2015-06-28
■Hi-KingさんのChainerの解説がとてもわかりやすい
今日、UEIのOBから「ディープラーニング勉強したいんですけど、マシンどうしたらいいですか?」と相談を受けたので、飯食いがてら六本木で飲んだ。
ディープラーニング用マシンとして、とりあえずの入門なら、GeForceGTX 980Tiがあればひとまず大丈夫。VRAMは6GBあるのでひと通りのサンプルはラクに動かせる。電源は大きめのやつ、700Wくらいあれば安心か。
RAMは32GBもあれば充分。
ディスクアクセスが多いのでSSDがあるといい。
ニューラルネットワークを学習させるとけっこう容量食う(Caffeの場合)ので、大きめがいい。480GBくらいあると安心。
OSはUbuntu14.04が基本
これにCUDAとPython2.7を入れて使う。
だいたい20〜30万円くらい。
最近、たまにChainerでTwitter検索してるんだけど、面白い研究が公開されてた。

これは、Chaiherを使ってGoogleのDeep Poseという論文を再現してみた例。
Deep Poseの論文はこれ→http://static.googleusercontent.com/media/research.google.com/ja//pubs/archive/42237.pdf
写真から、人間の姿勢を読み取って学習する。
まあ簡単に言うとKinectのもっとすごいやつだと思えばいい。
けっこう複雑な姿勢も学習できてて凄い。
あと、ニューラルネットワークが久しぶりすぎて最新のネタがよくわからんという僕みたいな人や、そもそもニューラルネットワークってなんですかっていう人には、Hi-KingさんのChainer入門が超絶分かりやすい。これで分からないなら諦めた方がいいというくらいわかりやすいので超オススメ
しかし毎回思うけど、この手の話題って本当の意味での入門書みたいなのがなかなか書かれないよね。
たとえばロスってなんだとか、ReLuってなんだとか、シグモイド関数ってなんだとか、いきなり入門するとそこらへんがわからなくて普通は混乱するんじゃないかなーと思う。
僕は幸い、職場にそういうのが好きな人がちょいちょいいたので、直接話しを聞いて「なるほどねー」と疑問を氷解することができるんだけど、これ、普通のプログラマーがいきなり入門しようとするとあまりの世界観の違いに驚くんじゃないか。
こないだもドワンゴ人工知能研究所に遊びに行った時に山川所長と話をするチャンスがあって、けっこう根本的な質問をいろいろ聞けたのでラッキーだった。
たとえば悩んでたのが学習ね。
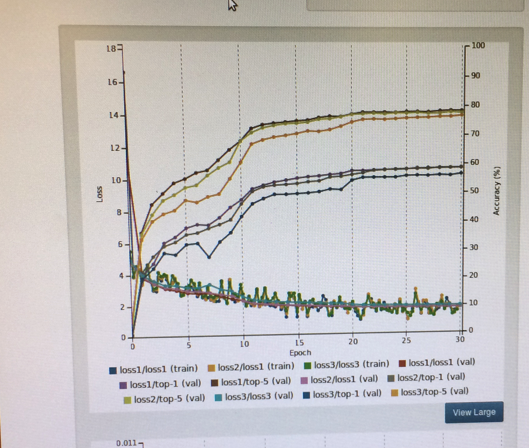
こんな感じで学習を繰り返していくと、どこかで上げ止まるところがやってくる。
上げ止まると、「なんだ、これが限界か」と思ってしまいがちで、だけどこの正答率だと巷でよく言われているような高精度なものにならない。「おかしいなー」と思っていろんな組み合わせを試していたんだけど、山川所長によると、「我慢して待つと、いきなり学習が進むブレークスルーが起きるポイントが来る」とのこと。
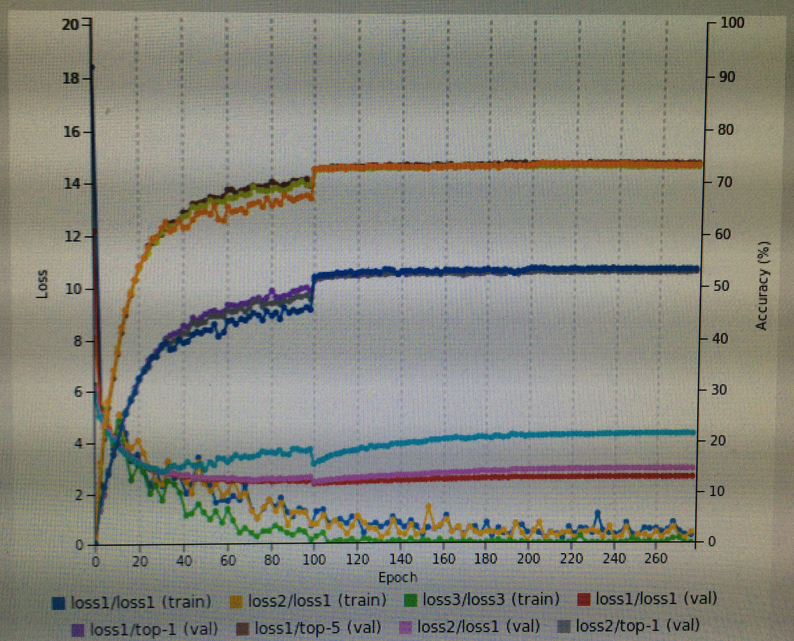
確かに我慢して待ってると、ときどきブレークスルーが起きるポイントがある。
これ、けっこう感動的。
人間と同じなんだよね。
そこらへんが感動的。
山川先生曰く「いままで仮説として唱えられてきた多層ニューラルネットワークは、仮説としては間違っていなかったんだけど、ブレークスルーが自動的に起きるまで我慢した人がいなかった」とのこと。面白すぎる。もちろんマシンパワーも昔とは段違いだからね。
ついでにいうと、学習させるためのアルゴリズムもいろいろ考案されてるんだけど、イマイチイメージがつかみにくいなーと思っていたら面白い動画を見つけた。

これは、よく使われるSGD、NAG、AdaGrad、AdaDeltaなどの学習アルゴリズムがそれぞれどのような性質を持っているかを表したアニメーション。
AdaDeltaもNAGも、最終的には最もエネルギー効率がいい場所(下)にたどり着けるんだけど、動き方とスピードが違うというわけ。SGDはこのアニメーションでは適当なところで停滞しちゃってるね。
よくCaffeの学習サンプルとして使われるbvlc(http://bvlc.eecs.berkeley.edu)の学習済みニューラルネットワークは、31万回学習ループを回したらしい。ちなみに31万回を単体のTITAN Xでやろうとすると、約3年かかる(ガビーン)。いまのところSLI使えないので、SLI対応したニューラルネットワークは自分でプログラミングするしかない。SLIで4枚差しであわよくば4倍。GoogLeNetはニューロンの数が比較的少ないのでSLIを有効に使うことが簡単にできるのかどうかがいまのところよくわからない。
ただ、似て非なる学習データセットを複数のニューラルネットワークに学習させて多数決をとるとか、もっと別の方法で効率化はできるのかもしれない。この分野はまだ僕は研究を上手く探せていない。
3万回でだいたい90日くらい。
しかもけっこう乱数の影響受けるので(そもそも学習過程に乱数使いまくる)、乱数の精度にももしかしたら秘密がありそう。昔の国防総省とかが使ってるでかいコンピュータには、乱数発生器という専用の機械があったんだけど、擬似乱数のままでいいのかそれとも乱数発生器みたいなのをつかって本格的な乱数を使うのがいいのかはまだわからない。誰か試してないのかな。でもあまりにも黒魔術的だから誰も試してないんだろうか。
本格的な乱数発生器は、セシウムのβ崩壊をガイガーカウンターで測った数値を元にするので遅い気がする。ポアソン分布にはなるけど。それだと乱数テーブルを乱数発生器で作って、それを使ってぶん回すほうが速いのかな。
と思ったら、さすがにScipyとかNumpyとかは乱数がかなり進化してるらしい。
そりゃそうか
しかし人工知能の教育には乱数が重要っていうのはなんだか考えさせられる。
この宇宙が量子力学的な確率波によってできているという話と、知能を人工的に作ろうとすると乱数が効果的という話は似てる。
するともはや、足元で唸り声を上げて高速にいろんなものを学習しまくる僕の可愛い人工知能ちゃんたちは、一種の学校のような様相を呈してくる。まさにベイビーだな。ベイビー。無垢な人工知能
「こいつにはこれを勉強させよう」「こいつにはこれ」みたいな感じで勉強させるものを分けてひたすらループをぶん回す。
あとは"彼ら"が育つのを待つというわけだ。
でも学習させたいタスクは常に増え続けているため、学習させ方を学習したりしないとまずい。
そのためには、マシンがたくさん必要だ。一つのマシンで高速に学習できることも大事だが、いろんな学習方法を並行して試すことができることも大事。
だからディープラーニングはなんか楽しいんだよね。
毎日、なんもしなくても、グラフをながめてムフフと思える。
今来てる書籍の執筆依頼はひと通りこなしちゃったので、次に依頼が来たらディープラーニングに関連した本を書こうかな。
松尾先生の本もわかりやすけど、プログラミングするならこの本かな
用語に関してもひと通り解説載ってるし
- 作者: 岡谷貴之
- 出版社/メーカー: 講談社
- 発売日: 2015/04/08
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (2件) を見る
Permalink | 23:42
- 66 http://t.co/imQ7OPjqkn
- 52 https://www.google.co.jp/
- 24 http://pipes.yahoo.com/pipes/pipe.info?_id=7ed2910a6358c42a7305fae463b19704
- 18 https://www.facebook.com/
- 7 http://www.google.co.jp/url?sa=t&rct=j&q=&esrc=s&source=web&cd=11&ved=0CBwQFjAAOAo&url=http://d.hatena.ne.jp/shi3z/20141122/1416617213&ei=-AeQVeP8LsHj8AWph4DoAQ&usg=AFQjCNEkXfBBkNsN0c4SyCUt5iyD9WqjtA&sig2=-RMZu3phIGy-VCIohzGs4g
- 4 http://m.facebook.com
- 3 http://feedly.com/i/latest
- 3 http://reader.livedoor.com/reader/
- 3 http://search.yahoo.co.jp/search?ei=UTF-8&fr=top_ipd_sa&x=wrt&p=ブレインストーミング&aq=1&oq=ぶれいん
- 3 http://t.co/oqA1jxCgO4