この記事は 今年もやるよ!AWS Lambda縛り Advent Calendar 2015 の23日目です。
「何か書くぞ!」と思いエントリーしてみたもののどうしよう、、と思っていたのですが、そういえば個人的に Apache Tika というのが最近気になっていたので使ってみることに。
これは、PDFやエクセル等のファイルから、テキストデータやメタデータを抽出してくれるという便利ライブラリです。これを使って、ファイルが登録されたら裏でテキストデータを抽出して、それを全文検索で引っかかるようにする…みたいなことが出来ると楽しそうです。
Apache Tika自体はJavaのライブラリなのですが、Node.jsから扱うためのライブラリ があったので、今回はこれを使って
という流れをやってみたいと思います。
では早速、AWSのマネジメントコンソールからLambdaを触ってみましょう。
(クリックで拡大されます)

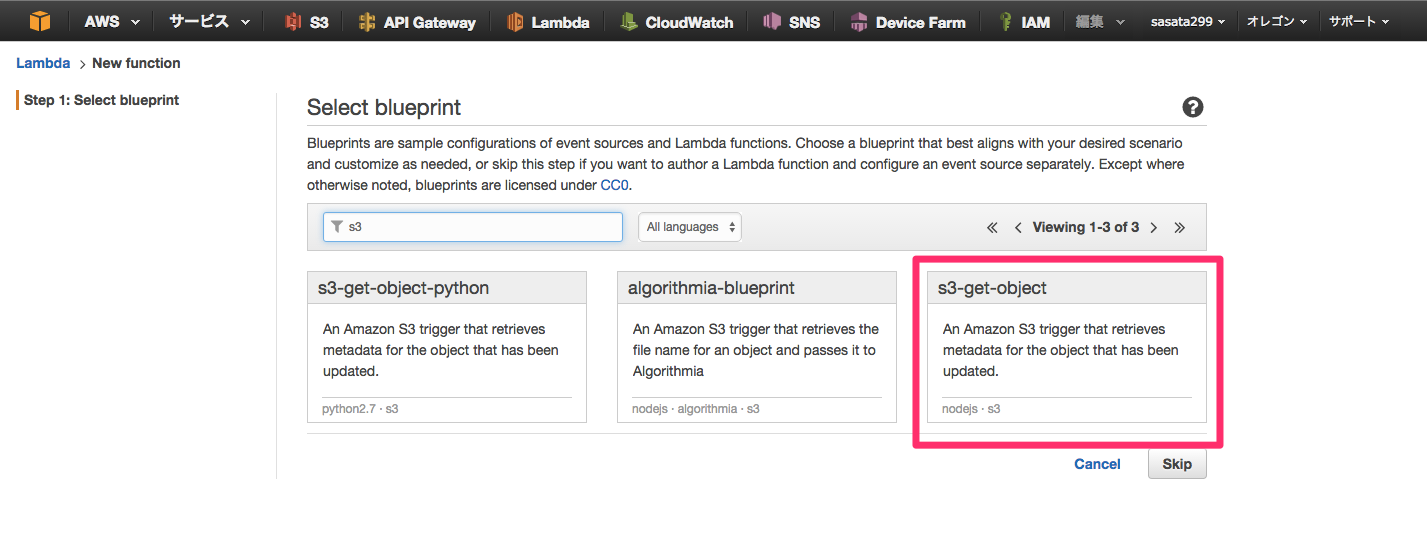
今回はS3にファイルが置かれたのをトリガーとしてLambdaを起動したいので、"s3" というキーワードでフィルタリングした状態です。Node.jsである一番右側の「s3-get-object」を選びました。
※ちなみにblueprintは、青写真とか設計図とかいう意味
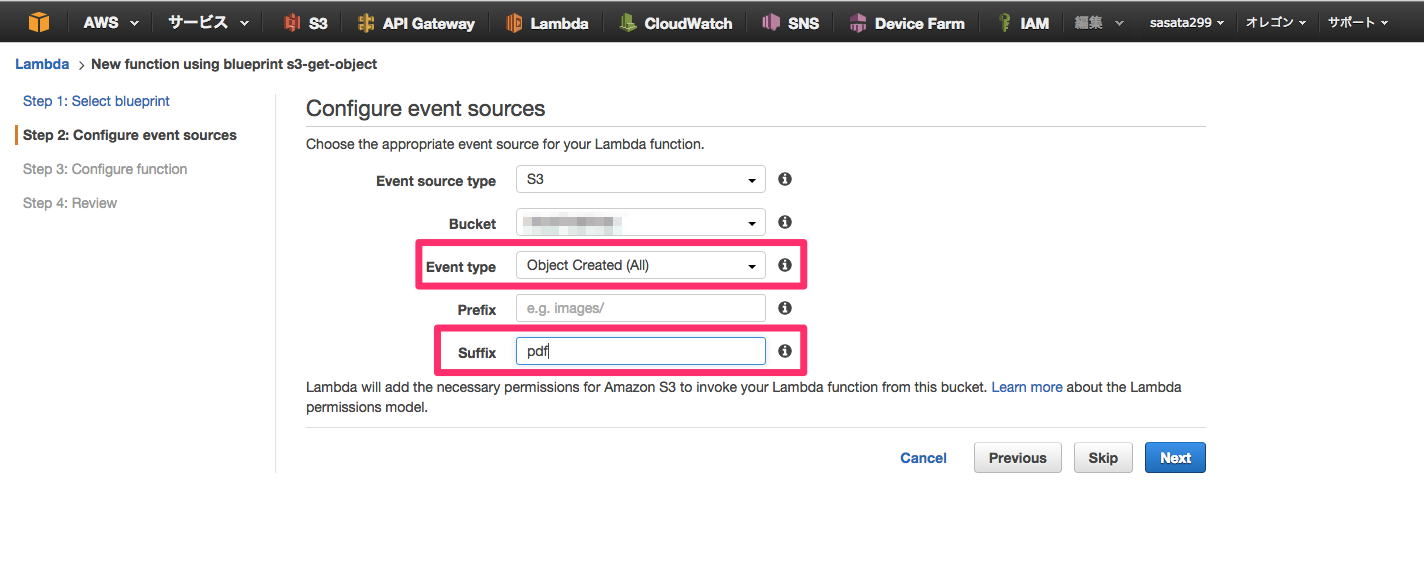
次は、event source(トリガー)の指定です。今回はPDFファイルの作成や更新時にのみ、Lambdaを起動させるようにしました。

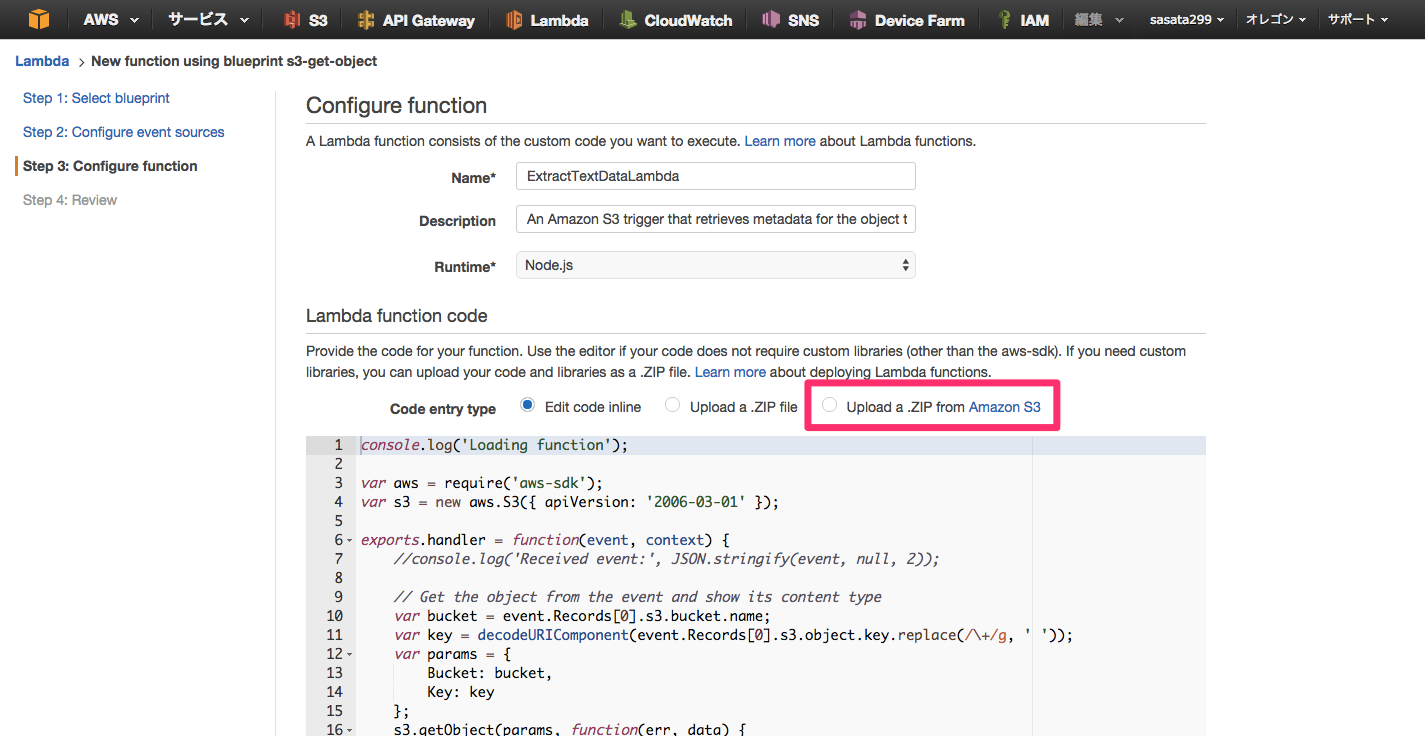
続いて、Lambda起動時に実行される処理を登録します。今回は10MBを超える容量となったので、S3に必要なファイルをまとめてzipにしたものを置いておき、それを取り込むようにします(後述します)。

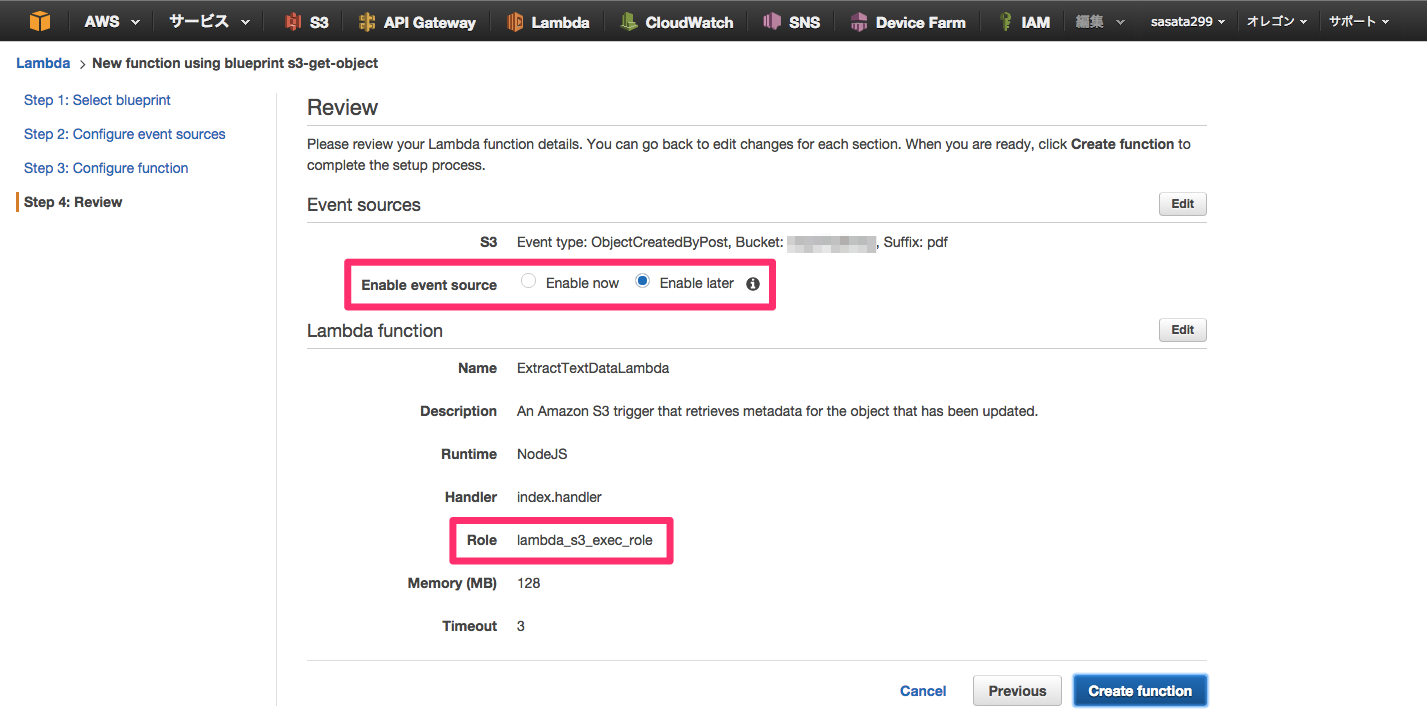
LambdaにはIAMのロールを設定する必要があるので適切なロールを設定してください。今回はS3へのアクセスができるようになっていれば良いかと思います。

トリガーの反映は後で良いでしょう。基本的にはテストデータで動作確認して、動くようになったらトリガーをONにし、実際にS3にファイルが置かれたことをトリガーとしてLambdaが起動するようにします。
さて、いきなり結論となってしまいますが、今回はこんなコード(index.js)を書きました。
テキストデータの抽出のところ、びっくりするくらい簡単に出来るので拍子抜けです。ただこれ、最終的にはLambda上で動かせてません。。(ローカルでは動くんですが><)
なお事前に、
は実行済みです。その後、index.jsとnode_modulesをzipに固めて、S3に置いてLambdaの起動時の処理として登録しています。最終的に50MBほどのサイズになってました。
今回はLambdaからS3に置かれた任意のファイルにアクセスしてテキストデータの抽出をするので、バケットごと誰でも読み取りができるようにしています。。><

<参考URL>
S3のアクセスコントロールが多すぎて訳が解らないので整理してみる | Developers.IO
・・さて、そんな感じで結局はうまくいっていないんですが、一応遭遇した問題を残しておきます。m(_ _)m
トリガーをONにしようとしたら、
こんなエラーが出てきてトリガーがONにできず困りました(どういうことなの???)。でも次の日またやってみたらいけた。なんだったんだろうか。。
Lambdaで実行していたら、invalid ELF header というエラーが!!どうも調べてみると、LambdaはLinux上で動作するっぽいんですが、Macでコンパイルしているため、Linux上でそれが正しく動かないのが問題のようです。
解決策としては、AWSのAmazon LinuxのEC2上でコンパイルしようという話のようなので、そりゃそうだと思いつつ実際に試してみました。が、それを使うと今度はこんなエラーが。。(解決できず)
結局は動かせてないし時間が無くてバタバタなんですが、何かの参考になれば幸いです。
「何か書くぞ!」と思いエントリーしてみたもののどうしよう、、と思っていたのですが、そういえば個人的に Apache Tika というのが最近気になっていたので使ってみることに。
Apache Tika
これは、PDFやエクセル等のファイルから、テキストデータやメタデータを抽出してくれるという便利ライブラリです。これを使って、ファイルが登録されたら裏でテキストデータを抽出して、それを全文検索で引っかかるようにする…みたいなことが出来ると楽しそうです。
Apache Tika自体はJavaのライブラリなのですが、Node.jsから扱うためのライブラリ があったので、今回はこれを使って
1. S3にPDFファイルが置かれる
2. それをトリガーとしてLambdaが起動し、Apache Tikaを使ってテキストデータを抽出する
3. 抽出したテキストデータをS3に置く
という流れをやってみたいと思います。
Lambdaを触ってみる
では早速、AWSのマネジメントコンソールからLambdaを触ってみましょう。
(クリックで拡大されます)
今回はS3にファイルが置かれたのをトリガーとしてLambdaを起動したいので、"s3" というキーワードでフィルタリングした状態です。Node.jsである一番右側の「s3-get-object」を選びました。
※ちなみにblueprintは、青写真とか設計図とかいう意味
次は、event source(トリガー)の指定です。今回はPDFファイルの作成や更新時にのみ、Lambdaを起動させるようにしました。
続いて、Lambda起動時に実行される処理を登録します。今回は10MBを超える容量となったので、S3に必要なファイルをまとめてzipにしたものを置いておき、それを取り込むようにします(後述します)。
LambdaにはIAMのロールを設定する必要があるので適切なロールを設定してください。今回はS3へのアクセスができるようになっていれば良いかと思います。
トリガーの反映は後で良いでしょう。基本的にはテストデータで動作確認して、動くようになったらトリガーをONにし、実際にS3にファイルが置かれたことをトリガーとしてLambdaが起動するようにします。
テキストデータの抽出
さて、いきなり結論となってしまいますが、今回はこんなコード(index.js)を書きました。
console.log('Loading function');
var aws = require('aws-sdk');
var s3 = new aws.S3({ apiVersion: '2006-03-01' });
var tika = require('tika');
exports.handler = function(event, context) {
console.log('Received event:', JSON.stringify(event, null, 2));
var bucket = event.Records[0].s3.bucket.name;
var key = decodeURIComponent(event.Records[0].s3.object.key.replace(/\+/g, ' '));
var params = {
Bucket: bucket,
Key: key
};
s3.getObject(params, function(err, data) {
if (err) {
console.log(err);
var message = "Error getting object " + key + " from bucket " + bucket +
". Make sure they exist and your bucket is in the same region as this function.";
context.fail(message);
} else {
console.log('CONTENT TYPE:', data.ContentType);
console.log('KEY:', key);
var url = "https://s3-" + event.Records[0].awsRegion+ ".amazonaws.com/" + bucket + "/" + key;
console.log(url);
// テキストデータの抽出
tika.text(url, function(err, text) {
if (err) {
context.fail(err);
} else {
s3.putObject({
Bucket: bucket,
Key: key + ".txt", // S3にUPするファイル名
Body: text
}, function(err, data) {
if (err) {
context.fail(err);
} else {
context.succeed("Successfully finished");
}
});
}
});
}
});
};
テキストデータの抽出のところ、びっくりするくらい簡単に出来るので拍子抜けです。ただこれ、最終的にはLambda上で動かせてません。。(ローカルでは動くんですが><)
なお事前に、
$ npm install aws-sdk --save-dev $ npm install tika --save-dev
は実行済みです。その後、index.jsとnode_modulesをzipに固めて、S3に置いてLambdaの起動時の処理として登録しています。最終的に50MBほどのサイズになってました。
$ zip -r extract_text_data.zip index.js node_modules
S3のバケットポリシー
今回はLambdaからS3に置かれた任意のファイルにアクセスしてテキストデータの抽出をするので、バケットごと誰でも読み取りができるようにしています。。><
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AddPerm",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::<bucket_name>/*"
}
]
}
<参考URL>
S3のアクセスコントロールが多すぎて訳が解らないので整理してみる | Developers.IO
・・さて、そんな感じで結局はうまくいっていないんですが、一応遭遇した問題を残しておきます。m(_ _)m
遭遇した問題その1
トリガーをONにしようとしたら、
There was an error creating the event source mapping: Configuration is ambiguously defined. Cannot have overlapping suffixes in two rules if the prefixes are overlapping for the same event type.
こんなエラーが出てきてトリガーがONにできず困りました(どういうことなの???)。でも次の日またやってみたらいけた。なんだったんだろうか。。
遭遇した問題その2
Lambdaで実行していたら、invalid ELF header というエラーが!!どうも調べてみると、LambdaはLinux上で動作するっぽいんですが、Macでコンパイルしているため、Linux上でそれが正しく動かないのが問題のようです。
解決策としては、AWSのAmazon LinuxのEC2上でコンパイルしようという話のようなので、そりゃそうだと思いつつ実際に試してみました。が、それを使うと今度はこんなエラーが。。(解決できず)
libjvm.so: cannot open shared object file: No such file or directory
結局は動かせてないし時間が無くてバタバタなんですが、何かの参考になれば幸いです。