リアルタイムに物体検出するのってどうやるんだろう?と思い調べてみたら、想像以上に高機能なモデルが公開されていたので試してみました。こんな感じです。

自動運転で良く見るようなリアルタイムの物体認識をしています。このモデルは「Single Shot MultiBox Detector(SSD)」という深層学習モデルで、Kerasで動いています。
環境さえ整えればレポジトリをクローンして簡単に実行できます。今回はデモの実行方法をまとめてみます。
環境
ちょっと古いiMacにUbuntu16.04を入れたものを使いました。詳しくはこのへんとかこのへんをご参照ください。
SSD: Single Shot MultiBox Detector
深層学習を利用したリアルタイムの物体検出は次々と新しい技術が公開されているようです。ざっと調べたところ、R-CNN、Fast R-CNN、Faster R-CNN…。どれだけ早くなるねん。って感じですが、とにかくどんどん早くなっている様です。今回試してみたSSDというモデルはそれらと比較してももっと速い。というモデルだそうです。
もとはCaffeで実装されています。モデルに関しては、スライドを見ても全くわからなかったので解説動画をみてみました。
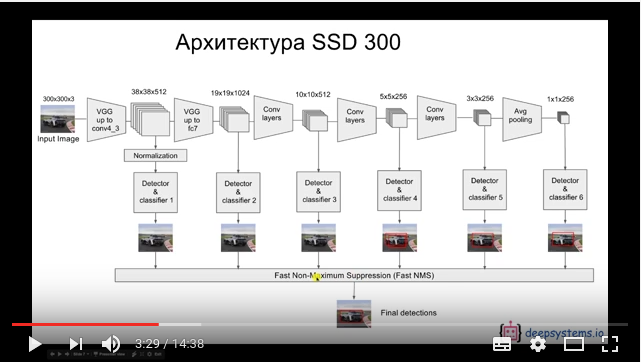
SSD: Single Shot MultiBox Detector (How it works) -YouTube
畳み込みニューラルネットワークと並行して

SSD: Single Shot MultiBox Detector (How it works) -YouTube
別の処理をしているようです。画像全体の検出位置をスライドしながら物体認識を並行して行っているのでしょうか。
ここは「すごーい」とだけつぶやいて、まずはデモを試してみることにします。
ssd_keras
上記のモデルをKerasで実装したものが公開されています。
こちらのレポジトリ、学習済みモデルがダウンロードすることが出来るので長い学習時間を掛けずにすぐにデモを試してみることが出来ます。
実際にやってみましょう。
$ git clone https://github.com/rykov8/ssd_keras.git
$ cd ssd_keras
まずレポジトリをクローンした後に、学習済みモデルをダウンロードします。
weights_SSD300.hdf5をダウンロードし、ホームディレクトリに置きます。
picsフォルダにサンプル画像があるので、自分の試してみたい画像を設置します。

$ jupyter notebook
私はジュピターノートブックを開いて、SSD.ipynbをコピペしながら試してみました。

ラベルは21種類ですね。画像のパスを自分の認識させたいものに変更して実行してきます。
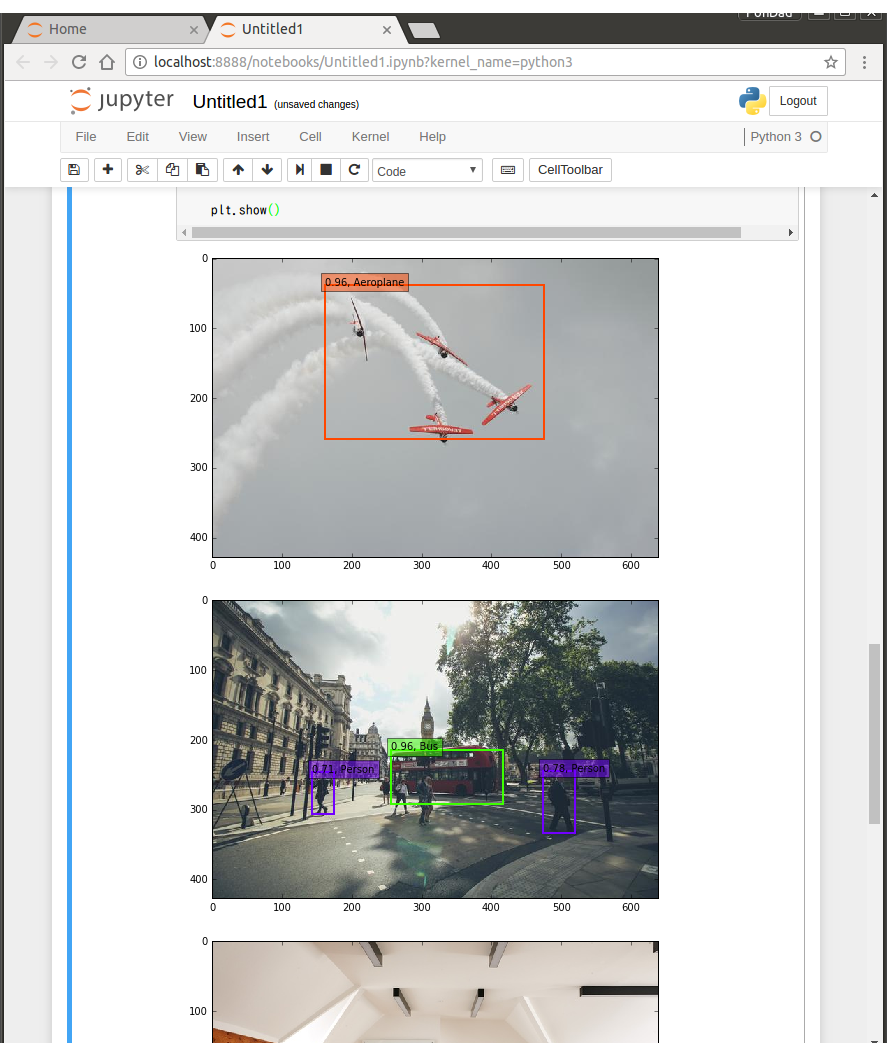
飛行機とかバスをきちんと認識しています。

椅子とか、ダイニングテーブル、モニターなんかも認識しています。
リアルタイム物体検出
OpenCV3.1を利用したリアルタイム物体検出のサンプルも試すことが出来ます。
$ cd testing_utils
$ python3 videotest_example.py
で実行できます。1箇所エラーコードがあるのでそこは修正してください。
# 87行目
vidw = vid.get(cv2.cv.CV_CAP_PROP_FRAME_WIDTH)
vidh = vid.get(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT)
# 以下に修正してください
vidw = vid.get(cv2.CAP_PROP_FRAME_WIDTH)
vidh = vid.get(cv2.CAP_PROP_FRAME_HEIGHT)
これで動くはずです。物体検出は同じファイルの65行目を見ると、60%以上で正と判断しています。
物体検出結果をコンソールでも確認したい場合は
# 162行目に以下を追加
print(text)
これで確認することが出来ます。
動画ファイルの指定はvideotest_example.pyで行えます。
# 24行目
vid_test.run('path/to/your/video.mkv')
このビデオパスを任意のものに指定します。OpenCVはffmpegを有効化して動画の読み取りが出来るようにしておきます。
やってみた
以下のフリー動画サイトよりいくつか動画をダウンロードして試してみました。

重なりあう人に紛れた車をきちんと検出しています。

こちらも重なりあう自転車と、ランニングする人を検出しています。よく足だけで人と判断できるなと思いますが。

ダイニングテーブル、椅子、手から人物を検出しています。

モニター、椅子の後ろに見える人物も検出しています。学習モデルは画像サイズ300x300で学習している様ですが、かなりの精度だと思います。
まとめ
「高速」といったものの、画像認識は2~3FPS(毎秒2~3フレーム)と少々残念な結果ですが、これは私の環境(iMacのGPUを使用)での結果なので、高性能なGPUを使えばもっと速くなると思います。
転移学習を使って自分の用意した画像も学習させてみたいですね。ではまた。