2015-08-11
■人工知能調教日記 Selective Searchの限界をブルートフォースで越えようとしてみる
今年のSIGGRAPHのTechnical PaperはDeep Learningを使った研究もけっこう出てきたが、今のところ動きの生成や画像処理(ポストエフェクト)に使うのがメインらしく、これといって「すげえ!」という研究が出てきていない印象だった。
まあディープラーニングが本格的にヤバイ!という感じになったのが昨年末くらいだから仕方ないのかもしれない(SIGGRAPHの論文締め切りは1/7)。となると11月のSIGGRAPH ASIA(神戸で開催)には多少の期待ができるだろうか。
さて、飛行機の中で試してみたSelective Searchだが、前回試してみた結果、ヒストグラムの分析では人物がうまく検出できないという問題を指摘した。
そこでとりあえずブルートフォースでやってみた。
結果が下図である。

ブルートフォースらしく、基本的にどこでもなんでも選んでしまうが、それぞれ「これは!」という自信のあるところ(正答率が70%くらいのところ)だけを抜き出してみても、まあ全力で的はずれである。
どうもこの写真は人工知能がとてつもなくニガテとしているらしく、全くと言っていいほど当たらない。
どこもかしこもタバコに見えてしまうというのは「おまえ目がおかしいのか!?」と思ってしまうが、それもこれもカリフォルニアで調教されたダメな人工知能だからであろう。
仕方がないのでまるで狂ったように男性と女性、ついでにクルマとドローンをLabell.ioで教えてみた。
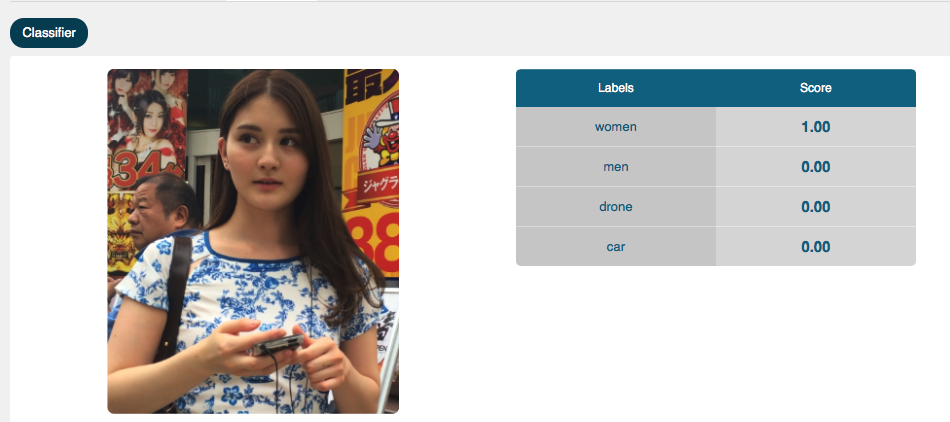
さすがに「この人は女性ですよ」と教えると、100%女性と判定される。
しかし、見せたことのない女性の画像を見せるとときどき男と誤認識する(クルマやドローンに誤認識はされない)。
原因を調べてみたら、男の画像が200あって、女性の画像が100しかなかった。
女性を男性と誤認識する方が男性を女性と誤認識するよりも精神的ダメージがデカイ(なぜか)ので、なんとかネットで検索して女性のデータを増やした。
ついでにクルマのデータも増やして、さらにショップのデータも増やした。
ある特定のクラスのデータだけたくさん学習させると過学習といって、何を見てもソレに見えてしまう。
これ人間に適用してもなかなかすごい教訓だと思うんだよね。
よく言うのは、「人は金槌を持っていると全てが釘に見える」ということでもあり、アホな男にばっかり引っかかってると「男ってみんなアホ」と思い、吉野家ばっかり食ってると「牛肉って部位によって味が違ったりしないよね」と思うという、要するにどれかひとつにのめり込むと他のものが見えなくなるという典型的な症状なのだけど、人工知能を学習させるにもバランスが重要である。
また、いわゆるカメラマンがスタジオでバッチリ撮ったような「キレイキレイ」な写真だけを見せても、背景に写ってるオッサンをヒトだと正しく認識できないので解像度はさておいて(というのも、どうせ256x256に縮小されてそのあと畳み込まれるわけなので)、背景になってるオッサンとかもきっちりと拾った方がいい。
また、CNNの認識にはいろんな流儀があって、まあ元データが縦長でも横長でも引き伸ばされてしまう問題(別名水着ギャルと相撲取り勘違い問題)が引き起こされてしまうが、これはしかし、入力するデータの縦横比を保存しておいて、ニューラルネットワークの外の段階で「これは横に太いからおそらく相撲取り」とアタリをつけておけば或いは分解が簡単かもしれない(そんなやり方がニューラルネットワーク的に正しいかどうかは疑問だが)。
例えば、人間をたくさんキャプチャすると、基本的に人間のシルエットは縦長なのであるが、これをCNNに突っ込むと基本的には横に引き伸ばされてしまう。
とすると、人間以外のものも人間に見えるようになる。
画面全体を認識する単純なCNNでは、これはもう諦めるしかなかった(またはクロップするか隙間をノイズで埋めるか)のだが、ブルートフォースで部分認識をするんだったらもっと融通がきく(というかSelective Searchでも認識する前に縦横比が決まるので融通が利く)。例えば、ラベルごとに縦横比(正方形に近いか、縦長か横長か、くらいの三分類でいいと思う)を持っていて、「縦長なら縦長以外のラベルはどんなにスコアが高くても無視する」みたいな方針にすれば精度を上げることはできそうだ。
ブルートフォースも、もう少し改良して、例えば「立った人間のカラダらしきものを探すタスク」とか、「人間の顔らしきものを探すタスク」とか、「建物らしきものを探すタスク」とかに分けてしまえば、もうちょっと精度を上げることが出来そうな気がする。
ここ数ヶ月、いろんなものを学習させたり認識したりさせてきてわかってきたのは、「アルゴリズムを云々する以前に、利用環境と応用方法を決めてから、学習(調教)データを集めるべき」ということだ。
たとえばそのニューラルネットワークを監視カメラでの万引き検出に使うのであれば、監視カメラの映像から万引き犯を切り出すという作業を人力で行って、それを学習させないとほとんど意味がない。
大学の研究室やコンテストで使われるような、一般物体認識のタスクをいくら極めても、ノーフリーランチ定理によって本当に効果的な解にはなかなか辿り着かない。
携帯電話のカメラで撮影された画像から一般物体認識させるなら、携帯電話のカメラで撮影した画像に限定して学習データを集めたほうが精度が上がるし、要するにアルゴリズムより先に具体的な利用法をイメージしてから適切なサンプルを集めなくてはならないのである。
この学習サンプル集め、というのがまさしくブルートフォース(力任せ)であるため、実際にやるには人海戦術か忍耐力が必要だが、数百サンプルくらいだったら自分で頑張ればものの数時間で集めることもできなくもないのが昨今である。

試しに主導ブルートフォース(インチキ)でニガテと思われる画像のケンタッキー部分だけを認識させたらちゃんと「ショップ」と認識できた。
このケンタッキーの写真そのものは学習データには入れてないので、運良くブルートフォースでこのへんに当たればちゃんとケンタッキーと認識されるはずだ。
ずっと無視されていた人物に関しても
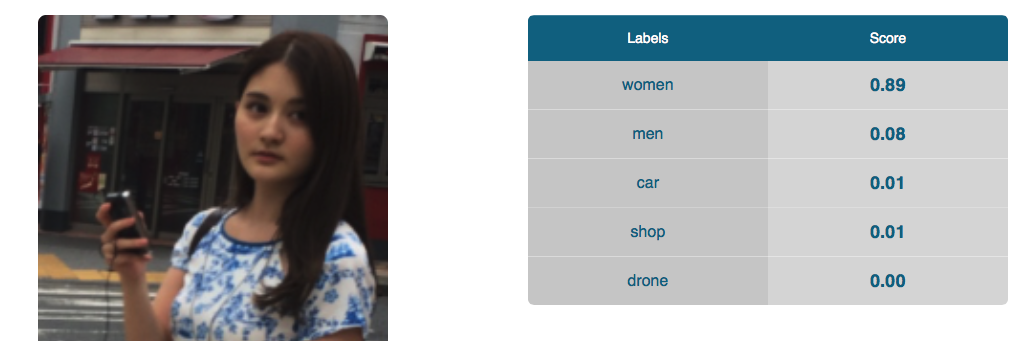
というかんじで89%女性と判定された。
0.1%クルマに見えるのは、たぶんスマートフォンか背景のせいだろうか。

このヘンの背景だと難しいらしい。

このくらいまで絞り込んでもクルマだという確信が持てないようだ。
これも学習データを工夫すればなんとかなるかもしれない。
ところで背景の女性だが、これだけを切り抜いて判定すると
[
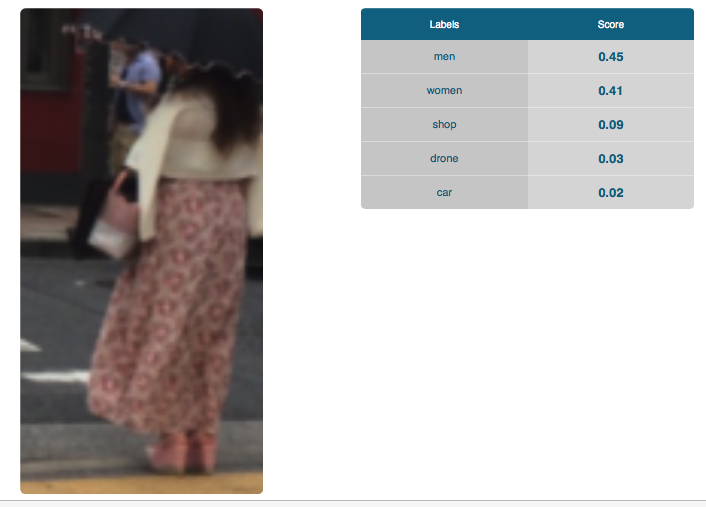
男性か女性か半々だという。まあ確かに難しいかもしれない。
これも学習データをもっと見せないとならないだろうな。
人間を含む動物の場合、リアルタイムに大量の画像が入ってくるので学習データを集めやすい。
特にオブジェクトトラッキングが正確に行えると(これはディープラーニング以前の技術でもできる)、学習効率がとてもいい。つまり「アレ」をいろんな角度、いろんな動き、いろんな方向から眺めることができるので、猛烈に学習データが溜まるのである。
ところで現状のalpacaさんが提供しているSelective Searchにはもうひとつ問題点がある。
ヘタするとブルートフォースより遅いのだ。
これは結構致命的で、下手にヒストグラム分析をするくらいなら、もう少し恣意的なブルートフォースの方が早く正しい答えにたどり着ける可能性がある。
「恣意的な」というのは、たとえば一眼レフカメラのオートフォーカス的な意味だ。
あれも高級機であればあるほど測距点が増えるんだけれども、測距点の配置や優先順位というのは、「写真とはだいたいこのように撮られるものである」という人間側の作り込み(恣意)によって決められている。それでだいたい文句は出ないのだから、それはそれであっているのだろう。
ただ、本格的に学習させるなら、オブジェクトトラッキングで大量の学習データを集めるに限るんじゃないかなと思う。
そしたら単に町中でカメラを回しっぱなしにすれば勝手に学習できちゃうかもしれないし。
そりゃ楽観的すぎるかな。
Permalink | 08:39
- 43 http://t.co/26qL09rMXs
- 16 https://www.google.co.jp/
- 11 https://www.facebook.com/
- 6 http://pipes.yahoo.com/pipes/pipe.info?_id=7ed2910a6358c42a7305fae463b19704
- 6 https://www.google.co.jp
- 3 http://www.google.co.uk/url?sa=t&source=web&cd=1
- 2 http://bit.ly/1ThPxhB
- 2 http://pipes.yahoo.com/pipes/pipe.run?_id=32083ad163d5a74d43db81b9911ba9ea&_render=rss
- 2 http://reader.livedoor.com/reader/
- 2 http://www.google.co.jp/url?sa=t&rct=j&q=&esrc=s&source=web&cd=15&cad=rja&uact=8&ved=0CDYQFjAEOApqFQoTCOLD44rdn8cCFYeQlAod278Cww&url=http://d.hatena.ne.jp/shi3z/20150505/1430791754&ei=lDvJVeKpB4eh0gTb_4qYDA&usg=AFQjCNHNCrJ84Sr8t4mb429aOs4kBqP7