2015-11-29
■[深層学習][chainer]ChainerでマルチGPUに挑戦する 
とにかくマルチGPUがやりたい。
なぜならそこにGPUがあるから。
しかしimagenetはマルチGPUのサンプルがない。
見よう見まねでやってみたがなんかおかしい。
そこでchainerのサンプルでは唯一マルチGPUをやってるMNISTで練習することにした。
まず抑えておきたいのは、マルチGPU処理にはモデル並列化とデータ並列化の二種類があるということ。

モデル並列化の場合、ニューラルネットワークを定義する段階でマルチGPUにしてしまう。
チュートリアル*1に書いてある内容そのままだと動かないのでexamplesのnet.pyから抜粋するとこんな感じ
class MnistMLP(chainer.Chain): """An example of multi-layer perceptron for MNIST dataset. This is a very simple implementation of an MLP. You can modify this code to build your own neural net. """ def __init__(self, n_in, n_units, n_out): super(MnistMLP, self).__init__( l1=L.Linear(n_in, n_units), l2=L.Linear(n_units, n_units), l3=L.Linear(n_units, n_out), ) def __call__(self, x): h1 = F.relu(self.l1(x)) h2 = F.relu(self.l2(h1)) return self.l3(h2) class MnistMLPParallel(chainer.Chain): """An example of model-parallel MLP. This chain combines four small MLPs on two different devices. """ def __init__(self, n_in, n_units, n_out): super(MnistMLPParallel, self).__init__( first0=MnistMLP(n_in, n_units // 2, n_units).to_gpu(0), first1=MnistMLP(n_in, n_units // 2, n_units).to_gpu(1), second0=MnistMLP(n_units, n_units // 2, n_out).to_gpu(0), second1=MnistMLP(n_units, n_units // 2, n_out).to_gpu(1), ) def __call__(self, x): # assume x is on GPU 0 x1 = F.copy(x, 1) z0 = self.first0(x) z1 = self.first1(x1) # sync h0 = z0 + F.copy(z1, 0) h1 = z1 + F.copy(z0, 1) y0 = self.second0(F.relu(h0)) y1 = self.second1(F.relu(h1)) # sync y = y0 + F.copy(y1, 0) return y
うぎゃー
わずか三層のNNを記述するだけでこのややこしさである。
ミソはMnistMLPParallelの__call__の中で、二回分の計算を行っているところだろうか。
syncを二回やってるのも特徴的だ。
とりあえず実行したり比較したりしてみる。
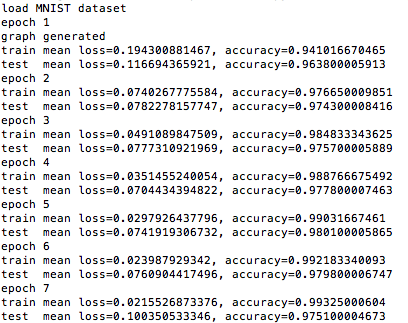
まずは普通に実行した結果
GPUはひとつだけ使っている。

これはモデル並列化を行ったもの。
なんとあまり効果が出てない。
Epoch6くらいまでだと全然シングルGPUと変わらないのだ。
うーむ。
データ並列化も試してみたがどうもうまくいかない。
やはりドワンゴAI研究所の山川先生が言ってたとおり、同じネットワークを複数ノードまたは複数GPUで効率的に学習させるのはけっこう大変なのかもしれない。
とりあえずimagenetをモデル並列化によってマルチGPUで学習するようにしてみた。
class ParallelNIN(chainer.Chain): """An example of model-parallel MLP. This chain combines four small MLPs on two different devices. """ insize = 227 def __init__(self): super(ParallelNIN, self).__init__( first0=nin.NIN().to_gpu(0), first1=nin.NIN().to_gpu(1), ) def __call__(self, x,t): # assume x is on GPU 0 x1 = F.copy(x, 1) t1 = F.copy(t, 1) z0 = self.first0(x,t) z1 = self.first1(x1,t1) # sync y = z0 + F.copy(z1, 0) self.loss = y self.accuracy = self.first0.accuracy return self.loss cuda.get_device(0).use() model = ParallelNIN()
NINのパラレル版を作り、学習させるだけ。
これはラクだ。
これだと改造箇所が最低限で済む。
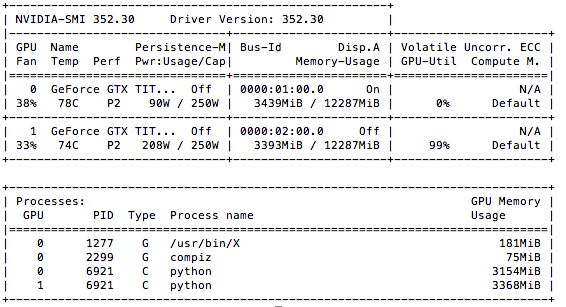
おお、今度はちゃんと二つのGPUがブン回ってる!!
78℃と74℃。結構省電力もブルンブルン変わるので面白い。
このファンの回り方とかもグラフ化したら楽しいだろうなあ
- 305 https://www.google.co.jp/
- 114 http://d.hatena.ne.jp
- 77 https://www.google.co.jp
- 45 https://t.co/s12zZPm78N
- 35 http://www.google.co.uk/url?sa=t&source=web&cd=1
- 32 http://b.hatena.ne.jp/
- 26 https://www.facebook.com/
- 23 https://t.co/5I9kJ3GVYj
- 20 http://www.google.co.jp/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&ved=0CCQQFjAD&url=http://d.hatena.ne.jp/shi3z/20151129/1448761130&ei=XFlaVvqCL-HwoAfsNg&usg=AFQjCNES1K_nkqNeCePME4aAyZCIzeDlDA
- 18 http://www.facebook.com/Gertruda