2016-09-26
■どこに何が写ってるのか分かる人工知能 FasterRCNN勉強メモ 
FasterRCNNというのがある。
単純なCNN(Convolutional Neural Network)畳み込みニューラル・ネットワーク)のように「この写真は何の写真?」ということに答えるのではなく、「この写真のこれは何でそれは何」と答えるニューラル・ネットワークである。
もともとRCNNというのがあって、これはめちゃくちゃ遅かった。
次にFastRCNNというのが発明されて、これは少し早かったけどリアルタイム処理は難しかった。
さらに高速で、まあ気合を入れたらもしかしたらリアルタイムでもいけるかも?というのがFasterRCNNである。
これまであんまり仕事に使ってこなかったんだけど、どうも最近の案件はFasterRCNNを使ったほうが良さそうなものが増えてきて、まあさもありなんという感じである。
そもそもRCNN自体あんまり使ってなかったのでお勉強がてらソースコードを読んだり改造したりする。
まあただ使うだけなら、例によってすぐできる。
- GitHub - mitmul/chainer-faster-rcnn: Object Detection with Faster R-CNN in Chainer https://github.com/mitmul/chainer-faster-rcnn
Chainer実装の方がCaffe実装よりも使いやすいのでこれを出発点としてFasterRCNNを見てみるとする。
とりあえず適当な写真を見せる。

さあこれをFasterRCNNに見せるとどうなるか

バーン、ちゃんとどこに何があるのか認識してくれるのである。やったね。
さて、ところが一つ問題がある。
FasterRCNNが見つけ出せるものは基本的に「既に知っているもの」しかないということだ。
つまり、自分の求めるものを見つけさせたい場合は、自分でトレーニングする必要がある。
写真をただひたすら放り込めばいいCNNのトレーニングと違ってFasterRCNN(というかRCNN)は目的がはっきりしていないと学習用データセットを用意するのもしんどいのである。
さらにいうと、先のChainer実装にはトレーニングが実装されていなかった。
ので、自分でトレーニングを実装する必要がある。
するとFasterRCNNにどのようなデータを突っ込めばいいのかわからないと訓練しようがないのでFasterRCNNの構造を学ぶ必要がある。
まず、FasterRCNNの全体構造を見てみる。
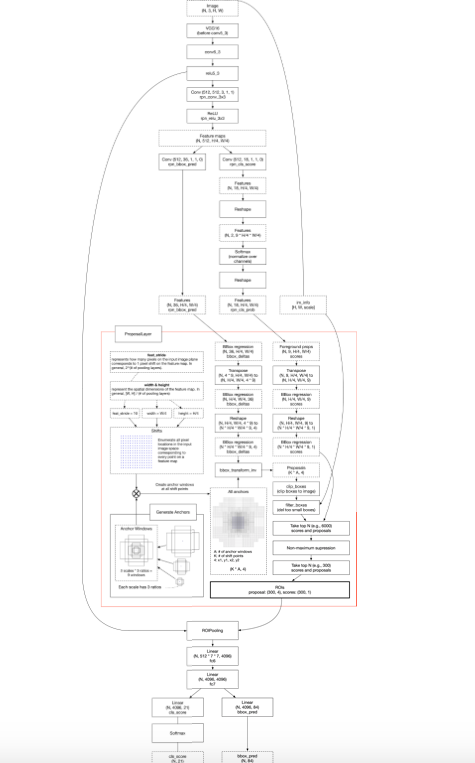
新しいタイプの嫌がらせのように細かい図になってしまう。全貌はこちらのページを参照 → https://raw.githubusercontent.com/wiki/mitmul/chainer-faster-rcnn/images/Faster%20R-CNN.png
まあでも丁寧にみればそんなに複雑でもない。
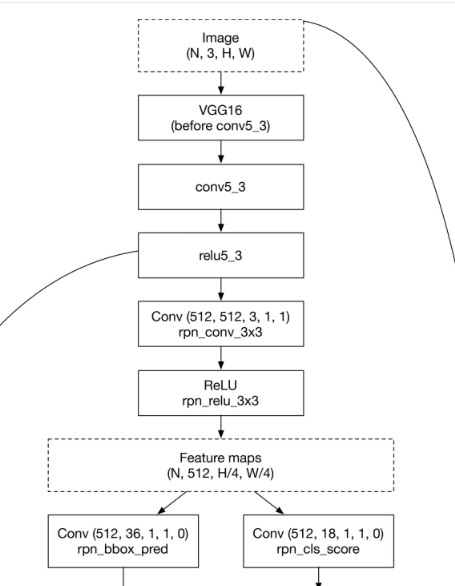
通常のCNNと違い、どんな解像度の画像でも放り込めるようになっている。
VGG16(というCNN)を前段に配置して、途中で特徴を取り出す。
relu5_3をバイパスして最後のROI(Regions of Interest;興味のある領域)プーリングに直接突っ込む。
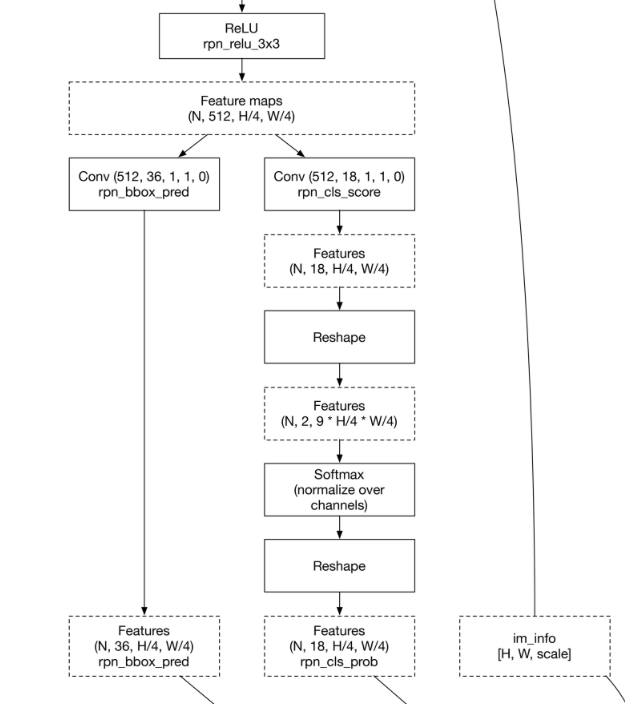
rpn_relu_3x3以降は特徴マップを整理して、最終的にできあがったものをすべてプロポーザルレイヤーに突っ込む。
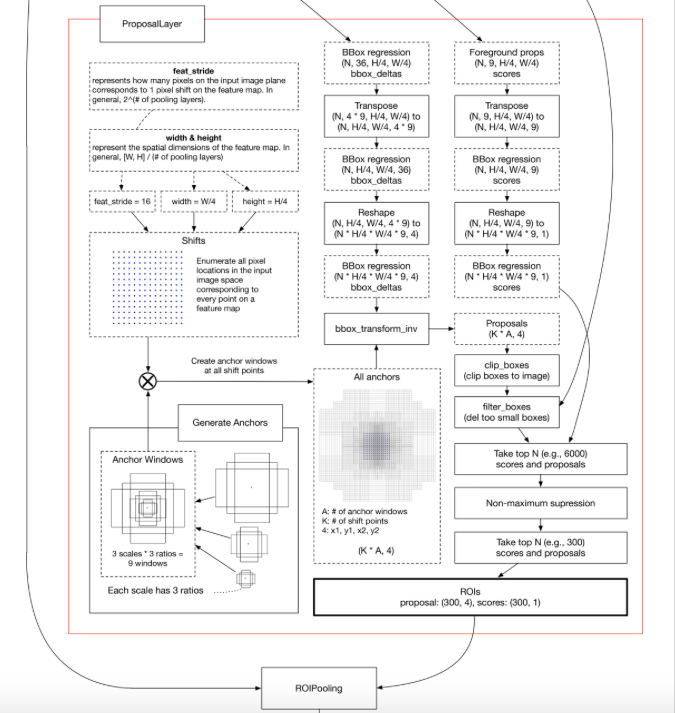
プロポーザルレイヤーではなにをしてるのか。
いんだよ細けえことは。
とにかく、特徴マップから「このへんがいいんじゃないの?」というROIを探す。探したROIは300箇所に及ぶ。
つまり300のROIが得られる。
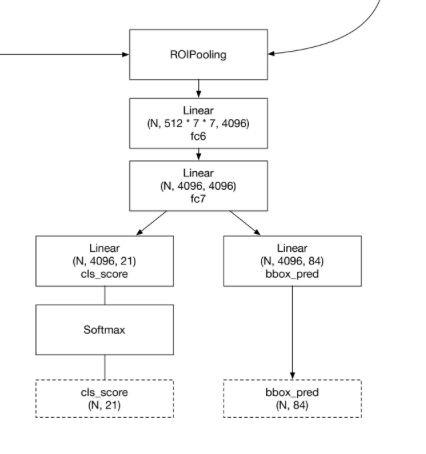
次に、さっきバイパスしたrelu5_3とプロポーザルレイヤーで得られた結果を合成する(ROI Pooling)
そのあとは、なにかちょっと安心感のある全結合層を使ったスコア推定と領域推定。
最後に個別のスコア(cls_score)と、個別の領域予測(bbox_pred)を出力して終わり。
ところでプロポーザルレイヤーだが、プロポーザルレイヤーの出力だけ見ても基本的にぜんぜんダメすぎてビックリする。ちなみにプロポーザルレイヤーは300もの領域を提案する。
これほぼランダムなんじゃないの?という勢いでダメである。こんなに複雑な計算をしてるのに!
そこでわりと絶望的な気分になるのだが、捨てる神があればなんとやら。どうも最後の全結合層でなんとかしてるらしいのである。
せっかくなので可視化してみた。

青い四角がプロポーザルレイヤーの推定、水色が全結合層経由で得られたbbox_predである。わりと凄いよね?
ちなみにさっきの図の最後のところは若干間違ってるというか省略されているらしく、実際にbbox_predで得られるのはプロポーザルレイヤーが提案した300あるROIそれぞれにつき21クラスがどこにあるかという推定になる。この推定がいかにテキトーかは、みればわかるだろう。乱数で与えてるんじゃないかと疑ってしまう。
つまり、(あくまでここで示しているモデルの場合)FasterRCNNで識別可能なのはひとつの画面につき1クラス最大300、合計21クラスまでということだ。まあそれならそれで充分じゃないの?という気もするけど。
なるほどなあ。
ソースコードを追いかけると性質がよくわかるなあ
まあこれを目的に応じてカスタマイズすればいいわけだね
ちなみに現状だと

文字だけのものはうまくいかないようだ。
よくわかる人工知能 最先端の人だけが知っているディープラーニングのひみつ
- 作者: 清水亮
- 出版社/メーカー: KADOKAWA
- 発売日: 2016/10/17
- メディア: 単行本
- この商品を含むブログ (1件) を見る
- 45 https://www.google.co.jp/
- 39 http://d.hatena.ne.jp/
- 27 https://t.co/mMbOXyNufa
- 6 http://reader.livedoor.com/reader/
- 5 http://feedly.com/i/latest
- 4 http://www.google.co.jp/url?sa=t&rct=j&q=&esrc=s&source=web&cd=2&ved=0ahUKEwismOT016vPAhVKxWMKHT33AVAQFggjMAE&url=http://d.hatena.ne.jp/shi3z/20120416/1334543387&usg=AFQjCNEm9yzD5pPRFt_ngNtTHbhee7G4SA
- 4 http://www.google.co.jp/url?sa=t&rct=j&q=&esrc=s&source=web&cd=3&ved=0ahUKEwi84YGA16vPAhWINpQKHRCvCVoQFggwMAI&url=http://d.hatena.ne.jp/shi3z/20141203/1417562699&usg=AFQjCNHmFWwFodEPx2T7K5isqnW_uqBIoA&sig2=ge6TXH-vYp5ECb4IE0PFGA
- 4 https://www.facebook.com/
- 3 http://feedly.com/i/subscription/feed/http://d.hatena.ne.jp/shi3z/rss
- 3 http://reader.livedwango.com/reader/