こんにちは。CS課の坂本です。
タイトルは違いますが、前回の続きです。【そんなときどうする?】シリーズ、早いもので今回は第4回目になります。
前回までの記事
- 【そんなときどうする?】CloudWatchのデータを2週間以上残したい!
- 【そんなときどうする?】CloudWatchのデータを2週間以上残したい! Lambda編
- 【そんなときどうする?】別のアカウントにセキュアにアクセスしたい! いまさらきけないSTSとは?
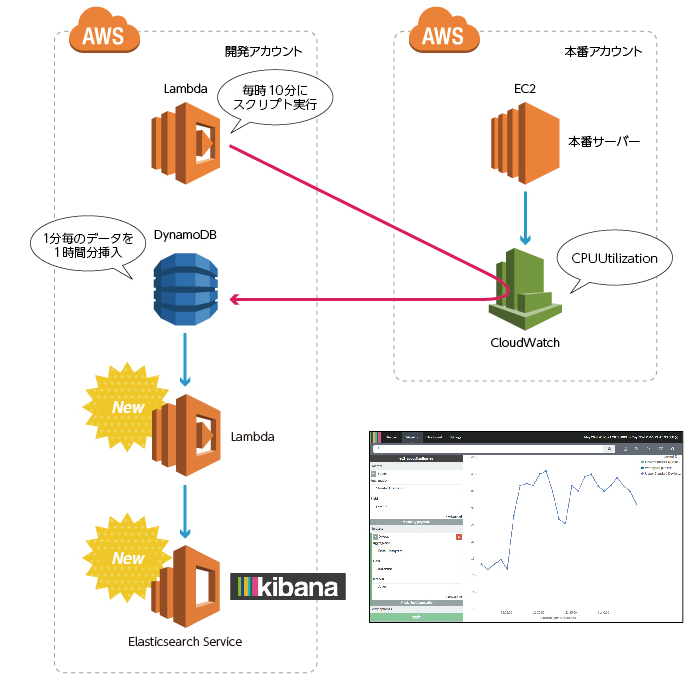
前回までで、CloudWatchのデータをDynamoDBに入れることができました。データを残せるようになったので、それを数字で見たり、データをおとしてきて手動でグラフにしてもいいのですが、自動で可視化できると更に便利になりますよね。
そんなデータの可視化に使えるAWSのサービスが「Amazon Elasticsearch Service」です。Elasticsearch Serviceには「Elasticsearch」自体はもちろん、可視化と分析用のツールである、「Kibana」も既にインストールされていますので、Elasticsearch Serviceにもっていったデータは、Kibanaを使ってすぐにグラフで確認できます。
どうやってDynamoDBのデータをElasticsearch Serviceにもっていくのがいいのかなー? と考えていたところ、またまた「Lambda」の「Blueprint」に「dynamodb-to-elasticsearch」といういいものがありました。
今回はLambdaのBlueprint、「dynamodb-to-elasticsearch」を使ってDynamoDBのデータをElasticsearch Serviceで簡単に可視化する方法をご紹介します。
※LambdaのBlueprintについてはよろしければ、こちらもご確認ください。
- Elasticsearch Serviceの設定
- DynamoDBのテーブル作成
- LambdaのBlueprint、「dynamodb-to-elasticsearch」の設定
- CloudWatchの値をDynamoDBにINSERTするLambdaファンクションの修正
- Elasticsearchの設定
- CloudWatchの値をDynamoDBにINSERTするLambdaファンクションの実行
- Kibanaでグラフ化
- まとめ
1. Elasticsearch Serviceの設定
まず、Elasticsearch Serviceを起動します。こちらは、弊社のブログ記事にすでに手順があります。この手順を参考に、Elasticsearch Serviceを起動してください。試すだけの場合は、インスタンスタイプやストレージの設定もこちらのページと同じスペックで問題ありません。スペックはあとから変更できますので、運用時に必要がでてきたらスケールアップできます。
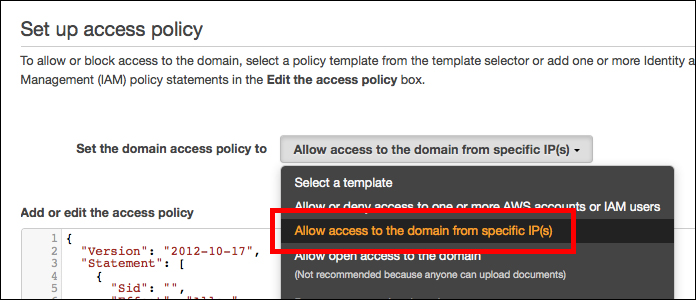
アクセス制御もこちらのページと同じように「Allow access to domain from specific IP(s)」を選んで、自分のIPからのみアクセスできるようにしておきます。
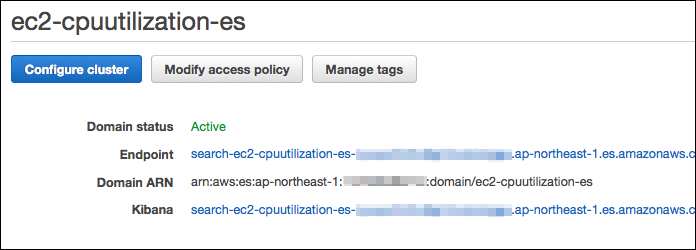
起動までは、少し時間がかかります。以下のように「Domain Status」が「Active」になれば利用できます。
2. DynamoDBのテーブル作成
Kibanaでグラフにするときに、時間軸として1つのカラム(フィールド)を指定する必要があるのですが、いままでのテーブル構造だと日付と時間が別々に入っていて、時間軸として扱えるカラムがありません。今回からはいままでのカラムに加え、日時を入れたカラム、「datetime」を追加した新しいテーブルを作成します。新しいテーブル、「ec2_cpuutilization_es」に新たにデータをためながら可視化していきたいと思います。
| 項目 | 例 | |
|---|---|---|
| プライマリパーティションキー | day | 2016/05/23 |
| プライマリソートキー | time | 12:28:00 |
| percent | 37.29 | |
| datetime | 2016/05/23 12:28:00 |
3. LambdaのBlueprint、「dynamodb-to-elasticsearch」の設定
1. Blueprintの検索/設定
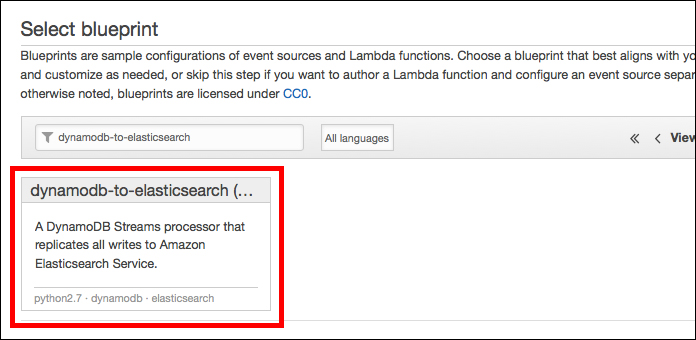
次は、Lambdaの設定です。Lambdaのマネジメントコンソールで「Create a Lambda function」ボタンを押します。次の「Select blueprint」画面で「dynamodb-to-elasticsearch」を検索/選択します。
※いまのところ、Python版のBlueprintしか用意されていないようですので、他の言語を使用されている方はお気をつけください。(2016/05/24)
2. DynamoDBのテーブル選択
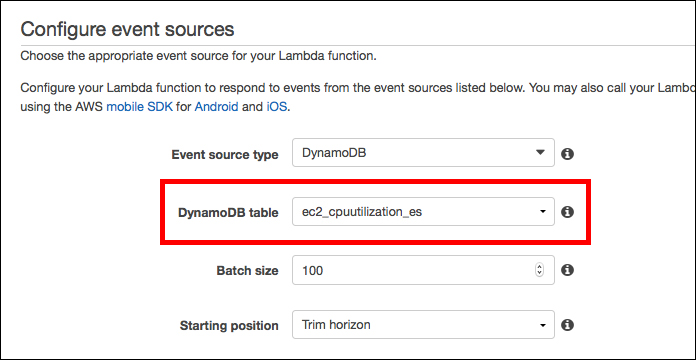
次の画面です。まずは、「Event source type」で「DynamoDB」が選択されていることを確認します。次に「DynamoDB table」で可視化したいDynamoDBのテーブルを選択します。今回の場合は「ec2_cpuutilization_es」テーブルです。「ec2_cpuutilization_es」テーブルに動きがあった場合に、それがトリガーとなり、このLambdaファンクションが実行されます。
「Batch size」では一度に処理できる件数を指定できます。とりあえずデフォルト値の「100」のままにしておきます。次に「Starting position」で「Trim horizon」が指定されていることを確認します。処理されていないデータを古い順から順番に読み込む、という指定です。
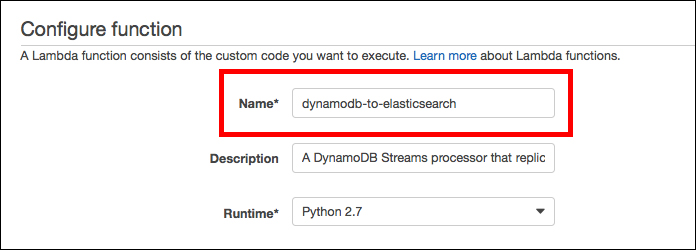
3. Lambdaファンクションの名前入力
次の画面でまずはLambdaファンクションの名前を決めて入力します。
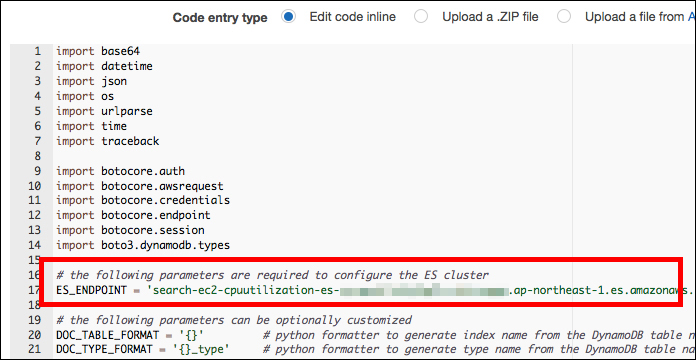
4. コードの編集(Elasticsearch Serviceのエンドポイントを入力)
同画面中央にすでにコードがセットされているので、「ES_ENDPOINT」に今回作成したElasticsearch Serviceのエンドポイントを代入します。何もカスタマイズをおこなわない場合、コードを変更するのはこの一箇所のみです。Elasticsearchではインデックスとインデックスタイプというものが必要ですが、ここで何も指定しなければ、それぞれDynamoDBのテーブル名が使われます。インデックス名は「ec2_cpuutilization_es」、インデックスタイプ名は「ec2_cpuutilization_es_type」となります。
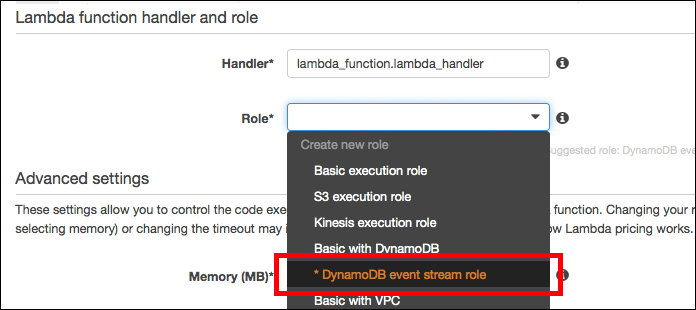
5. ロールの作成
次も同画面の画面下でロールの作成です。「DynamoDB event stream role」を選択します。
ロール名は「LambdaDynamoStreamRole」とでもしておきます。
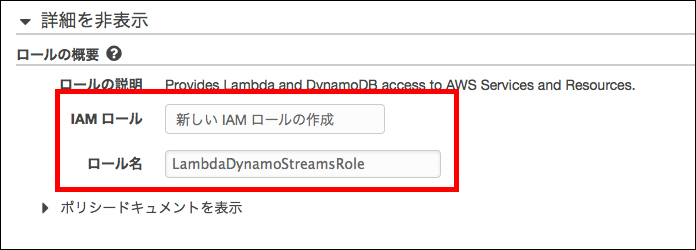
このロールのポリシーだけだと、Elasticsearch Serviceの操作に関するポリシーが含まれていないので、あとでIAMのマネジメントコンソールで、このロールに「AmazonESFullAccess」の管理ポリシーをアタッチしておきましょう。
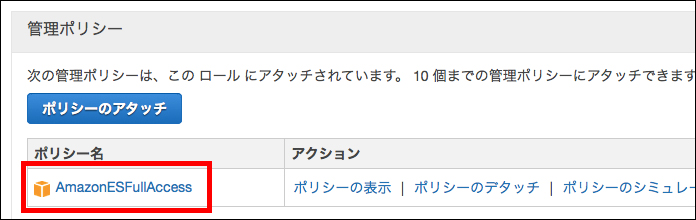
メモリやタイムアウトの設定は、とりあえずBlueprintで設定されたデフォルトの値のまま、次の確認画面へいきます。
このLambdaファンクションをすぐに有効にする場合は、確認画面で「Enable event source」にチェックを入れ、「Create function」ボタンを押して、Lambdaファンクションを作成します。
4. CloudWatchの値をDynamoDBにINSERTするLambdaファンクションの修正
次は、前々回で作成したLambdaのスクリプリト「cloudwatch-to-dynamodb.py」の修正です。
まずは、15行目のテーブル名を今回作成した新しいテーブル、「ec2_cpuutilization_es」に変更します。次に、ちょうど100行目で「datetime」というカラムに日時が入るようにコードを追加します。
cloudwatch-to-dynamodb.py
table_name = 'ec2_cpuutilization_es' #15行目のテーブル名を変更
<< 省略 >>
result = table.put_item(
Item = {
'day' : str(day),
'time' : str(key),
'percent' : str(value),
'datetime' : str(day + ' ' + key), #100行目に日時を入れるように追加
},
)
変更できたら、前々回と同じ手順でデプロイパッケージを作成して、Lambdaファンクションを作成しましょう。
5. Elasticsearchの設定
いろいろと準備ができてきました。次はElasticsearchの設定です。Elasticsearchではインデックス、インデックスタイプというものを作成して、カラムにあたるもの(フィールド)に型の指定をします。
指定をしなくても自動で型を登録してくれるのですが、数値として扱いたいフィールドがstring型に登録されてしまったりするので、今回は事前に型のマッピングをしておきたいと思います。
ElasticsearchのマッピングはHTTPでおこないます。以下のコマンドでマッピングをおこないましょう。「{“acknowledged”:true}」が返ってきたら成功です。
curl -XPUT http://search-ec2-cpuutilization-es-XXXXXXXXXXXXXXXXXXXXXXXXXX.ap-northeast-1.es.amazonaws.com/ec2_cpuutilization_es -d '{
"mappings":{
"ec2_cpuutilization_es_type":{
"properties":{
"datetime":{"type":"date","format":"yyyy/MM/dd HH:mm:ss"},
"day":{"type":"date","format":"yyyy/MM/dd"},
"percent":{"type":"double"},
"time":{"type":"date","format":"HH:mm:ss"}
}
}
}
}'
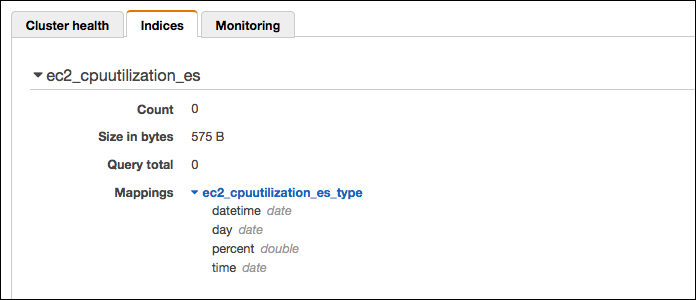
結果はマネジメントコンソールで確認できます。今回はCPU使用率の「percent」の部分に小数点以下の数値が入るので、「double型」を指定しています。他は「date型」にしました。
6. CloudWatchの値をDynamoDBにINSERTするLambdaファンクションの実行
先ほど作成したLambdaファンクションをマネジメントコンソールでテスト実行して、DynamoDBにデータを入れてみたいと思います。
テスト実行後、DynamoDBのマネジメントコンソールで見ると、データが入っていることが確認できます。
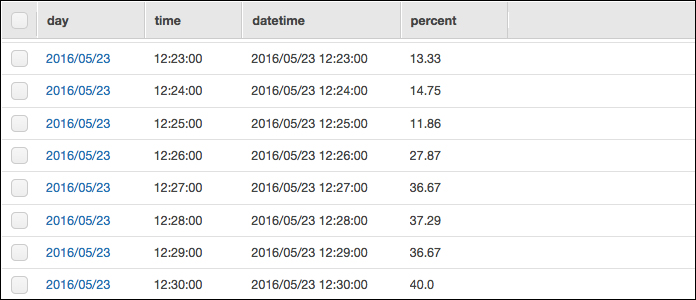
更にElasticsearch Serviceのマネジメントコンソールで確認すると、マッピング後の確認では0だったCoutの箇所がLambdaのテスト実行後、60になっているので問題なくデータはElasticsearch Serviceにも取り込めたようです。
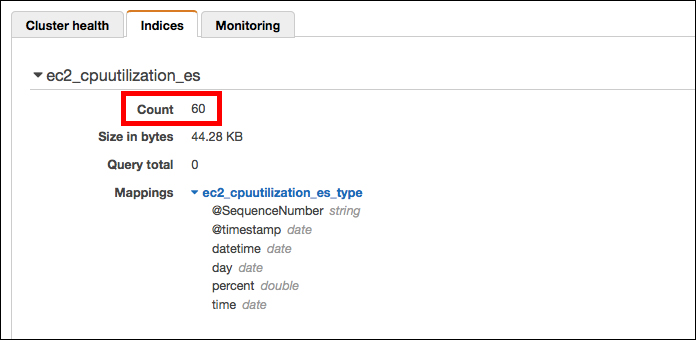
7. Kibanaでグラフ化
Elasticsearch ServiceのマネジメントコンソールにKibanaへのリンクがあるので、クリックします。
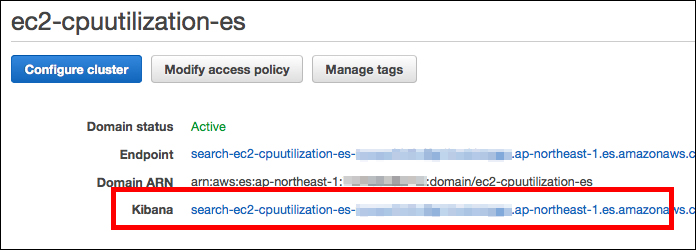
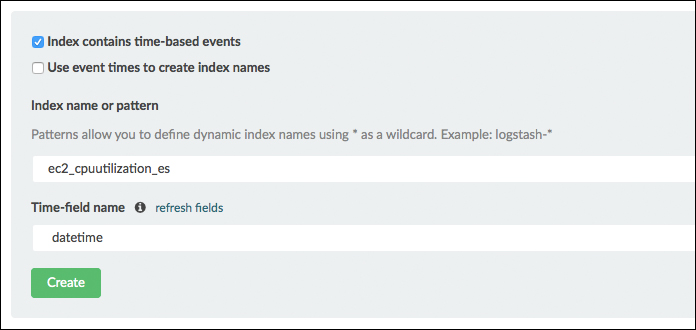
はじめの「Setting」の画面でインデックス名と時間軸のフィールドを入力して「Create」ボタンを押します。
まずは、Kibanaの画面上のメニューで「Visualize」を選択します。「Step1」として、どのタイプのグラフにするか選択する画面になるので、今回は「Line chart」を選択します。次の「Step2」では「From a new search」を選択しましょう。

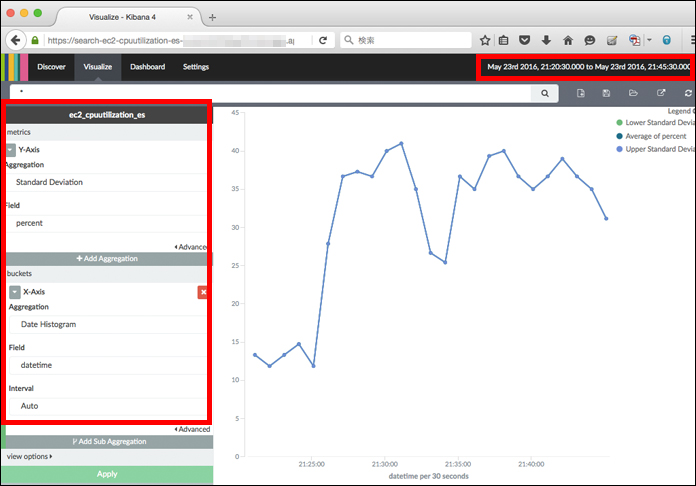
次の画面です。まずは右上のメニューでグラフを表示したい期間を指定します。次に、左側のメニューでどのフィールドを縦軸と横軸で表示するかの選択をします。以下のキャプチャのように「Y-Axis」の「Aggregation」で「Standard Deviation」、「Field」で「percent」、「X-Axis」の「Aggregation」で「Date Histogram」、「Field」で「datetime」、「Interval」で「Auto」を選択して左下の「Apply」と押すと、グラフが表示できます。
ここまでできていることが確認できたら、また「Lambdaでスケジュール実行の設定」をしておきましょう。
8. まとめ
今回はLambdaのBlueprintを使って、DynamoDBのデータをElasticsearch Serviceで可視化する手順をご紹介しました。こういった機能があるといいな〜と思うことが、気が付くとLambdaのBlueprintに追加されているので助かりますね。
いや〜、Elasticsearch Serviceって本当にいいものですね。
Tags: Amazon Elasticsearch Service AWS DynamoDB Elasticsearch Elasticsearch Service Kibana Lambda 可視化