2015-11-29
■[深層学習][chainer]Chainerのimagenetを可視化する 
皆さんChainerやってますか?
前回はcaffenetの可視化に挑戦しましたが、imagenetだとまたいろいろ盛大に違いました。
imagenetの方が汎用性が高いので、今回はimagenetの可視化に挑戦したいと思います。
特にChainer1.5になってからサンプルがかなり書き換わって使いやすくなっているので、特にimagenetのtrain_imagenet.pyは機能が豊富で便利です。
graphvizでネットワークを可視化できるようになっているのも素晴らしい。
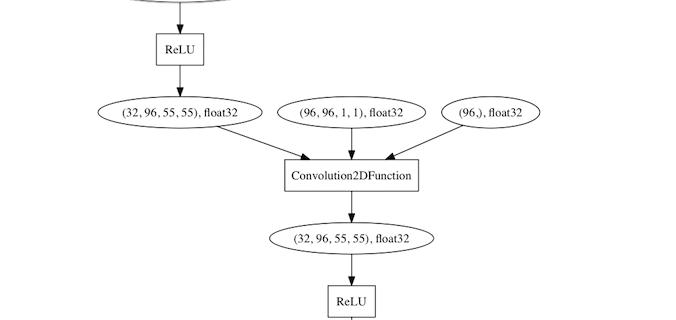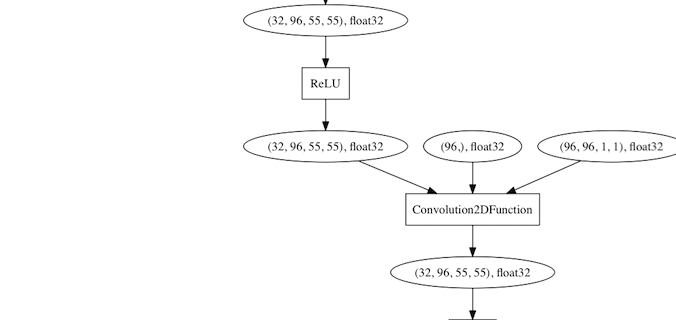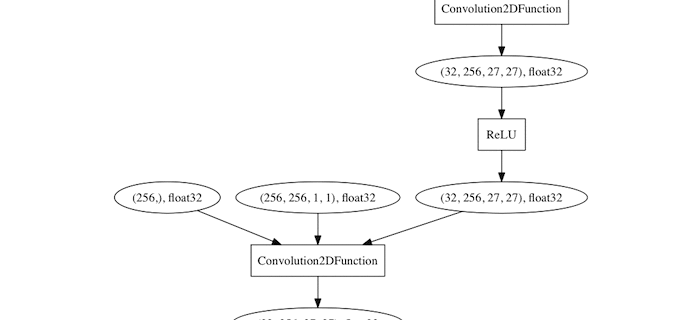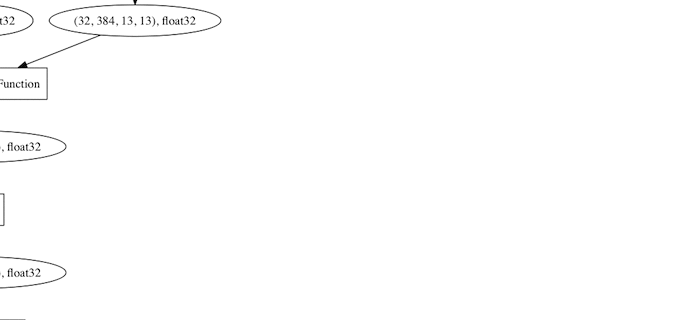
そこで層を可視化するためにいろいろ試行錯誤して修正したvisualizer.pyがこれです
import chainer import matplotlib.pyplot as plt import numpy as np import math import chainer.functions as F from chainer.links import caffe from matplotlib.ticker import * from chainer import serializers import nin float32=0 model = nin.NIN() serializers.load_hdf5("gpu0out", model) def plotD(dim,data): size = int(math.ceil(math.sqrt(dim[0]))) if(len(dim)==4): for i,channel in enumerate(data): ax = plt.subplot(size,size, i+1) ax.xaxis.set_major_locator(NullLocator()) ax.yaxis.set_major_locator(NullLocator()) accum = channel[0] for ch in channel: accum += ch accum /= len(channel) ax.imshow(accum, interpolation='nearest') else: plt.imshow(W.data, interpolation='nearest') def plot(W): dim = eval('('+W.label+')')[0] size = int(math.ceil(math.sqrt(dim[0]))) if(len(dim)==4): for i,channel in enumerate(W.data): ax = plt.subplot(size,size, i+1) ax.xaxis.set_major_locator(NullLocator()) ax.yaxis.set_major_locator(NullLocator()) accum = channel[0] for ch in channel: accum += ch accum /= len(channel) ax.imshow(accum, interpolation='nearest') else: plt.imshow(W.data, interpolation='nearest') def showPlot(layer): plt.clf() W = layer.params().next() fig = plt.figure() fig.patch.set_facecolor('black') fig.suptitle(W.label, fontweight="bold",color="white") plot(W) plt.show() def showW(W): plt.clf() fig = plt.figure() fig.patch.set_facecolor('black') fig.suptitle(W.label, fontweight="bold",color="white") plot(W) plt.show() def getW(layer): return layer.params().next() def savePlot2(layer): plt.clf() W = layer.params().next() fig = plt.figure() fig.patch.set_facecolor('black') fig.suptitle(W.label, fontweight="bold",color="white") plot(W) plt.draw() plt.savefig(W.label+".png") def savePlot(W,name): plt.clf() fig = plt.figure() fig.suptitle(name+" "+W.label, fontweight="bold") plot(W) plt.draw() plt.savefig(name+".png") def layers(model): for layer in model.namedparams(): if layer[0].find("W") > -1: print layer[0],layer[1].label savePlot(layer[1],layer[0].replace("/","_")) def layersName(model): for layer in model.namedparams(): print layer[0],layer[1].label def combine(m1,m2): l1i = m1.namedparams() for l2 in m2.namedparams(): l1 = l1i.next() l1[1].data = (l1[1].data + l2[1].data ) * 0.5 return m1 def look(i): for o in i: print o dir(o) def lookName(i): for o in i: print o[1].name plt.gray()
これ、使い方としては、chainer/examples/imagenetのディレクトリ上でまず学習済みモデルを「gpu0out」みたいな名前で保存して、こいつをimportする感じがよろしいかと
chainer/examples/imagenet $>python >>>import chainer >>>import matplotlib.pyplot as plt >>>import numpy as np >>>import math >>>import chainer.functions as F >>>from matplotlib.ticker import * >>>from chainer import serializers >>>import nin >>>model = nin.NIN() >>>serializers.load_hdf5("gpu0out", model) >>>showPlot(model.mlpconv1)
こんな感じでNetwork In NetworkのMLPconv1が視覚化できます。

今回はヒストグラムではなくグレースケールにしてみた。
でもヒストグラムの方が解りやすい気がする。
ところで学習前と学習後のニューラルネットワークを比較するのも面白いのです。
こちらを御覧ください

右が学習前、左が17000イテレーションした後の学習結果です。
変化にご注目下さい。
学習前の初期値は基本的に乱数で与えられます。
それが学習を繰り返すことによってクッキリしてきてるのがわかりますか?
面白いよねこれ
つまりすごーくぼんやりした世界観からだんだんクッキリ、ハッキリした世界観に変わってくるという感じ。人間の脳を模倣しているから当然なんだけど、本当に人間みたいで面白い。
さらに面白いのは、全く同じデータを同じように学習させても、乱数の初期値が違うのでぜんぜん答えが変わってしまうこと。

この左右は、全く同じ学習データセットを与えて同じ構造のニューラルネットワークを同じ回数だけ学習させた結果だ。当然だけど、びっくりするくらい違う。
同じものをみて成長したとしても、初期値が違うから別の人格(学習器)になるというわけ。一卵性双生児でも性格が全く別になってしまう、ということと関係あるかもね。
さて、誰かが2つのニューラルネットワークの平均をとればより強力な学習器になると言ったので実際に試してみた。
まず、2つのニューラルネットワークの平均をとるプログラムを書く
def combine(m1,m2): l1i = m1.namedparams() for l2 in m2.namedparams(): l1 = l1i.next() l1[1].data = (l1[1].data + l2[1].data ) * 0.5 return m1
そしてこの2つのニューラルネットワークを合成した結果がこれ

混ざってなにがなんだかわからなくなってしまった。
この2つの兄弟ネットワークはもともとこういう性能だった。
GPU0 {"iteration": 17000, "loss": 1.0074584587216378, "type": "train", "error": 0.28556250000000005} GPU1 {"iteration": 17000, "loss": 1.0160466693341732, "type": "train", "error": 0.28628125000000004}
しかしこれを単純に足して二で割る、文字通り平均化したネットワークはこんな性能になってしまった。
{"iteration": 1000, "loss": 3.910530016183853, "type": "train", "error": 0.78853125}
lossは4倍、エラーレートは2.5倍くらいに増えてしまった。
乱数から計算し始めるよりはマシだが、かといってアンサンブル学習に成功したとはとても言えない結果になってしまっている。
まあ当然と言えば当然なんだけど。
けれども不思議なのは、TensorFlowのサンプルだ。
なぜあっちはうまくいくのか。
def train(): """Train CIFAR-10 for a number of steps.""" with tf.Graph().as_default(), tf.device('/cpu:0'): # Create a variable to count the number of train() calls. This equals the # number of batches processed * FLAGS.num_gpus. global_step = tf.get_variable( 'global_step', [], initializer=tf.constant_initializer(0), trainable=False) # Calculate the learning rate schedule. num_batches_per_epoch = (cifar10.NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN / FLAGS.batch_size) decay_steps = int(num_batches_per_epoch * cifar10.NUM_EPOCHS_PER_DECAY) # Decay the learning rate exponentially based on the number of steps. lr = tf.train.exponential_decay(cifar10.INITIAL_LEARNING_RATE, global_step, decay_steps, cifar10.LEARNING_RATE_DECAY_FACTOR, staircase=True) # Create an optimizer that performs gradient descent. opt = tf.train.GradientDescentOptimizer(lr) # Calculate the gradients for each model tower. # Calculate the gradients for each model tower. tower_grads = [] for i in xrange(FLAGS.num_gpus): with tf.device('/gpu:%d' % i): with tf.name_scope('%s_%d' % (cifar10.TOWER_NAME, i)) as scope: # Calculate the loss for one tower of the CIFAR model. This function # constructs the entire CIFAR model but shares the variables across # all towers. loss = tower_loss(scope) # Reuse variables for the next tower. tf.get_variable_scope().reuse_variables() # Retain the summaries from the final tower. summaries = tf.get_collection(tf.GraphKeys.SUMMARIES, scope) # Calculate the gradients for the batch of data on this CIFAR tower. grads = opt.compute_gradients(loss) # Keep track of the gradients across all towers. tower_grads.append(grads) grads = average_gradients(tower_grads)
これをみるとネットワークそのものではなく勾配だけを平均化しているようだ。
average_gradientsの中身はこれ
def average_gradients(tower_grads): """Calculate the average gradient for each shared variable across all towers. Note that this function provides a synchronization point across all towers. Args: tower_grads: List of lists of (gradient, variable) tuples. The outer list is over individual gradients. The inner list is over the gradient calculation for each tower. Returns: List of pairs of (gradient, variable) where the gradient has been averaged across all towers. """ average_grads = [] for grad_and_vars in zip(*tower_grads): # Note that each grad_and_vars looks like the following: # ((grad0_gpu0, var0_gpu0), ... , (grad0_gpuN, var0_gpuN)) grads = [] for g, _ in grad_and_vars: # Add 0 dimension to the gradients to represent the tower. expanded_g = tf.expand_dims(g, 0) # Append on a 'tower' dimension which we will average over below. grads.append(expanded_g) # Average over the 'tower' dimension. grad = tf.concat(0, grads) grad = tf.reduce_mean(grad, 0) # Keep in mind that the Variables are redundant because they are shared # across towers. So .. we will just return the first tower's pointer to # the Variable. v = grad_and_vars[0][1] grad_and_var = (grad, v) average_grads.append(grad_and_var) return average_grads
でもなあ、勾配だけ平均化して意味はあるのだろうか。
最後は結局ひとつのニューラルネットワークにしなければならないわけで・・・
うーむ
まあ原典をあたるか
Note that each GPU computes inference as well as the gradients for a unique batch of data. This setup effectively permits dividing up a larger batch of data across the GPUs.
This setup requires that all GPUs share the model parameters. A well-known fact is that transferring data to and from GPUs is quite slow. For this reason, we decide to store and update all model parameters on the CPU (see green box). A fresh set of model parameters is transferred to the GPU when a new batch of data is processed by all GPUs.
The GPUs are synchronized in operation. All gradients are accumulated from the GPUs and averaged (see green box). The model parameters are updated with the gradients averaged across all model replicas.
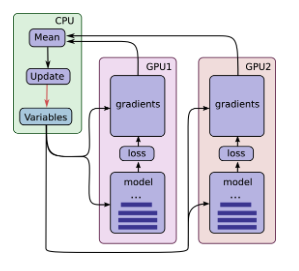
ガーン。なるほど
説明文に書いてあったよ(ソースから読む癖をやめよう)
要するに、GPU間でニューラルネットワークを転送するのが遅いので毎回CPU側でモデルを更新して、学習用バッチとモデルを都度2つのGPUに転送して勾配だけ反映させる、と。アンサンブル学習じゃないのか。
勾配だけなら確かに平均とればなんとかなるかなあ。
うーん、これをChainerで実装するには・・・やっぱりtrain_imagenet.pyを書き換えるしかないのか
最近のはけっこう複雑かつ便利になってるからあんまり構造弄りたくないんだけどなあ
- 26 https://t.co/s12zZPm78N
- 19 https://www.google.co.jp/
- 5 https://www.google.co.jp
- 4 https://www.facebook.com/
- 3 http://openblog.meblog.biz/article/26627563.html
- 2 http://reader.livedoor.com/reader/
- 2 http://search.yahoo.co.jp/search?ei=UTF-8&fr=mcafeess1&p=プログラマー+ドラマ
- 2 http://www.facebook.com/Gertruda
- 2 http://www.google.co.jp/search?client=firefox-a&hl=ja&ie=utf-8&lr=lang_ja&num=50&oe=utf-8&output=atom&q=ipad&tbm=blg&tbs=sbd:1
- 2 http://www.google.co.jp/search?ie=Shift_JIS&q=モルフィーワン&btnG=検索