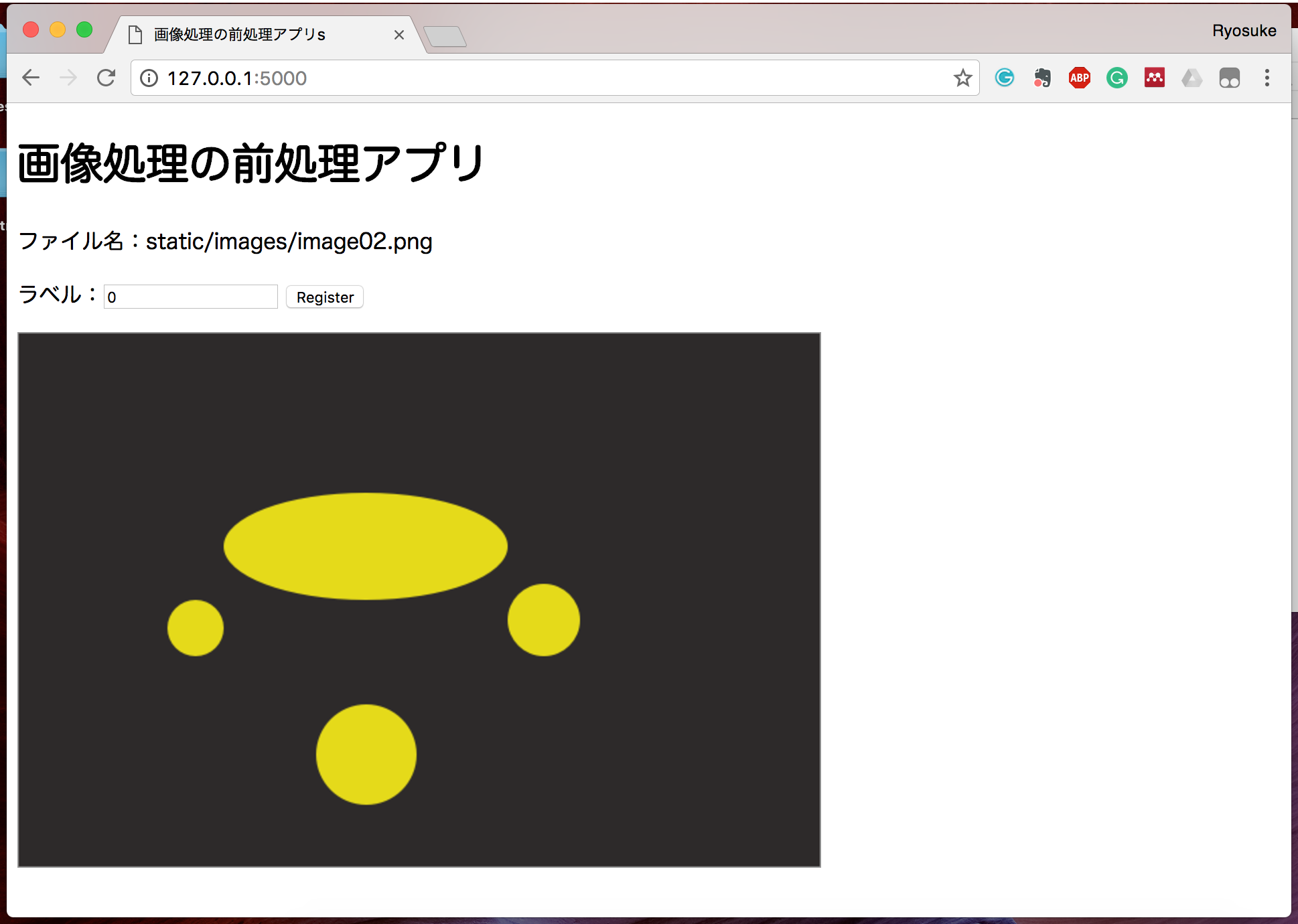
ここで、DBにラベル付けした情報が正しく書き込まれているか確認しましょう。
$ sqlite3 flaski/image_recog.db
SQLite version 3.14.0 2016-07-26 15:17:14
Enter ".help" for usage hints.
sqlite> select * from images;
1|static/images/image01.png|0|1 # <- ラベル0が書き込まれ、is_completeがTrueになっている!
2|static/images/image02.png||0
3|static/images/image03.png||0
4|static/images/image04.png||0
5|static/images/image05.png||0
6|static/images/image06.png||0
7|static/images/image07.png||0
8|static/images/image08.png||0
9|static/images/image09.png||0
10|static/images/image10.png||0
11|static/images/image11.png||0
12|static/images/image12.png||0
13|static/images/image13.png||0
14|static/images/image14.png||0
15|static/images/image15.png||0
16|static/images/image16.png||0
17|static/images/image17.png||0
18|static/images/image18.png||0
19|static/images/image20.png||0
sqlite> .exit
それでは、残りの20枚も同様にラベル付けをしていきましょう。
青カテゴリーの画像には1のラベルを割り振ります。
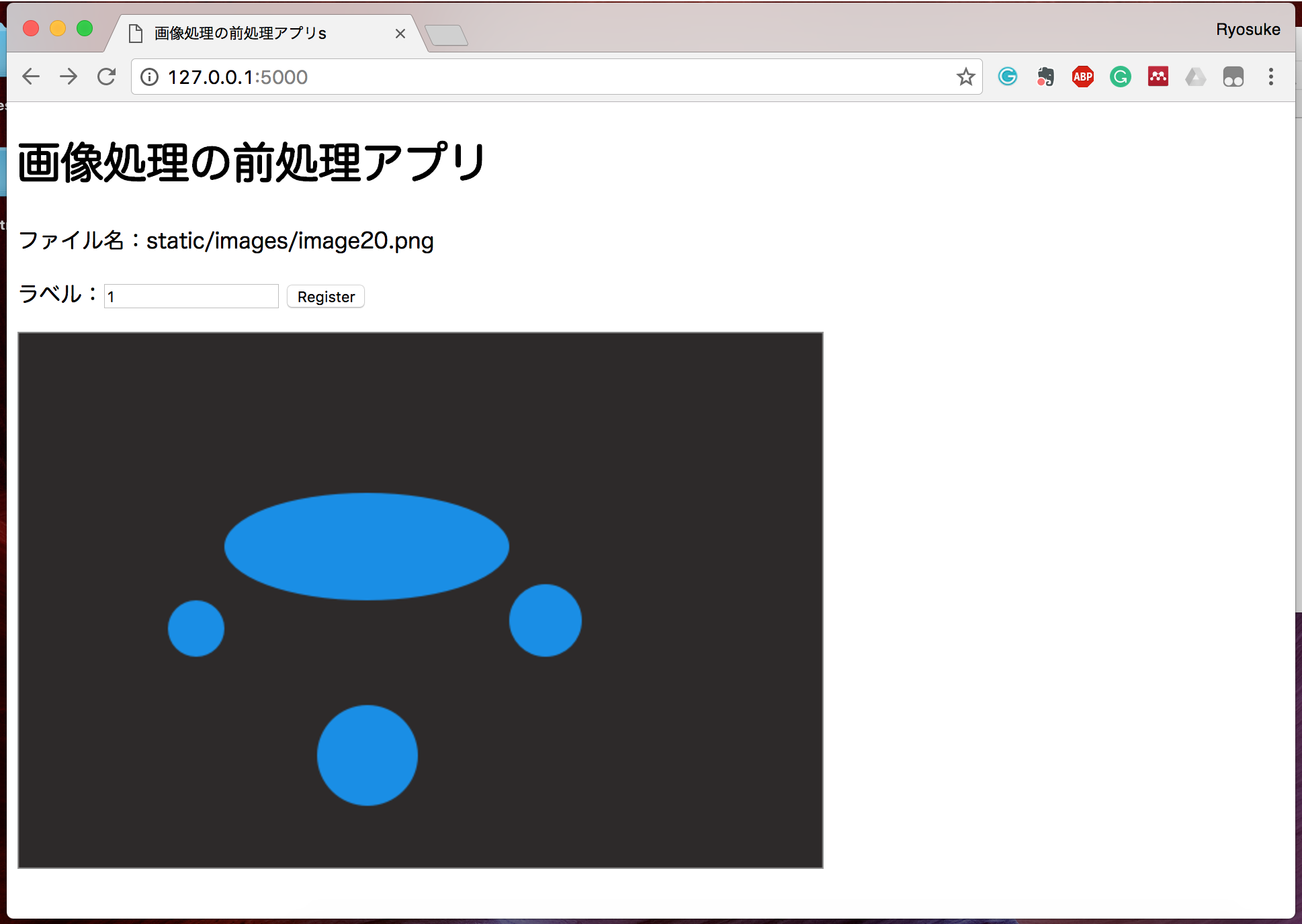
最後の一枚が終わると、このように Internal Server Error が出ます。
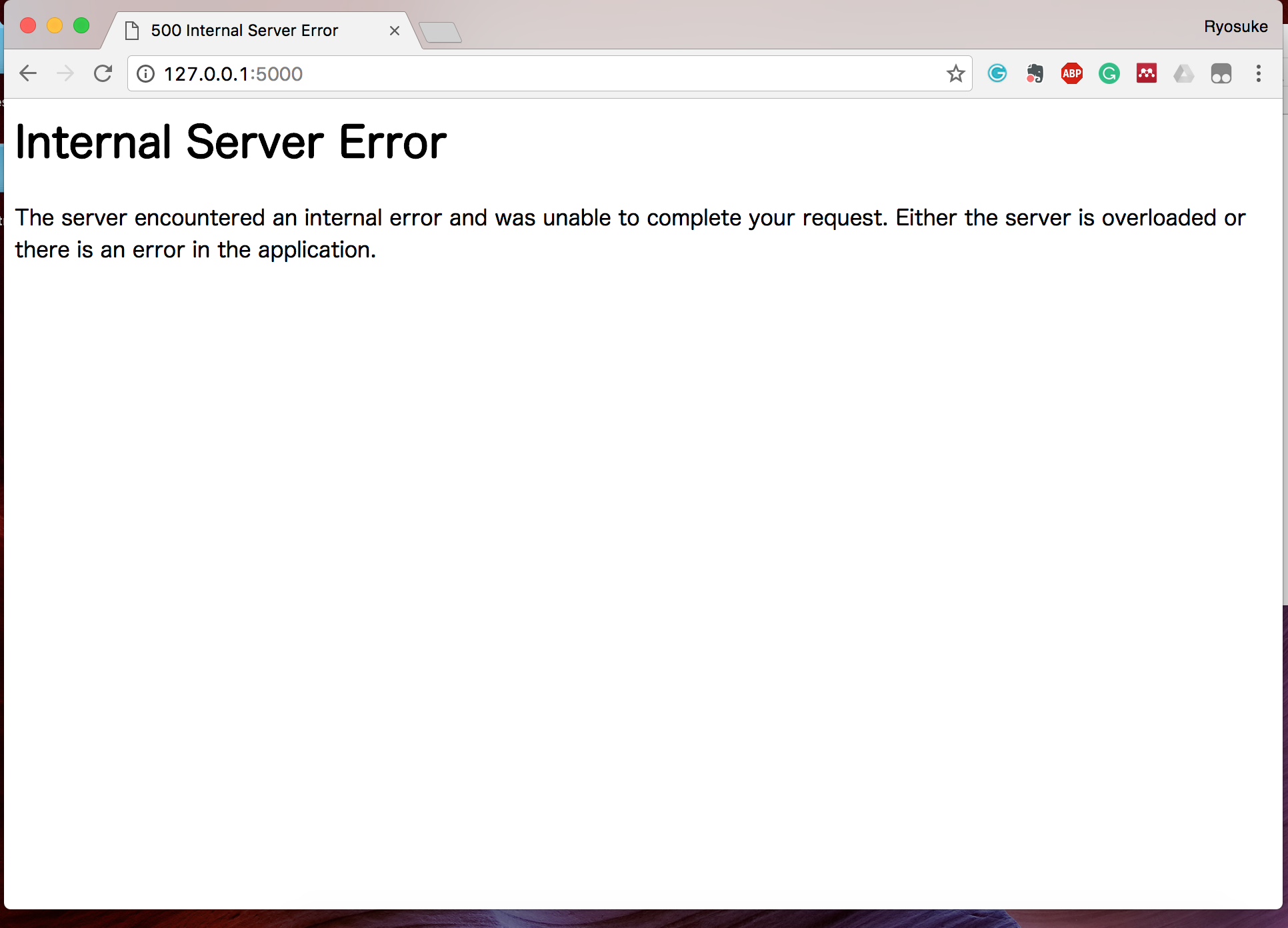
これは、Python側のプログラムのどこかにエラーがあると示しており、ターミナルで以下のようなエラーが出ているのではないでしょうか。

このように、エラーが起きた際には、ターミナル側でそのエラーの内容を確認しながら修正を進めていきましょう。
今回は明らかに、is_complete が False の画像がなくなり、DBから検索しても見つかりませんというエラーです。
とりあえず、ラベル付は完了したので無視しましょう。
DB内には以下のように、ラベル付けができているでしょうか。
$ sqlite3 flaski/image_recog.db
sqlite> select * from images;
1|static/images/image01.png|0|1
2|static/images/image02.png|0|1
3|static/images/image03.png|0|1
4|static/images/image04.png|0|1
5|static/images/image05.png|0|1
6|static/images/image06.png|0|1
7|static/images/image07.png|0|1
8|static/images/image08.png|0|1
9|static/images/image09.png|0|1
10|static/images/image10.png|0|1
11|static/images/image11.png|1|1
12|static/images/image12.png|1|1
13|static/images/image13.png|1|1
14|static/images/image14.png|1|1
15|static/images/image15.png|1|1
16|static/images/image16.png|1|1
17|static/images/image17.png|1|1
18|static/images/image18.png|1|1
19|static/images/image20.png|1|1
sqlite> .exit
保存したラベルのデータをファイルに出力する
最後に、ラベル付けした情報をDBから取得し、CSV形式でダウンロードできるようにしていきます。
/donwload というURLにアクセスすると、CSVが自動的にダウンロードされるようにします。
そのため、View側の設定は特に必要なく、Python側のみ編集していきます。
# coding: utf-8
from flask import Flask, Response, render_template, request, make_response # <- 追加
from glob import glob
from flaski.database import db_session
from flaski.models import Image
from wtforms import Form, TextField
import csv, io # <- 追加
app = Flask(__name__)
class LabelForm(Form):
label = TextField('Label')
# *** トップページ ***
@app.route("/", methods=["GET", "POST"])
def index():
image = Image.query.filter_by(is_complete=False).first() # DBからファイルの読み込み
form = LabelForm(request.form)
if request.method == "POST" and form.validate():
image.label = form.label.data
image.is_complete = True
db_session.commit()
image = Image.query.filter_by(is_complete=False).first() # DBからファイルの再読み込み
return render_template("index.html", filename=image.filename, form=form) # filenameにDBから読み込んだファイル名を渡す
# *** CSVをダウンロード *** <- 主にこの部分を追加
@app.route("/download")
def download():
# レスポンス用に宣言
response = make_response()
response.headers['Content-Type'] = 'text/csv'
response.headers['Content-Disposition'] = u'attachment; filename=data.csv'
# ラベル付けが完了しているデータを抽出
queries = Image.query.filter_by(is_complete=True)
result = []
for query in queries:
result.append((query.filename, query.label))
# CSV出力用のメソッド
csv_file = io.StringIO()
writer = csv.writer(csv_file)
writer.writerows(result)
# データを格納
response.data = csv_file.getvalue()
return response
# *** DBをリセット ***
@app.route("/reset")
def reset():
# 指定ディレクトリ内のファイルを取得
images = glob("static/images/*.png")
# DB内を一括で削除
Image.query.delete()
# 新たにDBへ登録
for image in images:
col = Image(filename=image)
db_session.add(col)
db_session.commit() # 更新をDBに反映
return render_template("reset.html", images=images)
if __name__ == "__main__":
app.run()
これでOKです。
ローカル環境でサーバーを立ち上げ、http://127.0.0.1:5000/download にアクセスしてみましょう。
このようにCSVファイルがダウンロードできたでしょうか。
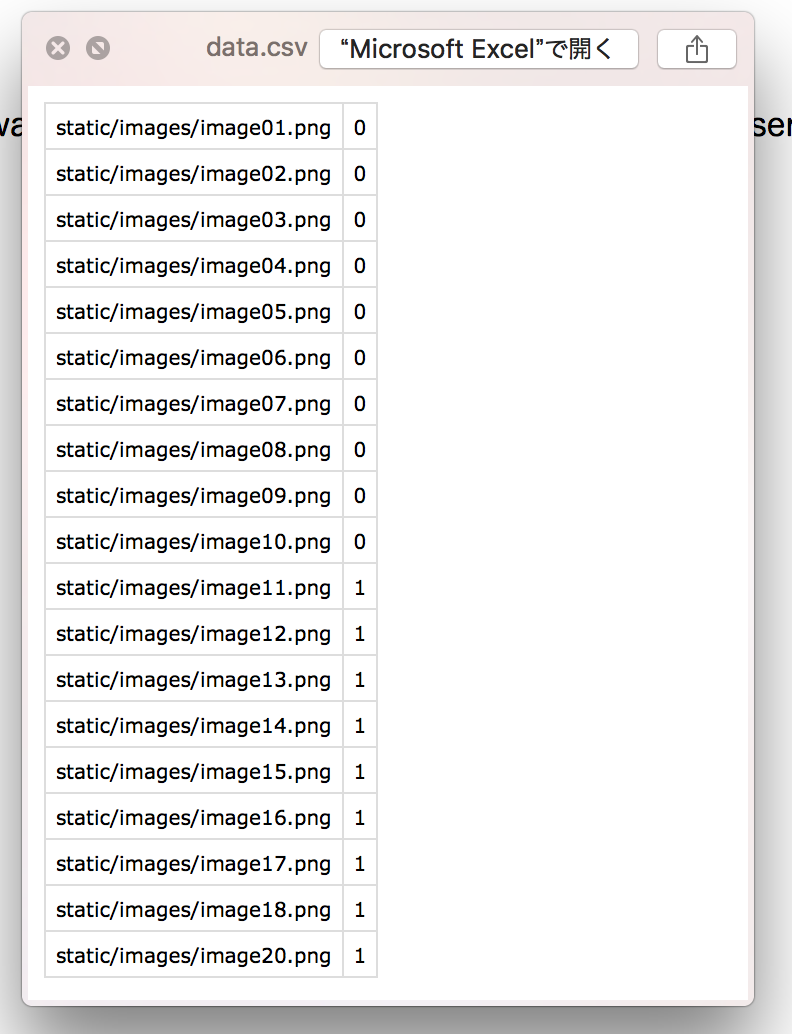
これで、ラベル付けしたデータをダウンロードしてくることができました。
応用編
前回、前処理アプリを作成しながら、画像のカテゴリー分類のためのラベル付けを行いました。
今回はそのラベル付けしたデータを教師データとして、クラス分類を行っていきます。
画像のサイズを縮小
配布した画像のサイズは 600 × 400 ピクセルとなっており、合計で 240,000 (24万ピクセル) となっています。
しかも、RGBでそれぞれに値を保持しているため、24万ピクセル × 3 = 72万ピクセルが、ディープラーニングの入力として使用する入力変数となります。
経験則ですが、72万次元 とは非常に変数の数として大きく、学習データの数が非常に多くないとうまく学習することができません。
そこで、今回は、画像のサイズを縮小して使用します。
どの程度縮小するかといった点は経験則ですが、そもそも色のデータだけで識別できれば良く、形が多少崩れていても大丈夫であるため、まず非常に小さなサイズに縮小して識別を行ってみます。
ダメであれば、画像サイズを大きくして再度調整してみるといった流れが良いかと思います。
今回は前回紹介した画像処理ライブラリであるOpenCVを使用して、画像のサイズを縮小し、保存するといったプログラムを組みました。
# coding: utf-8
import os
from glob import glob
import cv2
import numpy as np
HEIGHT = 10 # 縮小後の縦のサイズ
WIDTH = 15 # 縮小後の横のサイズ
# ディレクトリ内の画像ファイルの取得
files = glob("static/images/*.png")
for filepath in files:
# OpenCVで画像の読み込み
img = cv2.imread(filepath)
# 画像の縮小
small_image = cv2.resize(img, (HEIGHT, WIDTH))
# 縮小後のファイル名
small_filename = "static/small_images/" + os.path.basename(filepath)
# 画像の保存
cv2.imwrite(small_filename, small_image)
これを保存し、pythonで実行すると、縮小された画像ファイルが保存されます。
$ python resize.py
この実行後に static/small_images/ の中に以下のような縮小された画像ファイルが保存されているでしょうか。
形はかなり崩れてしまっていますが、肉眼でも色を識別できるレベルですので、「黄色か青か」といった2クラス分類程度であれば、おそらく可能だと思います。
これにより、元の72万次元の入力変数から、10(縦)×15(横)×3(色)= 450次元 まで圧縮することができました。
実際には、このPythonのスクリプトを使用せず、次のCNNでは内部で画像のサイズを変換しながら進めていきます。
※ 内部の動きをわかりやすいように保存して確認しました。
CNNによるカテゴリ分類
画像の識別に強いCNN(Convolutional Neaural Network)を使用して、識別器の作成を行います。
すごく単純に言うと、画像を入力として、CNNが中でごちゃごちゃと編集して、カテゴリを出力として返してくれます。
最終的に出来上がる全体像はこちらのようになります。

これをChainerを使って、Pythonで書いていきましょう。
# coding: utf-8
from chainer import Link, Chain, ChainList, Variable, FunctionSet, optimizers, serializers
import chainer.functions as F
import chainer.links as L
import numpy as np
import cv2
import csv
# *** 定数 ***
WIDTH, HEIGHT = 15, 10 # 画像のサイズ
# CNNモデルで使用する定数
input_channel = 3
output_channel = 12
filter_height = 3
filter_width = 3
mid_units = 180
n_units = 50
n_label = 2
# *** モデルの定義 ***
class CNN(Chain):
"""
Convolutional Neural Network のモデル
input_channel : 入力するチャンネル数(通常のカラー画像なら3)
output_channel : 畳み込み後のチャンネル数
filter_height : 畳み込みに使用するフィルターの縦方向のサイズ
filter_width : 畳み込みに使用するフィルターの横方向のサイズ
mid_units : 全結合の隠れ層1のノード数
n_units : 全結合の隠れ層2のノード数
n_label : ラベルの出力数(今回は2)
"""
# *** モデルの構造の定義 ***
def __init__(self, input_channel, output_channel, filter_height, filter_width, mid_units, n_units, n_label):
super(CNN, self).__init__(
conv1 = L.Convolution2D(input_channel, output_channel, (filter_height, filter_width)),
l1 = L.Linear(mid_units, n_units),
l2 = L.Linear(n_units, n_label),
)
# *** 順方向の計算 ***
def forward(self, x, t, train=True):
h1 = F.max_pooling_2d(F.relu(self.conv1(x)), 3)
h2 = F.dropout(F.relu(self.l1(h1)), train=True)
y = self.l2(h2)
if train:
return F.softmax_cross_entropy(y, t)
else:
return F.softmax_cross_entropy(y, t), F.accuracy(y, t)
# *** 予測 ***
def predict(self, x):
h1 = F.max_pooling_2d(F.relu(self.conv1(x)), 3)
h2 = F.dropout(F.relu(self.l1(h1)))
y = self.l2(h2)
return F.softmax(y).data
# *** 訓練データの準備 ***
x_train, y_train = [], []
x_test, y_test = [], []
csv_reader = csv.reader(open('data.csv','r'), delimiter=",")
for row in csv_reader:
# row[0]: ファイル名, row[1]: ラベル
img = cv2.imread(row[0]) # 画像の読み込み <- OpenCVではNumpyの形式で格納される
resize_img = cv2.resize(img, (HEIGHT, WIDTH)) # 画像を縮小
input_img = np.transpose(resize_img, (2,0,1)) / 255.0 # データ項目入れ替えて、0-1に正規化(チャンネルを一番前に)
x_train.append(input_img)
y_train.append(row[1])
train_data = np.array(x_train).astype(np.float32).reshape(len(x_train), 3, HEIGHT, WIDTH)
train_label = np.array(y_train).astype(np.int32)
# *** モデルの宣言 ***
model = CNN(input_channel, output_channel, filter_height, filter_width, mid_units, n_units, n_label)
# *** 最適化オブジェクト ***
optimizer = optimizers.Adam()
optimizer.setup(model)
# *** 学習 ***
n_epoch = 50
x = Variable(np.asarray(train_data))
t = Variable(np.asarray(train_label))
for i in range(n_epoch):
optimizer.update(model.forward, x, t)
loss, accuracy = model.forward(x, t, train=False)
print("--- ", i+1, "回目の学習 ---")
print(" 損失関数: %1.3f" % loss.data)
print(" 正解率: ", round(accuracy.data * 100), "%")
print("")
# *** 結果を確認 ***
print(model.predict(x))
# *** 学習したモデルを保存 ***
serializers.save_npz('cnn_classify.model', model)
学習用のデータを準備し、用意したモデルに入れて学習。
そして、最終的な結果(学習したモデル)を cnn_classify.model として保存しています。
いかがでしょうか。
思っていたよりも組む数が多く、驚かれているのではないでしょうか。
「このご時世、Deep Learningが手軽に使える」とよく聞くのですが、それはプログラマにとって扱いやすくなったことを意味しており、ビジネスパーソンがほんとに簡単に扱えるわけではなさそうです。
もちろん、サンプルプログラムを動作させるだけであれば、ほんとに5分で動かすことができるのですが、自分たちの製品向けにカスタマイズしていくためには、このように自力でプログラムを組めなければ意味がありません。
ちなみに、ディレクトリの構造はこちらのようになっておりますので、動作させる場合は合わせておいてください。
image_recog
├── __pycache__
│ └── CNN.cpython-35.pyc
├── app.py
├── classify.py
├── data.csv
├── flaski
│ ├── __init__.py
│ ├── __pycache__
│ ├── database.py
│ ├── image_recog.db
│ └── models.py
├── resize.py
├── static
│ ├── images
│ └── small_images
└── templates
├── index.html
└── reset.html
それでは、実際に学習させていきましょう。
yosuke-2:image_recog Ryosuke$ python3 classify.py
--- 1 回目の学習 ---
損失関数: 0.703
正解率: 42.0 %
--- 2 回目の学習 ---
損失関数: 0.668
正解率: 53.0 %
--- 3 回目の学習 ---
損失関数: 0.624
正解率: 63.0 %
--- 4 回目の学習 ---
損失関数: 0.634
正解率: 68.0 %
--- 5 回目の学習 ---
損失関数: 0.641
正解率: 63.0 %
--- 6 回目の学習 ---
損失関数: 0.629
正解率: 63.0 %
--- 7 回目の学習 ---
損失関数: 0.641
正解率: 63.0 %
--- 8 回目の学習 ---
損失関数: 0.620
正解率: 74.0 %
--- 9 回目の学習 ---
損失関数: 0.607
正解率: 68.0 %
--- 10 回目の学習 ---
損失関数: 0.616
正解率: 68.0 %
--- 11 回目の学習 ---
損失関数: 0.575
正解率: 84.0 %
--- 12 回目の学習 ---
損失関数: 0.620
正解率: 74.0 %
--- 13 回目の学習 ---
損失関数: 0.591
正解率: 74.0 %
--- 14 回目の学習 ---
損失関数: 0.581
正解率: 84.0 %
--- 15 回目の学習 ---
損失関数: 0.553
正解率: 89.0 %
--- 16 回目の学習 ---
損失関数: 0.509
正解率: 89.0 %
--- 17 回目の学習 ---
損失関数: 0.546
正解率: 89.0 %
--- 18 回目の学習 ---
損失関数: 0.551
正解率: 100.0 %
--- 19 回目の学習 ---
損失関数: 0.505
正解率: 95.0 %
--- 20 回目の学習 ---
損失関数: 0.492
正解率: 95.0 %
--- 21 回目の学習 ---
損失関数: 0.524
正解率: 95.0 %
--- 22 回目の学習 ---
損失関数: 0.497
正解率: 95.0 %
--- 23 回目の学習 ---
損失関数: 0.478
正解率: 100.0 %
--- 24 回目の学習 ---
損失関数: 0.484
正解率: 84.0 %
--- 25 回目の学習 ---
損失関数: 0.459
正解率: 100.0 %
--- 26 回目の学習 ---
損失関数: 0.397
正解率: 95.0 %
--- 27 回目の学習 ---
損失関数: 0.432
正解率: 100.0 %
--- 28 回目の学習 ---
損失関数: 0.431
正解率: 100.0 %
--- 29 回目の学習 ---
損失関数: 0.374
正解率: 100.0 %
--- 30 回目の学習 ---
損失関数: 0.390
正解率: 100.0 %
--- 31 回目の学習 ---
損失関数: 0.376
正解率: 100.0 %
--- 32 回目の学習 ---
損失関数: 0.364
正解率: 100.0 %
--- 33 回目の学習 ---
損失関数: 0.328
正解率: 100.0 %
--- 34 回目の学習 ---
損失関数: 0.324
正解率: 100.0 %
--- 35 回目の学習 ---
損失関数: 0.313
正解率: 100.0 %
--- 36 回目の学習 ---
損失関数: 0.314
正解率: 100.0 %
--- 37 回目の学習 ---
損失関数: 0.270
正解率: 100.0 %
--- 38 回目の学習 ---
損失関数: 0.299
正解率: 100.0 %
--- 39 回目の学習 ---
損失関数: 0.278
正解率: 100.0 %
--- 40 回目の学習 ---
損失関数: 0.263
正解率: 95.0 %
--- 41 回目の学習 ---
損失関数: 0.237
正解率: 100.0 %
--- 42 回目の学習 ---
損失関数: 0.206
正解率: 100.0 %
--- 43 回目の学習 ---
損失関数: 0.184
正解率: 100.0 %
--- 44 回目の学習 ---
損失関数: 0.212
正解率: 100.0 %
--- 45 回目の学習 ---
損失関数: 0.178
正解率: 100.0 %
--- 46 回目の学習 ---
損失関数: 0.167
正解率: 100.0 %
--- 47 回目の学習 ---
損失関数: 0.132
正解率: 100.0 %
--- 48 回目の学習 ---
損失関数: 0.155
正解率: 100.0 %
--- 49 回目の学習 ---
損失関数: 0.138
正解率: 100.0 %
--- 50 回目の学習 ---
損失関数: 0.107
正解率: 100.0 %
このように、パラメータを調整させながら、徐々に正解率が向上しているのがおわかりでしょうか。
たった20枚の画像でしたが、CNNによりカテゴリーを分類できるモデルが完成しました。
ちなみに、最下部に # *** 結果を確認 *** とあり、こちらの部分では、CNNのモデルにより、どのような値が結果として出力されているかを表示します。
[ 0.79787719 0.20212281] # 黄色
[ 0.92661881 0.07338118] # 黄色
[ 0.93955374 0.0604463 ] # 黄色
[ 0.92246622 0.07753379] # 黄色
[ 0.94427282 0.05572721] # 黄色
[ 0.9519788 0.04802115] # 黄色
[ 0.91585839 0.08414157] # 黄色
[ 0.80192369 0.19807628] # 黄色
[ 0.92825121 0.07174882] # 黄色
[ 0.68834418 0.31165582] # 黄色
[ 0.19181736 0.80818266] # 青色
[ 0.28698155 0.71301848] # 青色
[ 0.10502968 0.89497036] # 青色
[ 0.04594051 0.95405948] # 青色
[ 0.10114852 0.89885151] # 青色
[ 0.05096899 0.94903094] # 青色
[ 0.01882369 0.98117632] # 青色
[ 0.0530371 0.94696283] # 青色
[ 0.08224615 0.91775388] # 青色
黄色の場合、配列の左側の値が1に近い値となり、青色の場合、配列の右側の値が1に近い値となっていることがおわかりでしょうか。
このように、CNNでは、最終的な値を0-1の間で表現し、その最大ととなっている部分を最終的に識別するカテゴリの値として割り振ります。