これは リクルートライフスタイル Advent Calendar 2016 の23日目の記事です。
註:この記事はまだ「個人的に注目の研究たち」の節が書きかけです。随時更新してく予定です。予定。うん。あとは画像も追って追加していきたい。
この記事は何?
ども、データエンジニアリンググループで主にログ収集・解析基盤の面倒を見ている tmshn と申します
この記事は、私が機械学習のトップカンファレンスである NIPS に参加して感じたことや注目した発表などを共有するものです。
機械学習の研究界隈の最新の動向について把握するのに役立つかも知れ……いや、うーん、やっぱ役立たんかも。私の所属するグループ※の特性上、「機械学習における研究とアプリケーションの橋渡し」 という観点で見ていただいた方がいいかも知れませんね。
※ 弊グループがどんなグループかについては、6日目の _stakaya さんの記事 を御覧ください
NIPS とは?
正式には "Conference on Neural Information Processing Systems" という、30年の歴史を持つ国際学会。今では機械学習(特に理論寄り)のトップカンファレンスの1つに数えられます。
実はもともとニューラルネットの学会として発足したもので、近年の深層学習の隆盛である種の「原点回帰」を果たしたのは数奇な奇跡/軌跡ですね!
数ある機械学習系学会の中での立ち位置
これは、産総研の神嶌敏弘さんがまとめられている "ML, DM, and AI Conference Map" という図が分かりやすいので下に引用します。
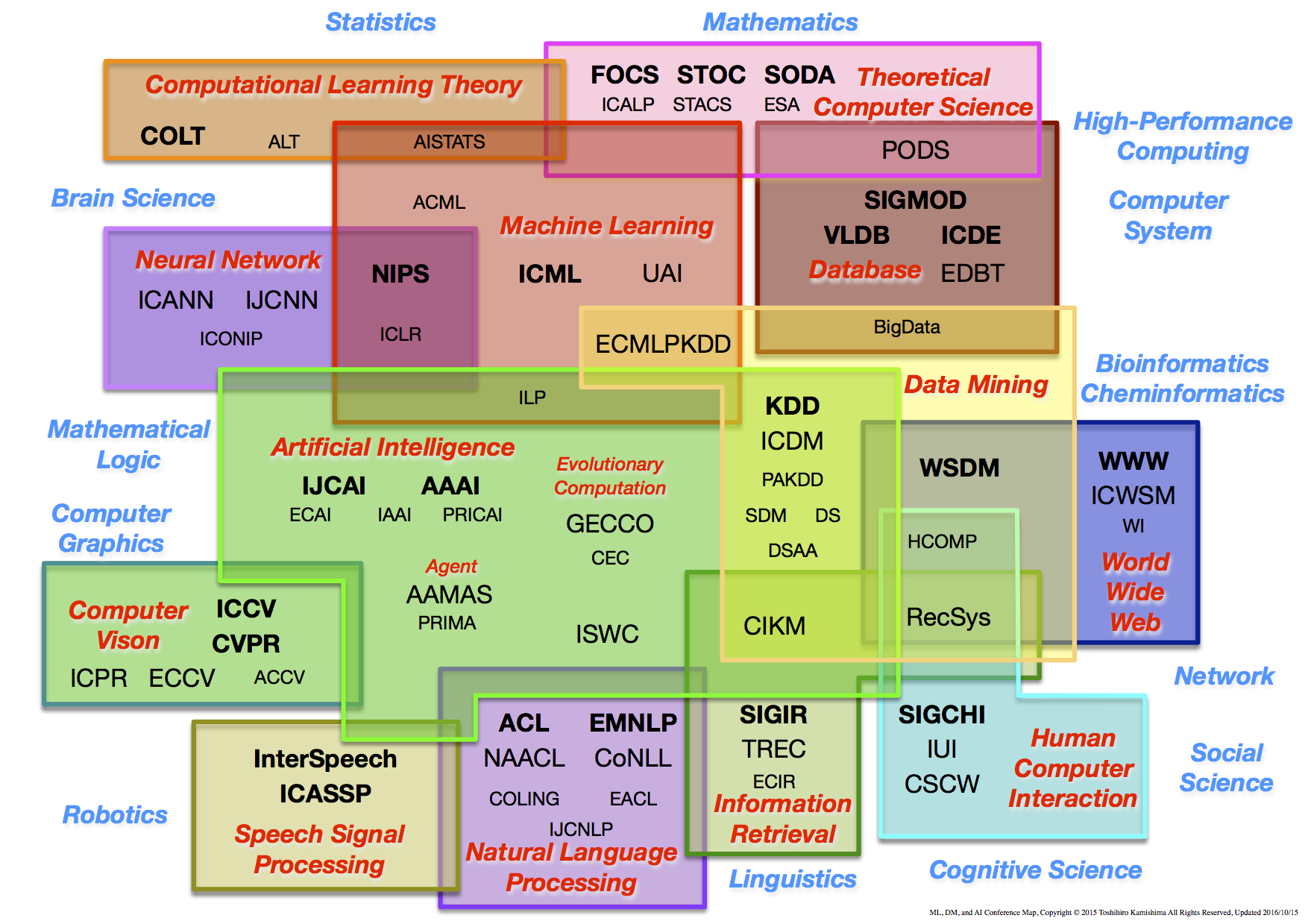
From Software and Data Sets | Toshihiro Kamishima
ちょっと数が多くて見づらいですが、NIPS が左上の方で Neural Network と Machine Learning というカテゴリに入っているのが分かりますね。
Data Mining カテゴリに入っている WSDM や KDD といった学会よりも青字で Statistics, Brain Science などと書かれた方に近いのが特徴かと思います。
今年の NIPS
今年の NIPS は、スペインはバルセロナで12月5日(月)から12月10日(土)までおよそ1週間に渡って開催されました。
機械学習ブームの中で年々参加者が増え、今年は5000人超だったとか(6000人だったという人も?)。
「早くチケットを買わないと売り切れる」なんて連絡が回ってきて慌てて購入したくらいで、実際にチケットが買えずに悔しい思いをした人も多かったようです。
そのせいもあるのか、例年シングルトラックだったのが今年はマルチトラックでした。
今年のトピックは下記ツイートに端的にまとまっています:
NIPS 2016 trends: learning-to-learn, GANification of X, Reinforcement learning for 3D navigation, RNNs, and Creating/Selling AI companies
— Tomasz Malisiewicz (@quantombone) 2016年12月10日
個人的な感覚としても、GAN(深層学習による生成モデルの一種)の話と強化学習の話(3Dナビゲーションに限らずですが)はかなり多かったかな、という印象です。
一方で最適化・行列分解・クラスタリングといった話をやり続けている方もかなりたくさんいたようで、時流に乗らずともきちっと評価される研究が出てくるのがいいなと感じました。
併せて読みたい
さて、本題に入る前に、既にインターネット上に公開されている今回の NIPS の参加報告記事などへのリンクを紹介したいと思います。
-
NIPS 2016 Proceedings
- 公式の proceedings (論文集)。全部読めます
(大学等の研究機関に所属してない身としては超ありがたい!)
- 公式の proceedings (論文集)。全部読めます
-
しましまのNIPS2016まとめ - Togetterまとめ
- 先にも名前の出た神嶌さんによる参加者のツイートまとめ。会場のライブな空気感が伝わってきます。
-
NIPS 2016参加報告 - Qiita
- おそらく本記事執筆時点で Qiita 上唯一の NIPS 2016 参加報告(個別の論文の紹介等は既に上がっている/これから上がると思いますが)。深層学習周りの雰囲気がつかめます。
-
NIPS 2016 - Andrew L. Beam
- Harvard のポスドクの方による参加報告(もちコース英語です)。実際に会場で話題になっていたことがまとまっていて良い記事です。
-
NIPS2016.md - artsobolev’s gists
- まとめ記事のまとめ。ほとんど見られていないのですが、まぁたぶん全部イングリッシュ。
ためになったチュートリアルたち
Nuts and Bolts of Building Applications using Deep Learning ― Andrew Ng
スタンフォード大・Baidu 社の Andrew Ng による、機械学習を用いたアプリケーションを作るためのガイドライン。
エンジニアとして大変ためになるチュートリアルでした
なんと5000人の聴衆を前にホワイトボードに板書しながら進めていく講義スタイルでかっこよかったのですが、字が汚すぎて大変達筆でいらっしゃって、一生懸命聞きながらじゃないと全然読めないマジつらい。
話は主に下記の3点:
- 深層学習のトレンド:
- 旧来の機械学習はデータ量が増えても精度がある程度のところでサチるが、(特に大規模ネットワークによる)深層学習はそれがちゃんと「スケール」する
- End-to-end 学習(前処理かけたり複数のモデルを組み合わせたりすることなく、入力と出力の関係を直接単一のモデルで学習すること)が今後複雑なデータでも一般的になる
- 訓練データセットとテストデータセットの分布が違う場合のバイアス/バリアンスの考え方
- どうしても大量の訓練データが手にはいらない場合、訓練データを人工的に生成したり、類似のデータセットを使うケース(たとえば自動車内の音声認識の学習に、スタジオ録音の音声を訓練データに使うなど)が増えてくる
- 詳細はスライド参照
- 「医療画像認識におけるヒューマンレベルエラーとは、次のうちどれ? 1.素人、2.普通の医者、3.熟練の医者、4.熟練の医者のチーム」という問題で会場のみんなに手を挙げさせたりしていた(だいたいの人があっていたので Ng 先生は喜んでいた)(答えはスライドをご確認ください)
- AI プロダクトにおけるプロダクトマネージャとエンジニアの役割分担
- プロマネがテストデータセットと評価指標を用意して、エンジニアが訓練データの収集とシステム開発を行う、という提案
-
汚い達筆な字で板書しながら「読めなくても安心して! 『Andrew がこんなこと言ってたよ』って同僚や上司に見せるためのスライドはあとで公開するから!」って言ってた
あとは学生向けに、前処理とかデータクレンジングとか大変だろうけど、そういう汚れ仕事をちゃんと自分でやるのも大事だという旨のアドバイスもしていました。
Generative Adversarial Networks ― Ian Goodfellow
今年の最大のトレンドである GAN (Generative adversarial network) について、考案者である Ian Goodfellow 本人による大変わかりやすいチュートリアルがありました。
そもそも GAN というのは深層学習を用いたデータの生成モデルで、データの分布も明示的に扱わずマルコフ鎖も使わないのが特徴です。
GAN は実際にデータを生成する generator というモジュールと、データが真のデータなのかどうかを見分けようとする discriminator というモジュールを組み合わせたものなのですが、それらの関係を偽札師と警察の関係に喩えた比喩が分かりやすかったです。
またこの発表ではとある「一悶着」がありました。
それは、Jürgen Schmidhuber (LSTM 考案者)が「それは私の○○という研究と関係があるのか?」というような質問で割り込んできたことです。
他の参加者の方に教えてもらったのですが、この Schmidhuber という方は Bengio, Hinton, LeCun のいわゆる「ディープラーニング三聖」が深層学習の関する手柄を不当に独占していて、先行研究に十分な敬意を払っていないという問題提起をずっと続けているんだそうです(本人の主張については こちら が詳しい)。
とは言え聴衆としては知ったことではないですし、チュートリアルの邪魔をするなという反応が多かったようです(たとえば下記ツイート)。個人的には、会場がけっこうザワザワしていて面白かったです。
Schmidhuber interrupted the GAN tutorial, stealing time from those listening & learning. I don't care who you are, don't do that.#nips2016 pic.twitter.com/NqCHkAynCm
— Smerity (@Smerity) 2016年12月5日
※ 後で気づきましたが、このツイート主さんは 「LSTMを超えたか!?」と今話題 の QRNN のセカンドオーサーでした。
個人的に注目の研究たち
まだちゃんと論文にまでは目を通せていないのですが、オーラル発表・ポスター発表で個人的に「おっ」と思ったものをバシバシ紹介していきたいと思います。
深層学習篇
Learning What and Where to Draw ― Scott Reed, et al.
GAN を用いた画像生成で、タイトルにある通り「どこに何を描くか」を指定できるようにするという研究です。「どこに」の部分は長方形の領域指定かキーポイントの指定で、「何を」の部分はテキストで指定できるようです。
サンプルで提示されている結果がすごく綺麗で「もうこんなことが出来るのか」とけっこう驚いた一方で使われているネットワーク構造がかなり複雑で「こんなものよく思いついたな」とも感じました(実際に会場からも「もうちょっとシンプルな構成ではできなかったのか?」みたいな質問があったくらいです)。
ただそれがどんなに複雑で「そんなの思いつかねーよ」という構成でも、逆に言えばその構成を発見/発明してくれた功績は大きいわけで、そういう意味でも良い研究と言えるんじゃないかなーと思いました。
Learnable Visual Markers ― Oleg Grinchuk, et al.
こちらも画像生成系の話ですが、これは QR コードのようなビジュアルマーカーを入力テクスチャ画像に馴染むような形で生成するという研究。
GAN を使っているわけではないようですが、マーカーをデコードする recognizer が GAN でいう discriminator と似た役割を果たしているのかも?と思いました。
今すぐ「コレに使える」というのがあるわけではないですが、応用先を色々と妄想できる楽しい研究ですね。
Phased LSTM: Accelerating RNN Learning for Long or Event-based Sequences ― Daniel Neil, et al.
こちらは LSTM に明示的にいろんな周波数のクロックゲートを追加することで、長いシーケンスや、色々な記録周波数のデータに対して高精度を達成したという研究。
センサーネットワークなどでは個々のセンサーの記録周波数がまちまちで、それらを統合して学習するのは難しそうなのですが、このモデルはそういった状況に対応できるということで頼もしいです。
また、ゲートは閉まっている時間のほうが長いので、ドロップアウト同等の正則化効果があるということも言っていました。
Hierarchical Question-Image Co-Attention for Visual Question Answering ― Jiasen Lu, et al.
与えられた画像について質問に答える Visual Question Answering の問題設定で、画像のアテンション(どこに注目すべきか)とともに質問のアテンション(どの言葉に傾聴すべきか)を学習するという研究。
質問に関しては文章レベル・句レベル・単語レベルの3段階の階層を導入したとのことです。
自分はこのトピックの研究がどのくらい進んでいるのか分からないので正当な評価はできませんが、コントリビューション部分の拡張の仕方も自然だし、サンプルの結果もきれいで納得感の高い研究でした。
Learning values across many orders of magnitude ― Hado van Hasselt, et al.
オンライン学習や強化学習では一般に、入力値のスケールが事前に分かっていない(最初のデータと後から来るデータのオーダーが違うなど)と学習が大変だったり、モデルの挙動が後から変わってしまったりといった問題がありました。
これに対し、都度うまく正規化をかけていくことでこの問題を解決したのがこの研究です。
パックマンなどのゲームでの応用例が紹介されていましたが、Web データの学習でも同様の問題は起きうるので大変有意義な研究だなと思いました。
Deep Learning without Poor Local Minima ― Kenji Kawaguchi
線形な、または ReLU を活性化関数に用いた深層学習モデルには「悪い局所最適」は存在しないけれど、「悪い鞍点」は存在するという研究です。
ここで言う「悪い局所最適」とは大域最適よりも悪い局所最適のことで、逆に言えば、それが存在しないということはすべての最適値が大域最適値に等しいということです。
一方で「悪い鞍点」というのはヘッセ行列が負の固有値を持たない、ということのようです。
現在実際に用いられている深層学習のモデルのほとんどはこの研究が扱うものよりずっと複雑なので、そういう意味ではまだまだ応用の領域まではギャップがありますが、深層学習の理論解析としては重要な一歩になっていると思います。
また著者は日本人で MIT の博士学生ということで、個人的には NIPS に学生が単著で通すってものすごいことだなと感じました(どうやら AAAI にも単著で通していたりと、他の業績もけっこうスゴイ)。
レコメンデーション篇
Deconvolving Feedback Loops in Recommender Systems ― Ayan Sinha, et al.
実際のサービスにおけるレコメンデーションは、普通1回で終わりではなく継続的に行われるものです。
そうすると、ある時点で協調フィルタリングなどで利用する評価行列は、「それ以前のレコメンド提示によって変わった評価」が含まれているわけで、ユーザの評価とレコメンドシステムの間でフィードバックループが形成されています。そうして、やがてそのレコメンドシステムのバイアスが評価行列には蓄積されていってしまいます。
このバイアスを教師無しで補正するというのがこの研究です。
手法としては観測された評価行列を特異値分解することで、ユーザからの真の評価行列が得られるというものでした。
このように継続的な観点でレコメンドシステムを見る視点と、「真の評価行列をもとにレコメンデーションを出すべき」という提案は非常に自分にとって有意義でした。
一方で実際の応用を考えると、レコメンドを出す側はいつ誰にどんなアルゴリズムでアイテムを提示したかは分かっているので、教師ありでより高い精度でこれを実現できるのかも知れないなとも思いました。
Data Poisoning Attacks for Factorization Based Collaborative Filtering ― Bo Li, et al.
【書きかけ】
悪意のあるユーザが意図を持ったコンバージョンをすることで、協調フィルタリングの元データを「汚染」することができるよという研究。
汚染手法もいくつか提案していて、ある程度ナイーブなやつは t 検定で発見できるが、通常ユーザへのなりすましまでされたら検出するのは難しいという話だった。
ただし、この「通常ユーザへのなりすまし」をするには推薦システムの内部情報を知っていないといけないので、現実的ではないよね、とのこと。
というか、そもそも悪意のあるデータを注入するには(ハッキングするとかならともかく)「実際にコンバージョン」しなきゃいけないわけだから、それほど警戒する必要はないのかも?という気もした。
Matrix Completion has No Spurious Local Minimum ― Rong Ge, et al.
【書きかけ】
Deep learning の方であった「『悪い』局所最適がないよ」研究の行列補完版。
こんな似た研究がかぶるなんて偶然なのか、けっこうよくある話なのか僕にはちょっと判断できかねる。
でもこれも重要な研究だなと思いました。
最適化篇
Minimizing Quadratic Functions in Constant Time ― Kohei Hayashi, et al.
タイトルの通り、2次関数を次元数に対して定数時間で(近似)最小化するという研究です。
手法としては行列要素をサンプリングしてその小さい行列を最小化するというものなのですが、このサイズの違う行列間の類似度の計算が肝になります。
この研究では、行列を graphon (グラフの極限を取って連続化したような何か)の空間に埋め込むことでこれを達成し、手法の正当性を証明することに成功しています(全然分かってない)。
全然時流に乗っていないもののかなり有用な研究だなと思ったのと、「定数時間」という変態的な成果を達成するために難しい理論が出てくるところが好きです。いいですよね、定数時間。
それから、こちらも日本人(産総研の方と NII の方)の研究でした。
Large-Scale Price Optimization via Network Flow ― Shinji Ito, et al.
【書きかけ】
ネットワークフローを用いた価格最適化の話。
これも時代の流れに全然乗ってないけどオーラル発表までしていてかっこいい。
これも日本人の研究。NEC!
英語がたどたどしく、質問の人もすごく優しい英語だったのが記憶に残っている。
やっぱり難しいよなぁ、僕も発表は出来ても質問には答えられる気がしないです。
そういえば関係ないけどスポンサーに Panasonic 入ってた。
A Communication-Efficient Parallel Algorithm for Decision Tree ― Qi Meng, et al.
【書きかけ】
決定木の効率的な並列学習手法。なんならいま一番使われてますからね、決定木系のアルゴリズム。
教師あり学習篇
General Tensor Co-Clustering for Higher-order Data ― Tao Wu, et al.
【書きかけ】
今日クラスタリングを一般のテンソルにまで拡張した。
もともと対称テンソルまでは手法があったらしい。
Supervised Word Mover's Distance ― Gao Huang, et al.
【書きかけ】
Word mover's distance を教師ありで学ぶという一種の metric learning。
word mover'd distance というのは聴いたことがなかったけど、たぶん earth mover's distance と関連のある何らかの距離尺度なのだと思う。
ものの評価指標とか類似度基準というのは実世界ならユーザによって当然変わるはずで、そこをきちっと反映できる手法というのは個人的にけっこう関心がある(自分の修士時代の研究もそれに近い話だったので)。
その他
Fast and Provably Good Seeding for k-Means ― Olivier Bachem, et al.
タイトルの通り、k-means アルゴリズムに対する「良い」初期化方法の研究です。
k-means においては初期化がクラスタリング結果の善し悪しを左右しますが、現在最も良いとされる k-means++ ではデータ量・クラスタ数の増加に対してスケールしないため、もっと効率的な手法を提案しています。
正直 k-means をまだ研究している人がいてまだ改善の余地があるんだ、というのが驚きでした。
また、どんなデータセットでもうまくいくよと主張しているのと、Python のライブラリとしてすぐ使えるよう整備されている(pip でインストールできる/scikit-learn とも互換性あり)のが素晴らしく、使ってみたくなりました。
Man is to Computer Programmer as Woman is to Homeworker? Debiasing Word Embedding ― Tolga Bolukbasi, et al.
Word2vec のような単語のベクトル空間モデルを使うと「東京:日本↔パリ:フランス」という関係性が抽出できます。
ところがこれを応用すると「男性:建築士↔女性:インテリアデザイナ」「男性:保守主義↔女性:フェミニズム」のような、学習データに潜む「男女に対しての言葉の使われ方の違い」が暴かれる、というのがこの研究です。
さらには盲目的な機械学習の適用はこのバイアスを加速させかねないとして、それを補正する手法も提案しています。
現実社会をちゃんと見据えた研究で好感が持てました。
いかがだったでしょうか。
当初の予定よりもかなり長くなってしまいましたが、読者の皆様がこの中から面白そうなものを見つけていただければ拙者は幸いで御座りまする。
私自身も、ここで学んだことを普段の業務にうまく活かして行きたいと思います。
やっていき〜〜〜