はじめに
3時限目からはいよいよデータを使って、回帰や分類を行っていきます。
まずは実戦で使いやすい重回帰分析です。
1. 重回帰分析
- いくつかの観測できる値(説明変数、入力変数)から目的の値(目的変数、出力変数)を予測する手法
- 例)身長、性別、年齢から体重を予測する
重回帰分析の回帰式
{\boldsymbol a} =
\begin{bmatrix}
a_{1} \\ a_{2} \\ \vdots \\ a_{M}
\end{bmatrix}
,\
{\boldsymbol x} =
\begin{bmatrix}
x_{1} \\ x_{2} \\ \vdots \\ x_{M}
\end{bmatrix}
このとき、回帰式は以下のようになります。
\begin{align}
\hat{y} &= a_{1}x_{1} + a_{2}x_{2} + a_{3}x_{3} + \cdots + a_{M}x_{M} \\
&= {\boldsymbol x}^{T}{\boldsymbol a}
\end{align}
目的関数
$1$番目から$N$番目までのサンプルをひとまとめにした目的変数のベクトルを以下のように定義します。
{\boldsymbol y} =
\begin{bmatrix}
y_{1} \\
y_{2} \\
\vdots \\
y_{N} \\
\end{bmatrix}
,\
\hat{\boldsymbol y} =
\begin{bmatrix}
\hat{y}_{1} \\
\hat{y}_{2} \\
\vdots \\
\hat{y}_{N} \\
\end{bmatrix}
このとき、誤差平方和$e$は以下のようになります。
\begin{align}
e &= \sum_{n=1}^{N} \left( y_{n} - \hat{y}_{n} \right)^{2} \\
&= ({\boldsymbol y} - \hat{\boldsymbol y})^{T} ({\boldsymbol y} - \hat{\boldsymbol y})
\end{align}
重回帰分析では、この$e$を最小化するパラメータ$a$を求めることになります。
係数行列の解
入力変数行列 ${\boldsymbol X}$ を以下のように定義します。
\boldsymbol{X} = \begin{align}
\begin{bmatrix}
{\boldsymbol x}_{1}^{T} \\
{\boldsymbol x}_{2}^{T} \\
\vdots \\
{\boldsymbol x}_{N}^{T}
\end{bmatrix}
=
\begin{bmatrix}
[{x}_{11} & x_{12} & \cdots & x_{1M}] \\
[ {x}_{21} & x_{22} & \cdots & x_{2M}] \\
\vdots & \vdots & \ddots & \vdots\\
[{x}_{N1} & x_{N2} & \cdots & x_{NM} ]
\end{bmatrix}
=
\begin{bmatrix}
{x}_{11} & x_{12} & \cdots & x_{1M} \\
{x}_{21} & x_{22} & \cdots & x_{2M} \\
\vdots & \vdots & \ddots & \vdots\\
{x}_{N1} & x_{N2} & \cdots & x_{NM}
\end{bmatrix}
\end{align}
導出過程は数学の授業でやったので省略しますが、最終的に係数行列の解は以下のようになりました。
{\boldsymbol a} = \left( {\boldsymbol X}^{T}{\boldsymbol X} \right)^{-1} {\boldsymbol X}^{T}{\boldsymbol y}
この$\boldsymbol{a}$を使って、
\hat{y} = {\boldsymbol a}^{T}{\boldsymbol x}
が計算できることになります。
2. 問題設定
データ
- ボストン近郊の土地を506に分けた住宅情報 https://archive.ics.uci.edu/ml/machine-learning-databases/housing/
- 14個の特徴量を含む、506個のデータ
| 特徴量 | 説明 |
|---|---|
| CRIM | 犯罪発生率 |
| ZN | 25,000平方フィート以上の住宅区画の割合 |
| INDUS | 非小売業の土地面積の割合 |
| CHAS | チャールズ川沿いかどうか |
| NOX | 窒素酸化物の濃度 |
| RM | 1戸あたりの平均部屋数 |
| AGE | 1940年より前に建てられた家屋の割合 |
| DIS | ボストン近郊の主な雇用圏への距離 |
| RAD | 幹線道路へのアクセスのしやすさ |
| TAX | 所得税率 |
| PTRATIO | 教師あたりの生徒数 |
| B | アフリカ系アメリカ人居住者の割合 |
| LSTAT | 低所得者の割合 |
| MEDV | 住宅価格の中央値 |
課題
重回帰分析を使って住宅価格(の中央値)を予測するモデルを作りましょう。
- 説明変数:
MEDV以外の変数(すべての変数を使わなくてもOK) - 目的変数:
MEDV(住宅価格の中央値)
3. scikit-learnを使った重回帰分析
- scikit-learn:Pythonにおける機械学習ライブラリのデファクトスタンダード
- 目的変数として
MEDV(住宅価格の中央値)を利用、その他の値を説明変数とする
実装
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import linear_model
# データのURL
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data'
# データの読み込み
df = pd.read_csv(url, header=None, sep='\s+')
# 列の定義
df.columns = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
# 説明変数
X = df[['CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT']].values
# 目的変数
y = df['MEDV'].values
reg = linear_model.LinearRegression()
reg.fit(X, y) # モデルの学習
print(reg.coef_) # 係数の表示
print(reg.intercept_) # 切片の表示
予測
print([y[1]], reg.predict([X[1]])) # 実際の値と予測値を表示
print([y[2]], reg.predict([X[2]]))
print([y[3]], reg.predict([X[3]]))
評価
- 決定係数(寄与率)$R^2$:モデルの当てはまりの良さを表す(同じデータセットなら$0 \leq R \leq 1$)
- 1に近い方がよく当てはまっていると言える
R^2 = 1 - \frac {SSE} {SST} \\
SSE = \sum_{i=1}^{n} {(y^{(i)} - \hat{y}^{(i)})^2} \\
SST = \sum_{i=1}^{n} {(y^{(i)} - \mu_{y})^2}
- $SSE$は誤差平方和を表す
- $SST$は目的変数の平均値まわりのばらつきの総和を表す
print(reg.score(X, y)) # 決定係数(寄与率)の計算
トレーニングデータとテストデータの分割
train_test_splitメソッドを使って、データをトレーニング用とテスト用に分割
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
reg.fit(X_train, y_train)
print(reg.score(X_test, y_test)) # 再度、決定係数の計算
4. 演習
- 以下のデータはシリアルに関するデータです。 シリアルの人気度(rating)を予測するモデルを重回帰分析を使って求めてください。
http://mo161.soci.ous.ac.jp/@d/DoDStat/cereals/cereals_dataJ.xml
1. SVM
- パーセプトロンを拡張したアルゴリズム
- 分類や回帰に使われる
- サポートベクターと呼ばれるサンプル点を用いて識別面を求める
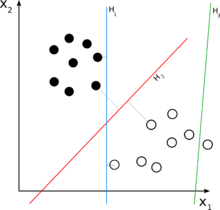
下図で言うと、黒い点のクラスと白い点のクラスを分ける識別面として、青い境界線と赤い境界線があります。
SVMでは境界線に近い点との距離(マージン)を最大化する境界線を識別面として選択するので、例の場合だと赤い境界線が識別面となります。
2. 問題設定
データ
- イタリアのある地方から取れた3つの異なる等級のワインに関する情報
- 13個の特徴量を含む178個のデータ
| 特徴量 | 説明 |
|---|---|
| Class | ワインの等級 |
| Alcohol | アルコール |
| Malic acid | リンゴ酸 |
| Ash | 灰 |
| Alcalinity of ash | 灰のアルカリ性 |
| Magnesium | マグネシウム |
| Total phenols | フェノール類全量 |
| Flavanoids | フラボノイド |
| Nonflavanoid phenols | 非フラボノイドフェノール類 |
| Proanthocyanins | プロアントシアニン |
| Color intensity | 色彩強度 |
| Hue | 色調 |
| OD280/OD315 of diluted wines | 蒸留ワインのOD280/OD315 |
| Proline | プロリン(アミノ酸の一種) |
課題
各ワインのデータには1から3の等級が割り当てられています。このうち2つの等級のデータに対して、SVMを使ってそれぞれの等級のワインを分類する識別器を作ってみましょう。
また、今回はすべての特徴量を使って分類するのではなく、特徴量の中から任意の2つの特徴量を選択して、それらを使ってSVMを構築してみてください。
3. scikit-learnを使ったSVM
データの読み込み
import pandas as pd
df = pd .read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data', header=None, sep=',')
df.columns = ['Class', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols', 'Flavanoids',
'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines', 'Proline']
df_selected = df[df['Class'].isin([1, 3])] # 等級1,3のデータのみ使う
df_selected.head()
散布図を描く
以下のように散布図を描いて、うまく線形分類できそうな2つの特徴量を選択してください。
import matplotlib.pyplot as plt
df1 = df[df['Class'].isin([1])]
df3 = df[df['Class'].isin([3])]
xlabel = 'Alcohol'
ylabel = 'Proline'
plt.scatter(df1[xlabel].values, df1[ylabel].values, c='r')
plt.scatter(df3[xlabel].values, df3[ylabel].values, c='b')
plt.show()
特徴量の抽出
X = df_selected[['Flavanoids', 'Hue']].values
y = df_selected['Class'].values
トレーニングデータとテストデータの分割
あとでモデルの評価を行うため、データをトレーニング用とテスト用に分割しておきます。
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
SVMでクラス分類
scikit-learnのSVC(Support Vector Classifier)を使うと、簡単にSVMを用いた識別器を作れます。
from sklearn.svm import SVC
svm = SVC(kernel='linear', C=1.0, random_state=0)
svm.fit(X_train, y_train)
y_pred = svm.predict(X_test)
-
kernelに指定されたlinearは、線形カーネルを表す -
Cは誤分類をどこまで許容するかのパラメータ
評価
from sklearn.metrics import accuracy_score
# 誤分類の数
print('Misclassified samples: %d' % (y_test != y_pred).sum())
# 正しく分類された割合
print('Accuracy: %.2f' % accuracy_score(y_test, y_pred))
# 決定係数
print('R: %.2f' % svm.score(X_test, y_test))
ここでデータと境界面をいっしょに描画してみましょう。
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1 # 最小値の取得
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1 # 最大値の取得
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, .02),
np.arange(x2_min, x2_max, .02))
Z = svm.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4) # 等高線の表示
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
plt.scatter(x=X[y == 1, 0], y=X[y == 1, 1], c='b')
plt.scatter(x=X[y == 3, 0], y=X[y == 3, 1], c='r')
plt.show()
4. 問題
- 以下の変更を加えて、SVMの挙動を確認してください。
- ワインの等級
- 抽出する特徴量
- カーネル
kernel - コストパラメータ
C
- 以下のデータはスイス銀行の紙幣のデータです。SVMで本物と偽物の紙幣を識別するモデルを作成してください。
http://mo161.soci.ous.ac.jp/@d/DoDStat/sbnote/sbnote_dataJ.xml