深層学習に最適化したNVIDIAのPascal世代スーパーコンピュータDGX-1登場
DGX-1 ,the game changer
2016.04.06
Updated by Ryo Shimizu on 4月 6, 2016, 05:48 am JST
DGX-1 ,the game changer
2016.04.06
Updated by Ryo Shimizu on 4月 6, 2016, 05:48 am JST
シリコンバレーで開催されているGPU Technology Conference、通称GTCに来ています。
GTCは、もともとNVIDIAの開催するGPU関連のイベントだったのですが、ここ数年、特に去年からはこれまでのゲーミングやコンピュータ・グラフィックス中心の雰囲気から一気にディープラーニングに舵を取り、今年のGTC2016は「詳しくは言えないけど、ディープラーニング関連で事件が起きるよ」と耳打ちされた筆者は、遠路はるばる20年ぶりにサンノゼ国際空港にやってきました。
ちなみに前回サンノゼ国際空港に来た時は、ビル・ゲイツが自らXboxをプレゼンテーションするというイベントで、それ以来ということになります。
これは何かが起きそうな予感がしないと言ったら嘘になる・・・とはいうものの、初日はチュートリアルセッションで、時差ボケもあって退屈気味でした。
GTCは今回はじめて参加したのですが、驚いたのは、単独の私企業がホストするイベントとしては非常に大きいイベントになっているという印象を受けました。発表者もNVIDIAの社員だけではなく、GoogleやYahoo、NECなど、様々なバックグラウンドのスーピーカーがそれぞれの研究成果を語るという、一種学会的な雰囲気も漂っています。
NVIDIAは開発者向けに多数のディープラーニングやビジュアライゼーション、そしてバーチャルリアリティ構築用のツールキットをリリースしていて、その開発者と直接議論できたり、質問できたりする機会が設けられているというのはありがたいのですが、それ以上にここに集まった他の参加者との交流も楽しみのひとつです。
YOU BARというコーナーでは、自分の酒の好みと顔画像を登録しておくと、顔を見せただけで自分の好みのドリンクが自動的にオーダーされるという仕組み。
こちらのコーナーでは・・・
ニューラルネットワークによって書かせたアート作品を展示・販売しています。
こういう遊び心のある演出がそこかしこに見られるというのは、さすがシリコンバレーのイベントというわけなのですが、やはり本命はキーノート・スピーチです。
あけて翌日、NVIDIAの共同創業者であり、CEOでもあるジェンセン・フアン氏によるキーノートプレゼンテーションがスタートしました。
今年のNVIDIAの中心的な話題は2つ。ズバリ、バーチャルリアリティとディープラーニングです。
NVIDIAのCUDA開発者が4年前の4倍に増えたことなどが紹介された後、バーチャルリアリティ向けの技術であるIRAY VRで、NVIDIAの新社屋の完成予想CGの世界をリアルに再現したり、エベレストや火星を再現するといったVRコンテンツが紹介されました。
バーチャルリアリティのデモでは、なんとゲストとして元Appleのスティーブ・ウォズニアックが出演し、会場を沸かせました。
また、NVIDIAによる自動運転車を開発する実験などが紹介されました。
2017年には電気自動車レースであるFormula-Eで、自動運転レースカーによるレース「ROBORACE(ロボレース)」をやることを発表。
独創的なデザインのレーシングカーが紹介されました。人間が乗らないからコクピットがいらないんですね。
いずれにせよ、ワクワクするような話です。
そしてついに、噂されていたPascal世代とよばれる新世代のGPUを搭載したTESLA P100が発表されました。
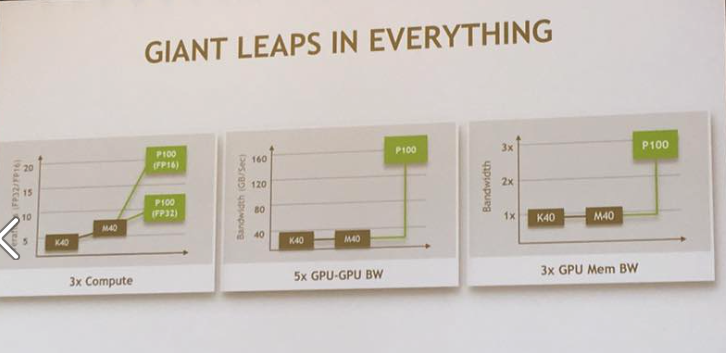
TESLA P100は、ディープラーニングでは非常に有効とされる、半精度(16ビット浮動小数点)を使うことで、前世代のGPUの3倍という驚異的な性能向上を実現しています。16ビット浮動小数点で最大21テラフロップスという、文字通りワンボードスーパーコンピュータと呼ぶにふさわしい性能です。
気になるのは出荷日ですが、TESLA P100の性能を最大限に発揮するためには、従来のPCベースのアーキテクチャでは不十分で、IBMやヒューレット・パッカードなどが来年第一四半期を目指して開発中とのことです。
しかし、これだけの高性能なチップが完成しているのに、実際に使えるのが来年以降になるというのはいかにも残念すぎる・・・と思ったら、続いて衝撃の発表がありました。
なんとNVIDIA自らがマザーボードを設計し、TESLA P100を8機搭載したスーパーコンピュータ、NVIDIA DGX-1を本日から発売するということです。
ただでさえ化け物級の性能を持つTESLA P100を8機搭載し、それぞれをNV-LINKという新設計のバスで接続することで、それぞれのTESLA P100に搭載されたメモリを統合的に扱うことが出来ます。
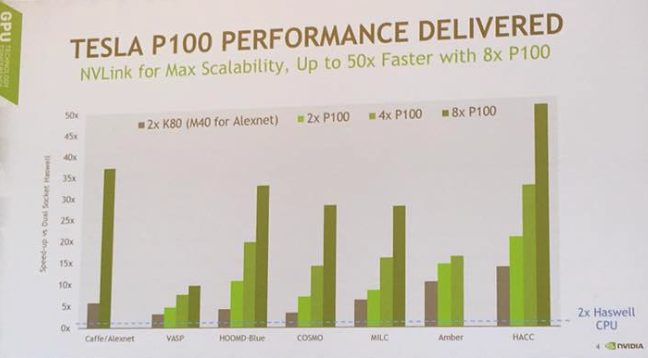
この性能は、Intel XEONプロセッサを2つだけ搭載されたシステムが150時間かかる計算を、わずか2時間で終わらせてしまいます。XEONのみのアーキテクチャと比較して75倍も速いのです。
XEONのみのアーキテクチャを用いて2時間以内に同程度の学習をさせようとすると250ノード以上が必要になるとのことで、まあ実際にいまどきGPUを使わずに学習させるケースは少ないのですが、前世代と比較しても圧倒的な速度差になります。
前世代、Maxwell世代のTESLA K80を二基使った構成のマシンがXEON比で5倍くらいの性能として、DGX-1はXEON比で37倍近い性能になっています。だいたい6倍くらいの性能になっていることがわかります。
特にディープラーニングの分野でよく使われるCaffeによるAlexnetの学習には大きな効果を発揮しています。
これまで、NVIDIAのGPUは、数が増えたからといって、そのまま直線的に性能が向上するというわけではありませんでした。
グラフを見ても分かる通り、2つのP100と2つのK80を比較すると、性能比はそこまでありません。
ところが、新たにNVLINKというバスで相互接続されたP100は、まさしく直線的に性能が上がっていきます。
これまでGPU間の通信にはCPUを経由する必要がありました。このため、処理の内容によってはCPUとPCI Expressバスがボトルネックとなって性能向上の妨げになっていたのですが、NVLINKというあたらしいバスを採用することで、GPU同士が直接お互いのVRAMにアクセスできるようになった結果、性能が飛躍的に向上できるようになったのです。
IBMやヒューレット・パッカードのマシンの供給が遅れているのはまさにこのバスのためで、これまでのPCベースのシステムでは実現できず、まさにこれから研究開発して一年後の製品化を目指す、という段階なわけです。
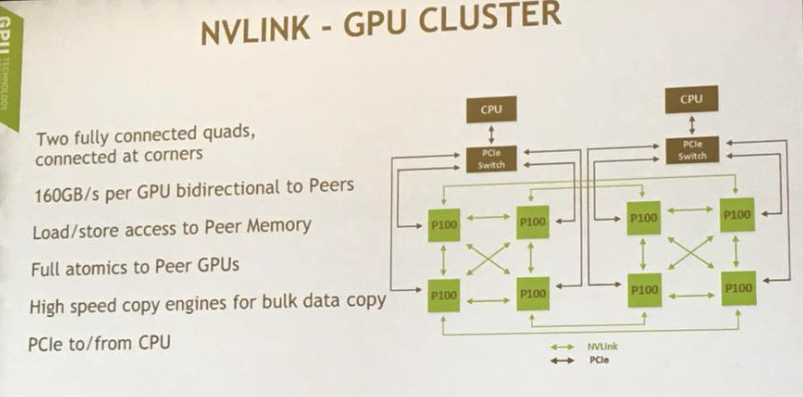
実際のアーキテクチャは上図のようになっています。
2つのCPUがそれぞれ4つのGPUを束ね、4つのGPUは互いにNVLINKで相互接続されています。
NVLINK間のアクセスはCPUを介さず直接行われるため、160GB/sという驚異的なスピードが実現できるのです。
これはそれまでGPUひとつひとつが単独の頭脳だったとすれば、8つの頭脳が相互接続されたのと同じ状態と言えます。
会場には、GoogleのディープラーニングフレームワークであるTensorFlowの開発者も登壇し、新しいハードウェアに掛ける期待を語りました。
二週間は大袈裟としても、K80世代のGPUで30時間かかる学習がDGX-1で2時間で終わるとしたら、300時間、約12日間かける学習がわずか20時間、一日で終わるわけです。この性能向上の恩恵は凄まじく、本格的にディープラーニングを必要とする企業は競ってDGX-1を買うことになるでしょう。
既に市場では、前世代のGPUであるTITAN Xの争奪戦が起きています。このコストパフォーマンスが高すぎるマシンは、小規模なオフィスや大企業の小集団などが手軽にディープラーニングを試すためのテストベッドとして大ヒットしていて、全世界で計算資源の奪い合いが起きています。
先日、MicrosoftがAzureクラウドのGPU対応を始めましたが、ディープラーニング用途で使われるフレームワークの大半はLinuxベースなので、やや物足りない印象ですが、さくらインターネットがスタートした高火力コンピューティングや、GoogleがスタートしたTensorFlowクラウドなどはまさしく今後こうした分野が活発化することの予兆を感じさせます。
しかし、TensorFlowクラウドもさくらの高火力コンピューティングも、ともにインフラの提供にとどまり、複数のノードをうまく活用できるかどうかは利用者のプログラミング次第、というところがありました。プログラミングをミスると計算時間も費用も大きくロスするので、個人的には実験を繰り返すような目的には使いづらいなという印象です。また、医療系など、個人のプライバシーに関わる情報を扱う仕事ではどうしてもクラウドを使うわけにはいかない、という需要もあります。
このなかにあってDGX-1はオーパーツとも言えるほど衝撃的で、その場で発表された価格12万9千ドル(約1400万円)というプライスタグもそれほど高くは感じさせないほどのインパクトがありました。
「これはすぐに売り切れてしまう」と感じた筆者はその場から顧客や上司にメッセージを送り、必要数をその場で注文しました。
今後は、まずTITAN Xなどの比較的安価なGPUを搭載したワークステーションで仮説の検証やプログラミングを行い、DGX-1である程度大規模な学習を行ってプロトタイピングやフィジビリティスタディを行い、TensorFlowクラウドや高火力クラウドでは現実のサービスに使われている膨大なビッグデータをもとにした大規模な学習タスクを常時走らせる、という三段階の活用に移行していくでしょう。
告知:「実践としてのプログラミング講座」本日から発売です。
おすすめ記事を配信する『WirelessWire Weekly』と、閲覧履歴を元にあなたに合った記事をお送りする『Your Wire』をお送りします(共に週1回)
配信内容を詳しく見る
1976年新潟県長岡市うまれ。6歳の頃からプログラミングを始め、16歳で3DCGライブラリを開発、以後、リアルタイム3DCG技術者としてのキャリアを歩むが、21歳より米MicrosoftにてDirectXの仕事に携わった後、99年、ドワンゴで携帯電話事業を立上げる。'03年より独立し、現職。'05年独立行政法人IPAより天才プログラマーとして認定される。