去る1993年、『DOOM』がゲームデザインやゲームメカニクスに根本的な変化をもたらしました。これは世界的な現象となり、John CarmackやJohn Romeroなど、開発に関わった象徴的な存在の名声を広げました。
それから23年が経った現在、id SoftwareはZenimaxの傘下に入り、当初の創設者は会社から全員去りました。しかし、かつてid Softwareに属していたチームは最高のゲームを作り、変わらずに優秀であることを示しました。
この『DOOM』は非の打ちどころのないシリーズ最新作となりました。使用されているid Tech 6 engineについては、元Crytekの社員だったTiago SousaがJohn Carmackから引き継いだ部署のレンダラプログラマを率いて取り組んでいます。
歴史的には、id Softwareはエンジンをオープンソース化して数年で、そのエンジンで有名になりました。このエンジンは数多くの出来のいいリメークや分析などへとつながったのです。今後もこの状態がid Tech 6 engineに当てはまるかは後にならなければ分かりません。しかし、エンジンに実装された素晴らしいグラフィックス技術を高く評価するために、ソースコードが必要とは限りません。
フレームのレンダリング手法
ゲームの冒頭でプラエトルスーツを手に入れた直後に、ポゼスドという敵が守るゴアネストをプレーヤーが攻撃する以下の場面を検証してみましょう。
近年公開されている大半のWindowsゲームとは異なり、DOOMではDirect3Dを使わずにOpenGLやVulkanのバックエンドを提供しています。
Vulkanが新しい流行のAPIとなり、最近になってBaldur KarlssonがRenderDoc内にVulkanのサポートを追加したため、DOOMも必然的にVulkanを取り入れることとなりました。次の所見は、全てをUltraに設定したGTX 980上でVulkanを使って実行しているゲームに基づいていますが、中には推測やTiago SousaとJean GeffroyがSiggraphで発表した内容からの抜粋も含まれます。
メガテクスチャのアップデート
最初のステップはメガテクスチャのアップデートです。これはRAGEで使われたid TECH 5に既に存在する技術で、今ではDOOMでも使われています。
それぞれが128×128タイルのセットである数個の大きなテクスチャ(DOOMの場合は16k×8k)をGPUメモリに割り当てるというのが、とても基本的な考え方です。
128×128ページある16k×8kのストレージ
これらのタイルは全て、適切なミップマップレベルにおける実際のテクスチャの理想的なセットを示しているはずです。注目されている一部分を表示するために、後でピクセルシェーダはミップマップレベルを必要とします。ピクセルシェーダが”仮想テクスチャ”から読み取る際は、最終的に単純に128×128の物理的タイルからの読み取ることになります。
当然ですが、プレーヤーがどこを見ているかにより、このセットは変化し、画面上に新しいモデルが表示されます。他の仮想テクスチャを参照することで、新しいタイルが入り、古いタイルは出て行くはずです。
フレームの最初で実際のテクスチャデータをGPUメモリに加えるために、DOOMはvkCmdCopyBufferToImageを通して幾つかのタイルをアップデートします。
シャドウマップのアトラス
それぞれの光が影を投じるために、固有の深度マップが生成され、巨大な8k×8kのテクスチャアトラスの中の1つのタイルに保存されます。しかし、各フレームの各深度マップが全て計算されるわけではありません。DOOMでは以前のフレームの計算結果を再利用し、アップデートの必要がある深度マップのみを再生成します。
8k×8kの深度バッファ
(前のフレーム)
8k×8kの深度バッファ
(現在のフレーム)
ライトが静的で影が静的なオブジェクトにしか落ちないとしたら、不必要な再計算をせずに、そのままの深度マップを単純に保持するのは納得できます。しかし、数体の敵がライトの下を動いているとしたら、再度、深度マップを生成しなければいけません。
深度マップのサイズは、カメラからライトの距離にも大きく左右されるため、再生成された深度マップはアトラス内の同じタイルの中に留まるとは限りません。
DOOMは、深度マップの静的な部分をキャッシュし、動的なメッシュの投影のみを計算し、結果を構成するというような、特別な最適化機能を備えています。
深度プレパス
これで、深度の情報が深度マップに出力され、不明瞭なメッシュは全てレンダリングされます。最初はプレーヤーの武器、次に静的なジオメトリ、そして動的なジオメトリという順番です。
深度マップ:進捗率20%
深度マップ:進捗率40%
深度マップ:進捗率60%
深度マップ:進捗率80%
深度マップ:進捗率100%
しかし実際には、深度プレパスの間に出力される情報は深度だけではありません。
動的なオブジェクト(ポゼスド、ケーブル、プレーヤーの武器)が深度マップにレンダリングされる間にピクセル単位の速度も計算され、それが他のバッファに書き込まれてベロシティ(速度)マップが生成されます。これは頂点シェーダ内の計算によって行われ、以前のフレームと現在のフレームの間の各頂点の位置の差が測定されます。
ベロシティマップ
ベロシティマップ
速度を格納するのに必要なのは2つのチャネルだけです。赤は水平軸に沿った速さで、緑が垂直軸に沿った速さです。
ポゼスドは素早くプレーヤーに向かってきていますが(緑)、武器はほとんど動いていません(黒)。
黄色の(赤と緑の両方が1に等しい)領域は何でしょうか。実はバッファのもともとのデフォルトの色で、これまで動的メッシュに触れられていないということを示しています。全て“静的メッシュ領域”です。
なぜDOOMでは静的メッシュに対する速度の計算を省いているのでしょうか。それは、静的なピクセル速度は、深度や、最後のフレーム以降のプレーヤーのカメラの新しい状態から簡単に推測できるので、メッシュごとに計算する必要がないからです。
ベロシティマップは、後でモーションブラーを適用する際に役に立つでしょう。
オクルージョンクエリ
ボックステスト
赤:遮られている
緑:見えている
私たちはできるだけ小さなジオメトリを送ってGPUにレンダリングを行いたいと考えます。それを達成するための最善策は、プレーヤーからは直接見えないメッシュを全てえり分けることです。DOOMでのオクルージョンカリングのほとんどはUmbraミドルウェアを介して行われますが、それでもまだ、見えている領域のセットをさらにスリム化するために、エンジンによるGPUオクルージョンクエリが行われます。
では、GPUオクルージョンクエリの背後にある考えは何でしょうか。
最初のステップでは、ワールドにある複数のメッシュをそれら全てを取り囲む仮想ボックスにグループ化し、GPUに現在の深度バッファに対してこのボックスのレンダリングを行うよう要求します。ラスタライズされたピクセルがどれも深度テストにパスしない場合、そのボックスは完全に遮られていて、ボックス内部にある全てのワールドオブジェクトはレンダリング時に安全に省略されるということになります。
問題は、これらのオクルージョンクエリ結果はすぐには利用できませんが、誰もクエリ上でブロックしてGPUパイプラインをストールしたくはないということです。通常、結果の読み込みは次のフレームで後から行われるので、オブジェクトが飛び出るのを防ぐために少し保守的なアルゴリズムが必要です。
不透明なオブジェクトのクラスタ化されたフォワードレンダリング
不透明なジオメトリとデカールは全てレンダリングされているものとします。ライティング情報はfloat型のHDRバッファに格納されています。
ライティング 25%
ライティング 50%
ライティング 75%
ライティング 100%
深度テスト機能は無駄なオーバードロー計算を防ぐためにEQUALに設定され、前述の深度プリパスのおかげで、各ピクセルが持つことになっている深度値が正確に分かっています。
デカールもメッシュのレンダリングが行われる際に直接適用され、テクスチャアトラスに格納されます。
もうこれで良さそうに見えますが、ガラスのような透明なマテリアルやパーティクルがまだです。まだ環境反射が全くありません。
このパスについて少し言及すると、使用されるのはEmil PersonとOla Olssonの仕事の影響で生み出されたクラスタ化されたフォワードレンダラです。
歴史的に、フォワードレンダリングの弱点の1つは多数のライトを処理することができないことで、もっとやりやすい方法で後から処理されます。
それでは、クラスタ化されたレンダラはどのように動作するのでしょうか。
まず、あなたがビューポートをタイル状に分割すると、DOOMは16×8のサブディビジョンを作成します。ここでやめて、タイルごとにライトのリストを計算するレンダラもあるでしょう。それはライティングの計算量を減らすのに役立ちますが、それでも何らかのエッジケースに悩まされます。
クラスタ化されたカメラの視錐台
クラスタ化されたレンダリングによって、その概念はさらに進み、2Dから3Dへ発展します。つまり、2Dビューポートを再分割した時点でやめずに、実際にZ軸に沿ってスライスを作成してカメラの視錐台全体の3D再分割を行います。
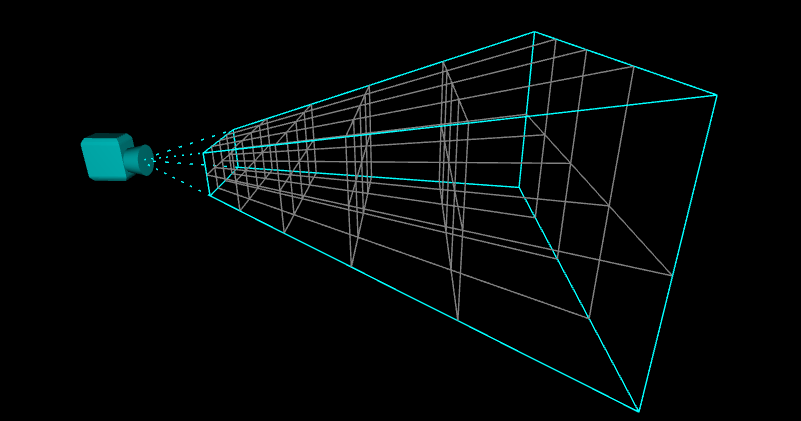
各”ブロック”は”クラスタ”と呼ばれます。あるいは、”錐台状の”ボクセルとも呼ばれています。
右の図は、シンプルな4×2のビューポートサブディビジョンを視覚化したもので、5つの深度スライスで錐台を40のクラスタに分割しています。
DOOMでは、カメラの視錐台は3072のクラスタ(16×8×24のサブディビジョン)に分割され、深度スライスはZ軸に沿って対数的に配置されています。
クラスタ化されたレンダラを使った典型的なフローは以下のとおりです。
-
まず、CPUで各クラスタ内部のライティングに影響するアイテムのリストが算出されます。ライト、デカール、キューブマップなどです。
それを行うために、これらのアイテム全ては”ボクセル化”されているので、それらの影響範囲がクラスタと交わっているかをテストすることができます。データは、シェーダがアクセスできるようにGPUバッファにインデックス付きリストとして格納されます。各クラスタは、ライト、デカール、キューブマップをそれぞれ256まで保持することができます。 -
次にGPUが1ピクセル、レンダリングする時は以下のことが起こります。
- そのピクセルの座標と深度から、それが属するクラスタが決定されます。
- 特定されたクラスタのデカール/ライトのリストが取り出されます。それは、下図に示すようなオフセットの間接参照とインデックスの計算を含みます。
- プログラムは、計算したり、寄与度を加えたりして、クラスタの全デカール/ライトの中をループします。
ここで、ピクセルシェーダが、このパスの間に、ライトとデカールのリストを実際にどうやって取り出せるのかを見てみましょう。
ライトとデカールの適用#1
注釈:
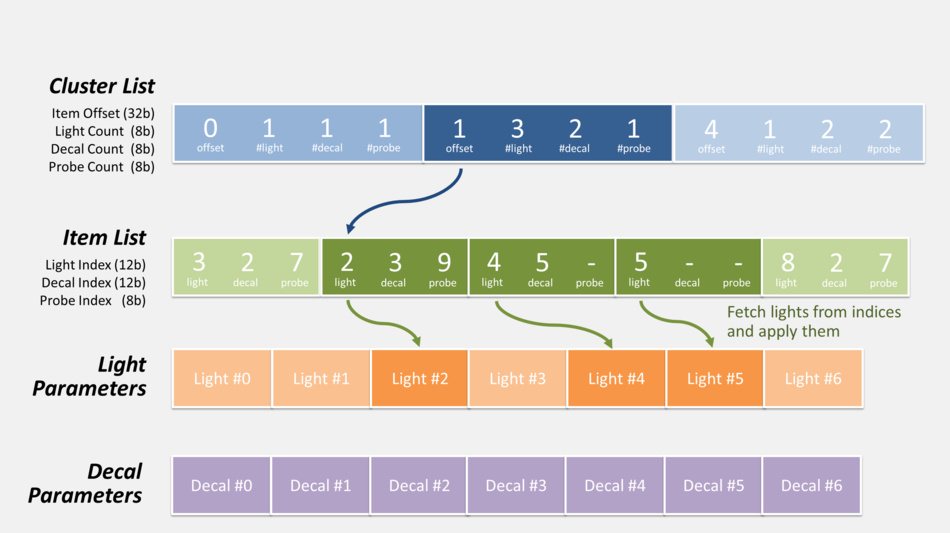
Cluster List:クラスタリスト
Item Offset (32b):アイテムオフセット(32b)
Light Count (8b):ライトカウント(8b)
Decal Count (8b):デカールカウント(8b)
Probe Count (8b):プローブカウント(8b)
Item List:アイテムリスト
Light Index (12b):ライトインデックス(12b)
Decal Index (12b):デカールインデックス(12b)
Light Parameters:ライトパラメータ
Decal Parameters:デカールパラメータ
注釈:
ピクセルのワールドスペース上の位置に基づくリスト上のクラスタ検索
ライトとデカールの適用 #2
注釈:
オフセット1からアイテムリストを検索して、3つのライトインデックスを読み込む
ライトとデカールの適用 #3
注釈:
インデックスからライトをフェッチして適用する
ライトとデカールの適用 #4
注釈:
オフセット1からアイテムリストを検索して、2つのデカールトインデックスを読み込む
ライトとデカールの適用 #5
注釈:
インデックスからデカールをフェッチして適用する
ライトとデカールの適用 #6
全く同じやり方でアクセスされるプローブリスト(上図には示されていません)もあります。しかし、そのリストはこのパスでは使われないので、その話は後にしましょう。
将来的にGPU上で、どれほど劇的にレンダリング計算の複雑さを軽減できるのかを考えると、CPU上でクラスタごとにアイテムのリストを事前生成するオーバーヘッドは、かけるだけの価値が十分あります。
クラスタ化されたフォワードレンダリングは、最近、若干の注目を集めています。基本的なフォワードレンダリングよりももっと多くのライトを扱う精密な特性を有すると同時に、幾つかのG-Buffer(ジオメトリバッファ)に対する書き込み、読み込みをしなければならないディファードレンダリングよりも速いという特性を持っています。
しかし、まだ触れていなかったことがあります。私たちが調べたこのパスは、ただ単にライトバッファに書き込むというフォワードレンダリングではありません。それが実行されている間にMRTを使って、2つのわずかなG-Buffersも生成されました。
法線マップ
スペキュラマップ
法線マップは、R16G16(赤16ビット、緑16ビット)のfloat型で格納されます。スペキュラマップはR8G8B8A8(赤、緑、青、アルファ各8ビット)です。アルファチャンネルは滑らかさの要素を含みます。
そこで、DOOMは実際にフォワードレンダリングとディファードレンダリングをハイブリッドアプローチでうまく調和させました。反射のような付加効果を実行するとき、これらの拡張G-Buffersは何かと便利です。
そして、最も忘れてはいけないのは、メガテクスチャシステムのための160×120のフィードバックバッファも、同時に生成されることです。ミップマップのレベルがどのテクスチャに流れ込むべきかをストリーミングシステムに伝えるための情報を含みます。
メガテクスチャエンジンは、反応性の高い動きをします。つまり、あるテクスチャが抜け落ちているというレンダーパスからのレポートを受け取ると、そのエンジンがテクスチャをロードします。
GPUのパーティクル
Compute Shaderは、位置、速度、寿命といったパーティクルシミュレーションを更新するようにディスパッチされます。
それはパーティクルの現在の状態のみならず、(衝突の検知のために)法線バッファと深度バッファを読み込みます。そして、シミュレーションステップを進め、バッファに新しい状態を戻して格納します。
スクリーンスペースアンビエントオクルージョン(SSAO)
SSAOマップ
このステップで、今度はSSAOマップが生成されます。
狭い境界や折り目などの周りで色を暗くすることが目的です。
遮へいされたメッシュ上に現れる、鮮明な光によるーティファクトを避けるためにスペキュラオクルージョンを適用するのにも使われます。
深度バッファ、法線マップ、スペキュラマップから読み込むピクセルシェーダでもともとの解像度半分と算出されます。
最初に得られる結果は、ノイズの多いものになります。
スクリーンスペース空間の反射(SSR)
今度はピクセルシェーダがSSRマップを生成します。これは、スクリーン上に現れている情報だけを使い、ビューポートの各ピクセル上で光線を反射させ、反射光があたるピクセルの色を読んで、反射をレイトレースします。
深度
法線
スペキュラ
前のフレーム
SSRマップ
シェーダの入力は、深度マップ(ピクセルのワールドスペースの位置を計算するため)、法線マップ(光線を反射させる方法を知るため)、スペキュラマップ(反射の”量”を知るため)、(透明処理後ではなくトーンマッピング前のステージで)レンダリングされた前のフレーム(幾つかの色情報を持つため)です。前のフレームのカメラコンフィギュレーションは、それがフラグメントの位置変化の経過を追うことができるように、ピクセルシェーダにも提供されます。
各シーンにおいて一定のコストで発生するリアルタイムのダイナミックリフレクションを備えるなら、SSRは優れた技術で、それほど高価ではありません。また没入感や臨場感を出すのにとても有効な手段です。
しかし、完全にスクリーンスペースの中で作業し、”グローバルな”情報が欠如しているという事実のために、それ自身が生み出すアーティファクトがつきものです。そのため、あなたはあるシーンで、素晴らしい反射を見ているかもしれません。しかし下の方を見るにつれ、反射の量が減少し、自分の足元を見る時には、反射が全く無くなります。DOOMのSSRは効果的に統合されていると思います。視覚的な質は改善しましたが、実際に集中して見ていなければ、アーティファクトが消えていることに気がつきかないほどかすかなものです。