2015-07-14
■Chainerのptbサンプルを解説しつつ、自分の文章を深層学習させて、僕の文章っぽい文を自動生成させてみる
未踏合宿中もディープラーニングを勉強しておきたかったのでとりあえずAmazon AWSのg2.xlargeサーバーをセットアップ(これが既に地獄)して、ptbサンプルを実行してみた。
このサンプルはptb(Penn Tree Bank)をLSTM(Long Short Term Memory)を使ったリカレントニューラルネットワーク(RNN)で学習する。元の論文はこれ→http://arxiv.org/pdf/1409.2329v4.pdf
LSTMとは、まあ極めてザックリ言うと、過去の出力を
入力できる活性化関数である(ザックリすぎる)。
このサンプルのニューラルネットワークを記述している部分は極めて短い
model = chainer.FunctionSet(embed=F.EmbedID(len(vocab), n_units),
l1_x=F.Linear(n_units, 4 * n_units),
l1_h=F.Linear(n_units, 4 * n_units),
l2_x=F.Linear(n_units, 4 * n_units),
l2_h=F.Linear(n_units, 4 * n_units),
l3=F.Linear(n_units, len(vocab)))
ここで、vocabとは、読み込んだ文章の単語をリスト化したディクショナリ(他の言語で言うところの連想配列)である。
これを作っているところは次の関数だ
def load_data(filename): global vocab, n_vocab words = open(filename).read().replace('\n', '<eos>').strip().split() dataset = np.ndarray((len(words),), dtype=np.int32) for i, word in enumerate(words): if word not in vocab: vocab[word] = len(vocab) dataset[i] = vocab[word] return dataset
要するに、文章を入力→単語単位で分解してvocabに突っ込む、単語ひとつひとつをひとつのニューロンに対応させて学習させ、次の単語を予想させる、というわけ。
さて、リカレントニューラルネットワークといえば、ネットワークの中で前の状態を再び戻してやらないといけない。その処理がパッと見、ニューラルネットワークの定義には書いてない。
Chainerでは、層の定義そのものは.FunctionSetのコンストラクタで行うが、層の結合の状態についてはforward関数を定義することによって行うのだ。
実際のforward関数は以下
def forward_one_step(x_data, y_data, state, train=True): if args.gpu >= 0: x_data = cuda.to_gpu(x_data) y_data = cuda.to_gpu(y_data) x = chainer.Variable(x_data, volatile=not train) t = chainer.Variable(y_data, volatile=not train) h0 = model.embed(x) h1_in = model.l1_x(F.dropout(h0, train=train)) + model.l1_h(state['h1']) c1, h1 = F.lstm(state['c1'], h1_in) h2_in = model.l2_x(F.dropout(h1, train=train)) + model.l2_h(state['h2']) c2, h2 = F.lstm(state['c2'], h2_in) y = model.l3(F.dropout(h2, train=train)) state = {'c1': c1, 'h1': h1, 'c2': c2, 'h2': h2} return state, F.softmax_cross_entropy(y, t)
お、おう。
これはどういうことだってばよ。
もとの論文を見ると図もあるが・・・
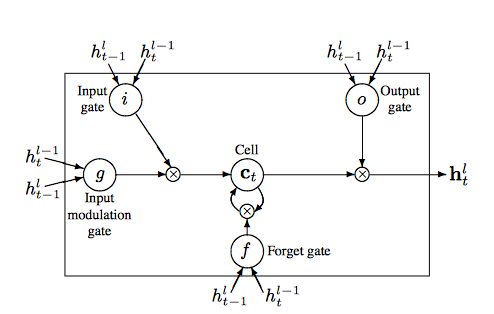
おおう・・・・まあ論文ってこんなもんだよな。
しかしプログラマー的にはこのままだとちょーーっと複雑でよくわからんので変数の流れベースで図にしてみる。
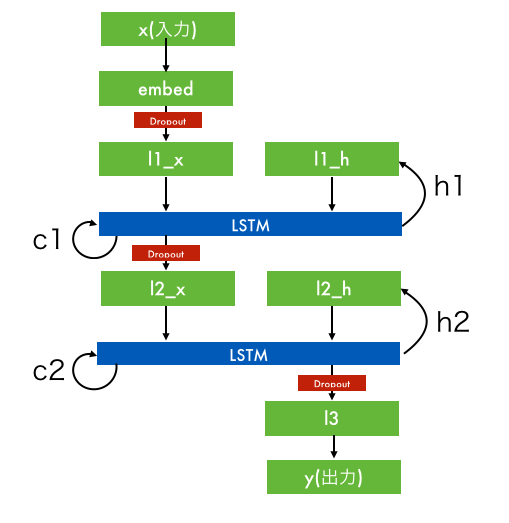
こんなもんだろう。
いつものようにx_dataに入力データ、y_dataに教師データを入れる。いつもと違うのは、stateを渡すということ。このstateに状態が保存される。と。
なるほどなるほど、F.lstm(ChainerのLSTM活性化関数)で直前の状態(l1_hとl2_h)を再度入力しつつ自分の状態(c1,c2)を保持するニューラルネットワークになってるっちゅーわけね。
しかしいつもながらChainerの標準でついてくるサンプルコードは学習が進んでいることはわかるが学習が進んだ結果どのような推定ができるようになったか可視化されない。
んで、何を学習させるかである。
英語でやったら、そもそも英語で何が書いてあるのかわからんのであまりにも難しくなってしまった。
日本語がいい。するとちょうどいいものが山ほどあることに気づいた。
そう。僕の本の原稿である。
- 作者: 清水亮
- 出版社/メーカー: クロスメディア・パブリッシング(インプレス)
- 発売日: 2015/07/24
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (2件) を見る
しかし今日になってもカバー画像が更新されていない。やる気があるのか。
まあいいや。こいつの原稿の出だしはこんな感じだ。
#最速の仕事術はプログラマーが知っている
##はじめに
「最速」
それはプログラマーなら誰もが心がけているキーワードである。
プログラマーにとって最も重要な関心事は、効率化だ。
熟練したプログラマーほど実際にはキーボードに向かわなくなるという。
なぜか?
それは、プログラミングに熟達すればするほど、むしろコードをガリガリ書く時間よりも書かない時間にこそ仕事の真髄があると解るからだ。
熟練プログラマの仕事は一瞬で終わる。素人が数か月、ああでもないこうでもないと大騒ぎしてやっと終わるような仕事も、ものの数時間で終わらせるスーパープログラマーは確かに存在する。
世界でもプログラマーほど個人の生産性の違いに大きな差がある職業も珍しい。
執筆時点で、世界最速の男は100メートルを9秒58で走るウサイン・ボルトだ。彼が人類最速の男だとしよう。筆者は趣味でジョギングをしているが、1キロ走るのにだいたい5分かかる。ということはそのペースだと100メートルに30秒はかかることになる。スプリントレースとジョギングでは大きく異なるが、同じ「走る」という行為で比較すると、人類最速の男と、一般的中年男性の運動能力にはざっと10倍の差があるということがわかる。
だが熟練したプログラマーは、軽々と素人の何百倍、何億倍という効率の差を見せる。
<<
まあ良くも悪くも僕らしい血圧高めのテンションだ。
こいつを学習させると、きっと僕のかわりにブログを書きアフィリエイトを稼ぎ、原稿料と印税とその他諸々の金を稼ぐ無垢でピュアなアーティフィシャルサピエンスができるはずだ。
マジか。
いいのかPFI。僕はもうシンギュラリティの向こう側に行っちゃうよ?
とはいえとはいえ、もとが英文用なので、単語や品詞で区切る必要がある。
そこでmecabを使ってちゃちゃっと品詞にスペース区切りを入れてみる
$ mecab src.txt -F "%m "|sed -e "s/EOS//g" > train.txt
ちゃんと区切れたかどうか一応確認する
例えば 、 こん な こと と あった 。
アメリカ の ボストン の 北 に ある 大学 で 特別講義 を や ったとき の ことだ 。
筆者 は 生徒たち を 前 に 、 「 今 から 90秒以内 に ゲーム を 作って見せます 」 と言って実際 に 彼ら に 時間 を 測るよう言った 。
それ から 実際 に そ の 場 で ゲーム を プログラミング した 。
実際 に 「 完成 」 と言うま で に 要 した 時間 は 46秒だった 。
すると生徒 の 一人 と たまらず笑い始めた 。
そ の 笑い は な ぜか向こう の 教師 に も広 と り 、 しまい に は 教室全体 と 笑い に 包まれた 。
「 どういうことだ? 」
筆者 と や や ムッ として 聞くと 、 最初 に 笑い始めた彼 と 言った 。
「 い や 、 実 は 我々 と こ の 二週間 、 ゲームプログラミング の 課題 と 出て 、 これま で 散々四苦八苦し な と らよう や く出来た という の に 、 あ な た は 46秒 で や ってしまった から 驚いて笑ってしまったん で す 」
これ は とても特殊 な 例 だろう か 。
筆者 は そう は 思わ な い 。
んー、なんかところどころへんなところはあるが、とりあえずこれでいいや。
これと同程度に狂った文章をゴトー博士(無垢な人造ニューラルネットワーク)に投げ込めば、適当に日本語にしてくれるだろう。
これを適当に3分割して、train.txt、valid.txt、test.txtを作る。
よし、学習せよ!!
$ python train_ptb.py -g 0 > log.txt & $ tail -f log.txt ('#vocab =', 8522) going to train 12753000 iterations evaluate epoch 1 validation perplexity: 800.79 evaluate epoch 2 validation perplexity: 910.35 evaluate epoch 3 validation perplexity: 752.37 iter 10000 training perplexity: 292.33 (42.93 iters/sec) evaluate epoch 4 validation perplexity: 790.90 evaluate epoch 5 validation perplexity: 812.07 evaluate epoch 6 validation perplexity: 821.11 ('learning rate =', 0.8333333333333334) iter 20000 training perplexity: 82.24 (43.33 iters/sec) evaluate epoch 7 validation perplexity: 994.00 ('learning rate =', 0.6944444444444445) evaluate epoch 8 validation perplexity: 1008.50 ('learning rate =', 0.5787037037037038) evaluate epoch 9 validation perplexity: 1092.06 ('learning rate =', 0.48225308641975323) iter 30000 training perplexity: 47.08 (43.32 iters/sec) evaluate epoch 10 validation perplexity: 1199.59 ('learning rate =', 0.401877572016461) evaluate epoch 11 validation perplexity: 1318.59 ('learning rate =', 0.3348979766803842) evaluate
まあとにかく学習が進んだことだけわかる。
このptbサンプルに関しては学習済みのモデルを保存さえしないので、保存するように変更してみる。
train_ptb.pyの138行目あたりを
if (i + 1) % 10000 == 0: now = time.time() throuput = 10000. / (now - cur_at) perp = math.exp(cuda.to_cpu(cur_log_perp) / 10000) print('iter {} training perplexity: {:.2f} ({:.2f} iters/sec)'.format( i + 1, perp, throuput)) cur_at = now cur_log_perp.fill(0) pickle.dump(model, open('model%04d' % (i+1), 'wb'), -1) #これを追加
こんな感じで最後の行を追加する。
すると10000ステップごとにモデルを保存するようになる。
保存されたモデルを使って推定するには別のプログラムを書く必要がある。
今回はとりあえずの結果だけ見たかったので、train_ptb.pyを改造してこんな雑なコードを書いてみた。
#!/usr/bin/env python """Sample script of recurrent neural network language model. This code is ported from following implementation written in Torch. https://github.com/tomsercu/lstm """ import argparse import math import sys import time import numpy as np import six import six.moves.cPickle as pickle import chainer from chainer import cuda import chainer.functions as F from chainer import optimizers parser = argparse.ArgumentParser() parser.add_argument('model', help='Trained model') #パラメータ modelを追加(必須) parser.add_argument('--gpu', '-g', default=-1, type=int, help='GPU ID (negative value indicates CPU)') args = parser.parse_args() mod = cuda if args.gpu >= 0 else np n_units = 650 # number of units per layer batchsize = 20 # minibatch size bprop_len = 35 # length of truncated BPTT grad_clip = 5 # gradient norm threshold to clip # Prepare dataset (preliminary download dataset by ./download.py) vocab = {} inv_vocab={} #逆引き辞書 def load_data(filename): global vocab, n_vocab words = open(filename).read().replace('\n', '').strip().split() dataset = np.ndarray((len(words),), dtype=np.int32) for i, word in enumerate(words): if word not in vocab: vocab[word] = len(vocab) inv_vocab[len(vocab)-1]=word dataset[i] = vocab[word] return dataset train_data = load_data('train.txt') valid_data = load_data('valid.txt') test_data = load_data('test.txt') print('#vocab =', len(vocab)) whole_len = train_data.shape[0] jump = whole_len // batchsize print("jump =",jump) if args.gpu >= 0: cuda.init(args.gpu) # Prepare RNNLM model model = pickle.load(open(args.model,'rb')) #モデルをロード def forward_one_step(x_data, y_data, state, train=True): if args.gpu >= 0: x_data = cuda.to_gpu(x_data) x = chainer.Variable(x_data, volatile=not train) h0 = model.embed(x) h1_in = model.l1_x(F.dropout(h0, train=train)) + model.l1_h(state['h1']) c1, h1 = F.lstm(state['c1'], h1_in) h2_in = model.l2_x(F.dropout(h1, train=train)) + model.l2_h(state['h2']) c2, h2 = F.lstm(state['c2'], h2_in) y = model.l3(F.dropout(h2, train=train)) state = {'c1': c1, 'h1': h1, 'c2': c2, 'h2': h2} return state, F.softmax(y) #ここを改造 def make_initial_state(batchsize=batchsize, train=True): return {name: chainer.Variable(mod.zeros((batchsize, n_units), dtype=np.float32), volatile=not train) for name in ('c1', 'h1', 'c2', 'h2')} # Evaluation routine def evaluate(dataset): sum_log_perp = mod.zeros(()) state = make_initial_state(batchsize=1, train=False) data = dataset[101:] #適当な単語を選ぶ rand = np.random.uniform(0.0, 1.0,dataset.size) for i in six.moves.range(dataset.size - 1): #ループの数は適当なのでとりあえずこのまま x_batch = data[0:1] #最初の単語だけを渡す print(inv_vocab[x_batch[0]]), #逆引き辞書を使って単語を表示 state, predict = forward_one_step(x_batch, x_batch, state, train=False) score = cuda.to_cpu(predict) top_k=1 prediction = zip(score.data[0].get().tolist(), vocab) prediction.sort(cmp=lambda x, y: cmp(x[0], y[0]), reverse=True) m = rand[i] #乱数 total = 0.0 for rank, (score, name) in enumerate(prediction, start=1): data[0] = vocab[name] #最初の単語を推定した単語に更新する if total>m : #推定された単語の確率にしたがって単語を選ぶ break total += score return math.exp(cuda.to_cpu(sum_log_perp) / (dataset.size - 1)) # Evaluate on test dataset test_perp = evaluate(train_data)
中身はほとんどtrain_ptb.pyのまんまなんだけど、逆引き辞書を作ったり、モデルを読み込んだり、Softmax_cross_entropyではなくてSotfmat関数を使って次の単語を推定したりして、文章を生成するようにしている。
最初は一番可能性が高い候補だけを選択していたんだけど、堂々巡りになってとても文章を自動生成してるというところまでいかなかった。そこで昨日のニコ生のゲストだったドワンゴ人工知能研究所の中村さんに聞いたら、「一番上のやつだけにすると堂々巡りになるので、確率分布に従って単語選択すべし」とのことだったので、そのようにした。
とりあえず最初の10000回の学習をしたときのモデルで最初の単語に「最速」を選ぶと、次のようになった。
$ python pred.py model10000 -g 0 ('#vocab =', 8427) ('jump =', 3269) 最速 鈍り かまわ 生命 起きる 踏ま 掴む 両論 ぼうっと 痛い ヒット 両論 作成 圧倒的 充実 こぎつけ あえて 高め 追い込ん ガン 断じて こぎつけ ガン 始め ばか あえて 項目 みよ 条件 寸前 みよ 起きる どっち 奇しくも 資源 及ぶ 取り返し 思う そりゃあ 寸前 取り入れ 発展 パッケージ 出し こぎつけ 対応 出し 寸前 両論 効き かけれ 似 数式 入る 傲慢 建て 当たり 出し ガン 半年 論文 細か 発展 高 及ぶ 記事 食わさ 高揚 出足 事 広告 すぎ 過ぎ しま 言え 一目 高め アスラテック ガン 言え 体調 鈍り 取り返し あえて あえて 設定 うん 両論 あえて 99999 基調 みよ 起きる 発展 柄 設定 掴む 寸前 21 電子 あえて 両論 Surface ガン 出し 寸前 売り場 出し あえて 掴む カール ガン 言え 高め 覚えよ 誤っ 職能 SIGGRAPH あえて 及ぶ A /) 主催 ガン 書類 豊富 分析 付 融合 コミュニケーション 両論 あえて あえて 掴む 体調 永久 行列 行列 及ぶ ベル ちゃんと 素早く 取り返し 事 体調 取り返し 寸前 あえて 取り返し 全力 出し 発展 出し NEET コンテスト 出し ガン 両論 掴む 充実 ガン スプリント 呈し PC 寸前 論文 初期 だす 出し 至っ 複数 あえて 絶対 追加 作り上げ 言い切れ ガン 出し ZZZY Coding ネジ 側 あえて 呼べる 寸前 出し 起きる 奇しくも 冬 単語 求める 出し 比べる 出し 出し 髪 過ぎ あえて 適用 NEET 当たり 及ぶ あえて 状況 あえて 断じて あえて 磨く 到着 設定 代用 駒 発現 出し 掴む 足し算 両論 散々 亮 出し 事 独自 売り場 あえて 負け犬 発展 リアルタイム 起きる 言え 足し あん 残す 行列 設定 両論 買う ガン しま 体調 出し 無残 あえて 立てる 幸甚 あえて 下段 こぎつけ 出し 発展 Word 出し ガン あえて あえて 分析 社会 こぎつけ 謝り 回分 掴む 発展 宛先 頭字 持ち寄り あえて 踏ま 筋肉 事 比べる ポピュラー 出し 立つ あえて こぎつけ イベント 謝っ 出し 出し ガン 家庭 起きる 言え 取り返し 当たり 流通 画 事 両論 99999 食い扶持 楽しん 先週 金 絶対 事 あえて 両論 コンサルタント ガン 根本 あえて 死 出足 あえて 両論 今日 あえて 掴む ガン 録 だっ 作ら あえて くん まとめ 一目 寸前 今日 どっち ガン あえて あえて 事 二 あえて 求めるんー、さすがに最初のエポックでは文章にならないなあ。
あえてあえてあえて求めるのか。
いつかちゃんとした文章になるんだろうか
それは誰にもわからない・・・・
シンギュラリティは遠い・・・
Permalink | 09:05

購入: 8人 クリック: 49回
- 195 https://www.facebook.com/
- 74 https://www.google.co.jp/
- 65 http://pipes.yahoo.com/pipes/pipe.info?_id=7ed2910a6358c42a7305fae463b19704
- 31 http://feedly.com/i/latest
- 29 http://t.co/o7YQ9UaKE8
- 25 http://feedly.com/i/subscription/feed/http://d.hatena.ne.jp/shi3z/rss2
- 24 https://www.facebook.com
- 22 http://reader.livedoor.com/reader/
- 18 http://www.google.co.jp/url?sa=t&rct=j&q=&esrc=s&source=web&cd=2&sqi=2&ved=0CC0QFjABahUKEwiozPjUmdnGAhWi56YKHWRWACw&url=http://d.hatena.ne.jp/shi3z/20150531/1433032775&ei=pEGkVajqFaLPmwXkrIHgAg&usg=AFQjCNErgbD4wmEI7QEiQtXvD_7pCE9oBA&bvm=bv.976
- 16 http://b.hatena.ne.jp/