(この記事はGoogle Cloud Platform Advent Calendar 2015の12月3日分の記事です)
Cloud Vision APIと私
Googleに入ってからまもなく5年、Google Cloud Platformのデベロッパーアドボケイト(エバンジェリストみたいな役割)の仕事に就いてから1年が経ちました。仕事の半分はアジア地域向けの開発者コミュニティ支援で、残り半分はGCPの新製品ローンチの支援をグローバル向けに行っています。
特にここ半年は、TensorFlowをはじめ、GCPの機械学習系プロダクトのローンチ支援にフォーカスしています。TensorFlowはその序章で、公開前からAlphaカスタマー向けのスライドを作ったり説明やデモしたりしていました(ちなみに現在公開されている単体のTensorFlowは最終形態ではありません。スーパーサイヤ人になる前の悟空くらいの実力です。今後をお楽しみに)。
そうしたGCPの新しい機械学習系サービスのひとつが、12月2日にLimited Preview版がリリースされたCloud Vision APIです。これはGoogleフォト等のGoogleの最新の画像認識技術をAPIとして外部のデベロッパーに提供するサービスです。RESTで画像データをクラウドに送ると、分析結果のJSONを1秒程度で返してくれます。TensorFlowのように機械学習のアルゴリズムを記述したりモデルの学習を行う必要はないので、私のような機械学習素人でもすぐ使えます。
このAPI、というより、Googleの画像認識技術がほんとに凄いんです。Google Brainチームが3〜4年前から開発を続けてきたディープラーティング技術がどかどか投入されているせいか、少しキモいくらいです。それをわかりやすく伝えるべく、Cloud Vision APIを使って画像認識するRaspberry Pi搭載のロボットカー(以下画面右下)を作って、さらにグローバル向けのGCP公式ブログに載せるデモビデオも作りました。

この記事では、Cloud Vision APIの能力に触れながら、このRasPiボットとデモビデオを作るに至ったいきさつを紹介したいと思います。
Cloud Vision APIとRasPiボット君の誕生
Cloud Vision APIでは、以下の種類の画像認識を行えます。
- 顔検知:画像上の複数の顔を検知し、目鼻口の位置、感情、顔の向き(3D)を推測します(個人の認識はできません)
- 物体検知:画像上の物体が何かを検知し、ラベルを返します
- ロゴ検知:画像上の企業ロゴやブランドマークを検知します
- ランドマーク検知:画像上のランドマーク(例えば富士山等)を検知し、ラベルやランドマークの地理的位置を返します
- OCR:多言語対応のOCRを行います
- セーフサーチ検知:画像にアダルトコンテンツやバイオレントな要素が含まれていないか判定します
例えば、上のデモビデオのサムネイル画像に対して顔検知を行うと、以下のJSONが1秒ほどで返ってきます(座標データは長いので省略してます)。
{
"faceAnnotations": [
{
"angerLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"boundingPoly": {
"vertices": [ ... ]
},
"detectionConfidence": 0.99990427,
"fdBoundingPoly": {
"vertices": [ ... ]
},
"headwearLikelihood": "VERY_UNLIKELY",
"joyLikelihood": "VERY_LIKELY",
"landmarkingConfidence": 0.85957086,
"landmarks": [ ... ],
"panAngle": -12.353742,
"rollAngle": 0.22884195,
"sorrowLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"tiltAngle": -0.86945021,
"underExposedLikelihood": "VERY_UNLIKELY"
}
]
}
顔の座標に加えて、"joyLikelihood": "VERY_LIKELY"のような感情や、"panAngle": -12.353742のような顔の向きが取れているのが分かります。
3か月ほど前からこのAPIのAlpha版をテストしながら、こりゃすごい、これで面白いデモを作れないかな、とずっと考えていました。
そんな10月の初旬、えーじさんと社内でランチしていて、彼がハマっているラジコンカーの話を聞いていました。ラジコンカーって何が面白いんだ? と思いながらも、しかしそのときピコンとひらめいたのです。ラジコンカーにRasPiとカメラを載せて、Cloud Vision APIで画像認識するのはどうだろ。これがすべての始まりでした。ありがとう、えーじさん。
GoPiGoをポチる
いろいろ探した結果、ぴったりな製品がありました。Dexter IndustriesのGoPiGoです。まよわずポチリました。RasPiにモーターが付いてて、さらにオプションのカメラとサーボ、超音波距離センサも購入。合計で$330ほど。10日くらいで届いたので、さっそく組み上げました。

チュートリアルにしたがってPythonコードを書いてみると、とても簡単にボットをコントロールできます。from gopigo import *と書いてfwd()とすると前に進む。こいつ動くぞ。
PMとブレストで盛り上がる
しかし10月後半はUS出張が入ってたので、GoPiGoとのたわむれを一時中断。Cloud Vision APIのProduct Manager (PM)やTech Leadとカークランドやマウンテンビューのオフィスで打ち合わせしてました。PMと話しているときに、「いまRasPiのボットで遊んでて、これでAPIを呼ぶと面白いと思うのだけど」とアイディアをシェアしたら、彼はすっかり気に入ってくれて、そこから2人でブレスト開始。顔検知してボットをそちらに動かしたり、物体検知してそれを音声で読み上げたり、といった私があたためていたネタを披露しました。
(↑PMがなぜか寿司にこだわるので、イラストも寿司にしてみた)
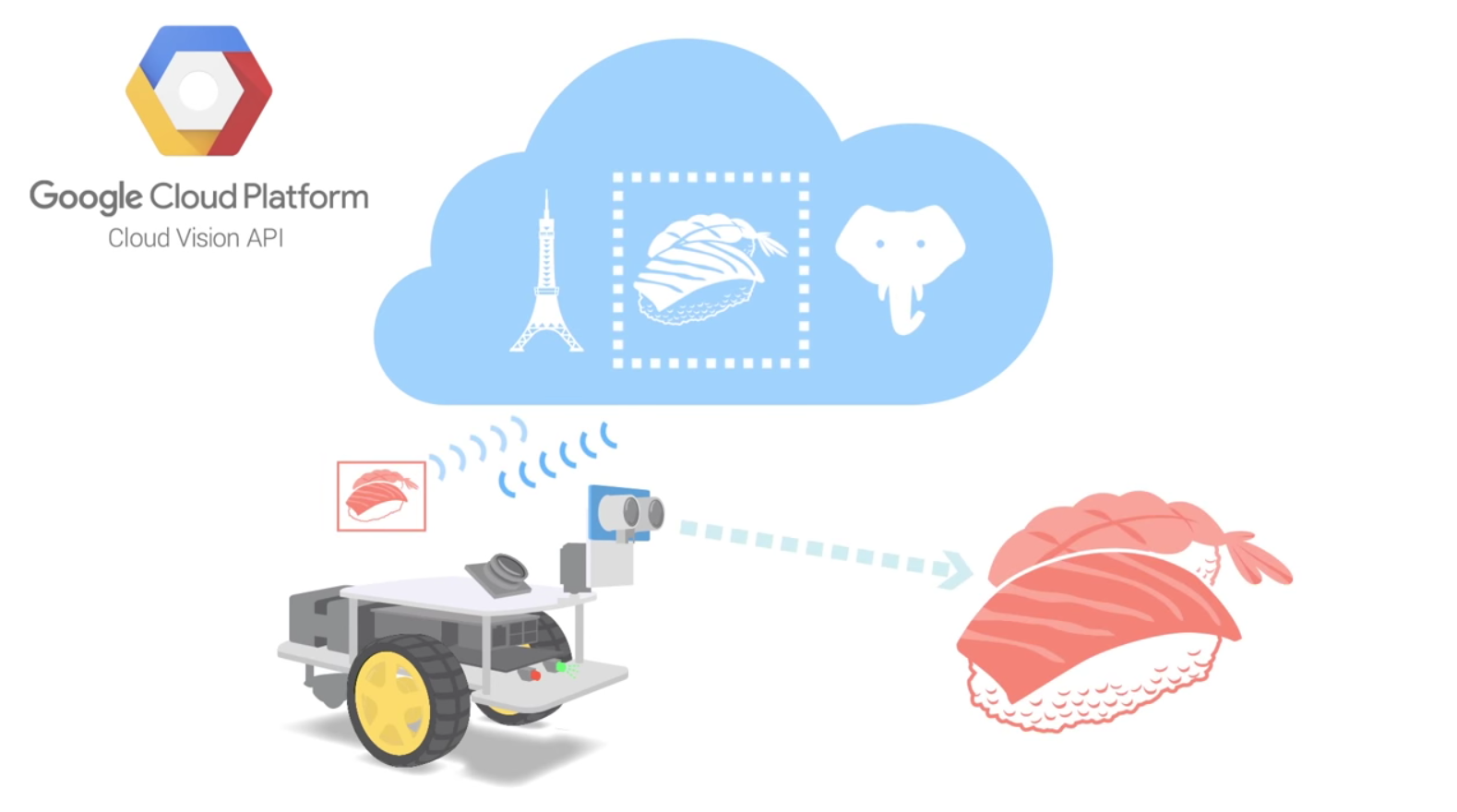
するとPMは「12月頭のAPI公開時にデモビデオを出そう」とか言い出しました。いやいや、まだボット君のコードは一行も書いてないし、あと1か月しかないし。しかし、その後サンフランシスコで会った私のマネージャもこのアイディアをたいへん気に入ってくれて、それまでは趣味半分だったアイディアがこの時点から優先度の高い仕事になります。
ボット君、笑顔の人になつく
11月はじめに東京に戻ってからは、ボット君のコーディングを開始しました。まずは、カメラ画像で近くにいる人の顔を検知し、超音波距離センサ(GoPiGoの目のように見える2つのセンサ)をそちらに向ける、というふるまいの実装。
しかし実際に書いてみると、標準のカメラでは画角が狭すぎてボットの左右にいる人を検知できない問題が発覚。すぐさま魚眼レンズ付きのカメラを購入して、140度ほどの範囲で顔を見つけてセンサを向ける動作を実装できました。
こうした単純な顔検知だけであれば、これまでもOpenCV等のライブラリで実装されていたので、あまりめずらしくありません。クラウドを使わずにRasPi単体でも実装できます。でもCloud Vision APIでは、顔の向きを3次元で取れるほか、喜怒哀楽の感情を読み取れます。

これを使い、joyLikelihood(喜びの度合い)の高い顔を見つけて、そちらに向かってボットを走らせるコードを書きました。その頃に最初に撮ったビデオがこれ。
Cloud Vision Bot: the first preview

しかしこれ、デバッグが難しいのです。本気でニコッと笑わないと、ボット君はついてこない。でも、うちの息子が近寄ってきて自然に笑うと、ボット君はすぐになつくんです。ディープラーニングは作り笑いを見抜けるのか。心が汚れていると開発に支障が生じるという事案が発生です。
さらに、驚いたり怒った顔を見せると後ろに退くコードも書きました。
ボット君、モノの名前をしゃべる
その後、11月半ばはベルリン出張で開発は一時中断。日本に帰ってきた11月の後半に、やっと物体検知の機能を付けました。
Cloud Vision APIの物体検知、これはほんとすごいです。
例えば、こんな画像。フランクフルト中央駅で撮ってきたTGVの写真です。

これを送ると、1秒もせずに以下のJSONが返ってきます。
{
"labelAnnotations": [
{
"description": "train",
"mid": "/m/07jdr",
"score": 0.99864358
},
{
"description": "tgv",
"mid": "/m/0fr81",
"score": 0.99717808
},
{
"description": "train station",
"mid": "/m/0py27",
"score": 0.99558604
},
{
"description": "transport",
"mid": "/m/07bsy",
"score": 0.98415387
}
]
}
tgvと当ててるだけでなく、train stationという環境も識別できてます。
もうひとつは、こんな画像。

これに対する認識結果は以下のようになります。
{
"labelAnnotations": [
{
"description": "vegetable",
"mid": "/m/0f4s2w",
"score": 0.99807608
},
{
"description": "food",
"mid": "/m/02wbm",
"score": 0.99306649
},
{
"description": "jack o lantern",
"mid": "/m/01d4b2",
"score": 0.92420679
},
{
"description": "halloween",
"mid": "/m/03lq2",
"score": 0.90573364
},
{
"description": "winter squash",
"mid": "/m/02pmq73",
"score": 0.86507517
},
{
"description": "pumpkin",
"mid": "/m/05zsy",
"score": 0.8569693
},
{
"description": "carving",
"mid": "/m/0jwzhtg",
"score": 0.67087185
},
{
"description": "holiday",
"mid": "/m/03gkl",
"score": 0.61808133
}
]
}
jack o lanternやpumpkinといったモノの識別だけでなく、halloweenやholiday、carvingといった状況まで推測してくれてます。確かにこの時は、休日のハロウィンのお祭りで息子とカボチャを掘ってランタン作ってました。おっしゃるとおりです。これがディープラーニングの発現か。
もちろん、これらの画像を事前に登録しておいてパターン認識しているわけではありません。いずれもAPIにとっては「初見」の画像です。
冒頭のボット君のビデオでも「メガネ」「クルマ」「バナナ」「お金」を認識していますが、ヤラセや仕込みはありません :) 魚眼レンズが捉えた画像のうち、中心の200x200ピクセルを切り取ってAPIに投げると、認識結果のラベルがいくつか返ってくるので、それを音声合成(festival)でしゃべる簡単なしくみです。ただ、作りはじめたころは「天井」とか「照明」とか「顔」とか、まあそうだよなあって単語ばかりしゃべるので、そうしたラベルはスキップするコードを入れてあります。
デモビデオの脚本を書いて、撮影
ボット君がいい感じにしゃべりはじめてくれたので、11月後半は並行してデモビデオの脚本を書いたり、短納期にも関わらずビデオのプロダクション作業を引き受けていただいたデータディスクさんとの調整を進めました。グローバルのGCP公式ブログに載せるので、USオフィスのPMやマーケティング担当者とやり取りしながら脚本を念入りにレビューします。
そして11月24日にビデオを撮影。MCは同僚のyukarisさんにお願いしました。彼女は英語がネイティブ発音なうえ、にっこり笑顔が得意です。撮影中はボット君がなつきすぎてしまい、撮影に支障をきたしてました。ほっとくとyukarisさんにすり寄って話しかけてくるという、生みの親に似て不躾なボット君です。

無事撮影も終了し、プレビュー版をPMやマーケ担当とシェアしてレビューを進めます。その後の修正作業も、データディスクさんとyukarisさんのご協力によってなんとか切り抜けることができました。みなさん、本当にありがとうございます。
最後に、PM、マーケ、Tech Lead等の関係各位からOKをもらって、ブログ公開までこぎつけることができました。ふーーー。
このCloud Vision Bot君は、12/6に開催されるGoogle HackFair Tokyo 2015に持っていく予定なので、実物を見たい方はぜひお立ち寄りくださいね(ただし、ボット君の調子悪いとデモできないかもしれません)。
まだまだすごいCloud Vision API
今回のビデオでは紹介できてないCloud Vision APIのスゴ機能がいくつかあります。その一つはOCR。例えば、こんな画像も:

こんなふうに認識できます。
{
"textAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 213,
"y": 167
},
{
"x": 539,
"y": 167
},
{
"x": 539,
"y": 826
},
{
"x": 213,
"y": 826
}
]
},
"description": "INFORMATION
4月11日
13:30-19:00
Google Cloud Platform User Group
最新のヒッグテータ解析,モハイルアフリ開発を学ぶ~
GCPUG
▽こんな方におすすめ
"ビッグデータ解析に興味がある
·スケールするビジネスを考えている
モバイルアプリ開発を自社で行いたい
最新技術をキャッチアップしたい
クラウド活用を考えており、事例を知りたい
自社でクラウド活用しており、情報交換したい
▽持ち物
筆記用具
·ノートPC (ハンズオンワークショッフで使用)
▽参加費-
500円(交流会費)
▽定員
別途申し込みが必要です。詳しくはスタッフまで。
30名
STARTUP CALL
岡~
垣E
rフ
2
",
"locale": "ja"
}
]
}
多言語対応、斜めの文字でも読めてしまうOCRです。
また、「Safe Search検知」を使うと、Google検索のセーフサーチと同様に、画像の内容が安全かどうかを検知できます。これを使えば、例えばユーザーから画像のアップロードを受け付けてシェアしたりアイコンに使っているあらゆるサービスで、手作業による不適切画像のチェックの労力を大幅に下げられます。「ロゴ検知」を組み合わせれば、製品ロゴなどが含まれてはマズい用途での画像チェックに使ったり、逆にeコマースサイトでの商品画像への自動タグ付けに使えたりするかもしれません。
Cloud Vision API、お試しあれ
というわけで、Cloud Vision APIのローンチを無事迎えることができました。ディープラーニングや機械学習について何も知らないエンジニアでも、Googleの最新の画像認識技術の恩恵に預かれるサービス。すでにAlpha版をご評価いただいたお客様からも、「他のソリューションと比べて認識品質に差がありすぎて比較にならない」と絶賛いただいています。現在はまだLimited Preview、つまりお試し版なので、コストはかかりません。ぜひにサインアップして、その実力を確かめてみてください。
Disclaimer この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。