Dockerコンテナのパフォーマンス劣化とチューニング
はじめに
本連載の第2回『ベアメタル環境とDockerコンテナ環境の性能比較』で実施したコンテナ環境とベアメタル環境との性能比較では、コンテナ環境は高負荷時に挙動が不安定になるという結果となった。本記事には皆様からTwitterなどのソーシャルメディアを通じて、検証についてのご意見や問題点の解消方法について貴重なご指摘をいただいている。今回はこれらを参考に、発生したパフォーマンス劣化の原因の調査と改善策を模索していきたい。
まず筆者が目をつけたのは、Dockerが利用しているコピーオンライトデバイスの部分がパフォーマンス劣化の原因となっているのではないだろうか? という点である。実際にテストを実施しながら検証していきたい。
ストレージドライバとは
ストレージドライバは、物理サーバ上ではストレージ(HDD)コントローラのチップセットドライバだが、Dockerではコンテナ記憶域に使用されるコピーオンライトのファイルシステムの種類を指す用語だ。
Dockerのv1.5で利用出来るストレージドライバは、以下の5種類である。
表1:Dockerのv1.5で利用出来るストレージドライバ
| ファイルシステム | 概要・特徴 |
|---|---|
| aufs | Another UnionFS。overlavfs(unionfs)の信頼性や性能を向上させるために開発されたファイルシステム |
| btrfs | B-tree file system。Oracleが開発したコピーオンライトのファイルシステム。耐障害性や修復機能などを持つことを目的に開発されている |
| device-mapper | 仮想的なブロックデバイスを作成し、それをファイルシステムとして利用する。Linux LVMも本技術を利用し、複数の物理HDDを1つの仮想ディスクに結合している |
| overlayfs | unionfsとも呼ばれる。Linuxのunion mountの機能を利用したファイルシステムで、LiveCDなどで起動したOS上にマウントすることで書き込みも可能な状態を実現する |
| vfs | Virtual File System。通常のLinuxファイルシステムをマウントして利用する。コピーオンライトはサポートしていない。 |
OSやDockerを標準設定でインストールした場合、筆者の環境ではCentOS 6.6やCentOS 7ではdevice-mapperが選択され、一方Ubuntu 14.04ではaufsが選択された。これはDockerがインストール時に、ホストOSで利用出来るストレージドライバを検出し、適合したストレージドライバは優先順位をつけて利用される仕組みとなっているためだ。
稼働中のDockerが利用しているストレージドライバは、以下のコマンドで確認出来る。
root@centos7:~ # docker info Containers: 0 Images: 0 Storage Driver: devicemapper Pool Name: docker-253:1-33556714-pool Pool Blocksize: 65.54 kB Backing Filesystem: xfs Data file: /dev/loop0 Metadata file: /dev/loop1 Data Space Used: 0 B Data Space Total: 107.4 GB Data Space Available: 28.4 GB Metadata Space Used: 577.5 kB Metadata Space Total: 2.147 GB Metadata Space Available: 2.147 GB Udev Sync Supported: true Data loop file: /var/lib/docker/devicemapper/devicemapper/data Metadata loop file: /var/lib/docker/devicemapper/devicemapper/metadata Library Version: 1.02.93-RHEL7 (2015-01-28) Execution Driver: native-0.2 Kernel Version: 3.10.0-229.1.2.el7.x86_64 Operating System: CentOS Linux 7 (Core) CPUs: 1 Total Memory: 1.797 GiB Name: tissrv152 ID: 3NO4:WORM:B4X7:MHAT:RWFT:72LT:RIEU:M3CF:FYJB:NMLM:J4YH:KQAH
== ホスト環境準備今回の検証では「CentOS Linux release 7.1.1503」と「Docker version 1.5.0-dev」を利用する。ホストサーバのスペックは、以下の表を参考にして欲しい。
表2:ホストサーバのスペック
| CPU | Intel(R) Core(TM) i7 870 @ 2.93GHz |
|---|---|
| コア数 | 8コア |
| Memory | 4GB |
| Swap | 4GB |
| HDD1 | Western Digital 1TB(SATA3 7200rpm) |
| HDD2 | Western Digital 1TB(SATA3 7200rpm) |
| HDD3 | Western Digital 1TB(SATA3 7200rpm) |
| NIC1 | 負荷発生端末(JMeter)とのみ接続可能なクローズドなネットワーク |
| NIC2 | インターネットへ接続可能なネットワーク |
今回の検証環境は、連載第2回のものとは異なっている。変更点は以下の通りとなる。
- ベースOSをCentOS 6.6からCentOS 7.1に変更
- DockerをVer 1.4.1からVer 1.5.0に更新
変更の理由は、これから利用をしていくCentOS 7系で評価を行うべきとのご指摘に対応をしたものである。さらに2015年4月20日にepelリポジトリのDockerがVer 1.5.0に更新された。Ver 1.5.0はLinuxカーネルのVer 3.0系を推奨としており、システムの安定性も考慮し、上記の変更を行っている。
JMeterサーバは連載第2回から変更は行っていないため、説明は割愛する。
Dockerコンテナ準備
今回の検証も、連載第2回と同じくRedmine+MySQLを処理性能測定用のプロダクトとして利用する。ただし今回は、読者の方にも同じ検証が行えるように、DockerHubにsameersbn氏が公開しているRedmineコンテナ(https://github.com/sameersbn/docker-redmine/tree/2.5-stable)を利用することにした。
このコンテナは最新版ではないのだが、前回行った物理環境がApacheで動いているため、コンテナ環境でもApache上で動くRedmineコンテナを選出したい経緯がある(最新版はnginxで稼働する構成となる)。既存で公開されているDocker imageを使用しているため、最新のRedmineとMySQLを利用していない点はご容赦いただきたい。
表3:本記事で利用するコンテナ
| 利用コンテナ | バージョン |
|---|---|
| sameersbn/redmine:2.5.0 | 2.5.0 stable |
テスト項目
今回は連載第2回で行ったテストを、様々なチューニングを行ったDockerコンテナに対して実施し、性能改善の有無を検証する。ただし、テスト回数を1000回/60秒から2000回/60秒へと増やしている。これは、CentOS 6.6+Docker 1.4.1の環境上では1000回/60秒の条件で多発したエラーが、今回のCentOS 7.1+Docker 1.5.0環境では全く発生しなかったためだ。ベースOS、Dockerともにバージョンアップが行われたことで、大幅に性能が改善していると考えられる。ただ、2000回/60秒に増やしたところ、やはりベアメタル環境では発生しなかったレスポンス悪化とエラーが再発するようになったため、負荷を上げる形で検証を行うこととした。
JMeter上から実行したオペレーションは以下となる。
1.参照オペレーション
- Redmineのログイン画面へアクセス
- ユーザ名とパスワードを用いてRedmineにログイン
本オペレーションでは、原則、DBやディスクには参照の処理が行われる。CPU、ネットワーク、ディスクに平均的に負荷を発生させることを目的としている。
2.更新オペレーション
- Redmineのプロジェクトに対して新しいチケットを1件作成
- 表題と内容を記載し登録
本オペレーションでは、チケットの登録が行われるため、ディスクの更新が発生する。データ量は小さいがDB、ディスクへの負荷を発生させることを目的としている。
JMeter上から発生させる負荷量は以下となる。
高負荷
- 参照、更新のオペレーションを2000件/60秒の間隔で実行する
- テスト時間は60秒間で行い、それを3回繰り返して平均を取得する
- 負荷のスコアはJMeter上のスコアを利用する。
テスト1:基準となるデータの測定
前回の検証で利用したコンテナはRedmineとMySQLがそれぞれのコンテナに分離していたが、今回のコンテナは1個のコンテナにRedmineとMySQLが統合さている。まず性能評価の基準を作成するために、ダウンロードしたコンテナイメージを変更することなく性能測定を実施する。コンテナが統合されていることにより、コンテナ化のネットワークの負荷が小さくなる点で差異が発生する可能性が考えられる。そのため後述でコンテナを分離し、ネットワークを介したテストも実施するのでご安心いただきたい。
まずはコンテナを立ち上げる。
[root@host_server ~]# docker run --name=redmine -p 8080:80 -d sameersbn/redmine:2.5.0
ここでは、コンテナ内に対してはチューニング等の変更は加えていない。テスト開始の準備として、Redmineが立ち上がりWebブラウザでアクセス出来るようになったら、デフォルト設定をロードし、テストするためのプロジェクトを一つ作成する。
表4:テスト1の結果
| 作業 | 1分間のオペレーション | 平均(ミリ秒) | 中央値(ミリ秒) | 90%Line(ミリ秒) | 最小値(ミリ秒) | 最大値(ミリ秒) | Error% | スループット | KB/sec |
|---|---|---|---|---|---|---|---|---|---|
| アクセス | 2000 | 15490 | 6258 | 62024 | 11 | 118298 | 10.00 | 14.4 | 63.5 |
| ログイン実行 | 2000 | 1731 | 1381 | 3676 | 8 | 12528 | 10.00 | 14.4 | 85.2 |
| Projectへ遷移 | 2000 | 15321 | 7070 | 37539 | 21 | 106873 | 8.62 | 13.9 | 72.4 |
| チケット作成 | 2000 | 1655 | 1308 | 3578 | 9 | 13001 | 8.62 | 13.9 | 71.3 |
| 平均 | 2000 | 8549.25 | 4004.25 | 26704.25 | 12.25 | 62675 | 9.31 | 14.15 | 73.1 |
テスト中に取得できたiostatの最大値を以下に示す。この値は、テスト中iostatコマンドを用いて3秒おきに出力されるIOデータのWriteに注目し、最大値を抽出したものだ。この後のテストでも、同様のデータ抽出方法を採用している。
テスト1で取得できたiostatの最大値
avg-cpu: %user %nice %system %iowait %steal %idle
43.82 0.00 5.27 7.56 0.00 43.35
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.33 1.67 3.00 140.67 102.67 3229.83 46.39 1.04 7.22 10.33 7.15 5.77 82.97
dm-1 0.00 0.00 3.33 110.67 102.67 3229.50 58.46 1.05 9.25 13.10 9.13 7.27 82.87
dm-2 0.00 0.00 1.67 276.33 26.67 3328.00 24.13 1.12 4.03 19.40 3.93 2.81 78.23
dm-3 0.00 0.00 1.33 264.33 5.33 3340.00 25.18 1.25 4.70 9.25 4.67 3.16 83.83
テスト1の結果を見ると、平均の待ち時間(90%Line)が約26秒とかなり遅く、エラー率も10%近い値を出している。またテストを行っている時のDiskIOをウォッチしていると、書き込みの最大値が3229kB/sとなっており、こちらも若干遅いように見える。
ログやコンテナ内のApacheの設定から察するに、「アクセス」の作業で投げられたHTTPリクエストが、ApacheのMaxClientsである150件を超え、60秒でタイムアウトしている様子だ。そのため何度検証を行っても待ち時間(90%Line)が60000ミリ秒を大きく超えることはなかった。この値を本記事の基準とし、次のテストから性能の改善を試みる。
テスト2:Dockerの仮想Disk領域を別の物理ディスクに置き換える
前回の記事に対して、読者の方から「Dockerコンテナが更新する仮想Diskが利用するスパースファイルの領域を、ディスク領域に変更するとディスクアクセス速度が改善される」との情報をいただいたので、早速試してみたい。具体的には、Dockerコンテナの更新データを格納するスパースファイルの代わりに、専用の物理ハードディスクを割り当てることで性能が改善されるかを検証する。
今回のテスト環境の構築では、仮想Disk領域の変更を行うが、その際にはDocker環境のファイルシステムを再構成する必要がある。実際にはDockerのサービスを停止した状態で/var/lib/docker以下のファイルを全て削除し、コンテナイメージを全て削除することとなる。実際に行う時は必要なデータをバックアップしたのち、クリーンアップした状態で環境の構築を実施するよう注意して欲しい。手順を以下に示す。
- 現在のDisk構成を確認
[root@host_server ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 931.5G 0 disk ├─sda1 8:1 0 500M 0 part /boot └─sda2 8:2 0 931G 0 part ├─centos-swap 253:0 0 3.9G 0 lvm [SWAP] └─centos-root 253:1 0 927.1G 0 lvm / sr0 11:0 1 1024M 0 rom loop0 7:0 0 100G 0 loop └─docker-253:1-1287-pool 253:2 0 100G 0 dm └─docker-253:1-1287-base 253:3 0 10G 0 dm loop1 7:1 0 2G 0 loop └─docker-253:1-1287-pool 253:2 0 100G 0 dm └─docker-253:1-1287-base 253:3 0 10G 0 dm
LoopbackデバイスにDockerのDataspaceが存在していることがわかる。 - 空のディスクを追加(/dev/sdb、/dev/sdc)
- fdiskコマンドでパーティションを作成する(/dev/sdb1に990GB、/dev/sdb2に10GBとした)
- Docker上の必要となるコンテナやイメージは全てexportする
- Dockerサービスを停止する(systemctl stop docker)
- Dockerのコンテナやイメージが格納されている/var/lib/docker/以下を全部削除する(rm –rf /var/lib/docker/*)
- /etc/sysconfig/docker-storageファイルのDOCKER_STORAGE_OPTIONSに作成したパーティションを割り当てる
DOCKER_STORAGE_OPTIONS="--storage-opt dm.datadev=/dev/sdb1 --storage-opt dm.metadatadev=/dev/sdb2"
- Dockerを起動(systemctl start docker)
- ディスク割り当て後のDisk構成を確認
[root@host_server ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 931.5G 0 disk ├─sda1 8:1 0 500M 0 part /boot └─sda2 8:2 0 931G 0 part ├─centos-swap 253:0 0 3.9G 0 lvm [SWAP] └─centos-root 253:1 0 927.1G 0 lvm / sdb 8:16 0 931.5G 0 disk ├─sdb1 8:17 0 920G 0 part │ └─docker-253:1-3221831217-pool 253:2 0 920G 0 dm │ └─docker-253:1-3221831217-base 253:3 0 10G 0 dm └─sdb2 8:18 0 11.5G 0 part └─docker-253:1-3221831217-pool 253:2 0 920G 0 dm └─docker-253:1-3221831217-base 253:3 0 10G 0 dm sdc 8:32 0 931.5G 0 disk sr0 11:0 1 1024M 0 romこれでスパースファイルをloopbackデバイスでマウントする状態が解消され、物理デバイスが割り当てられた状態となった。
ここからは余談となるが、筆者の環境(CentOS 7.1 + Docker 1.5.0)で物理デバイスを割り当てる際に問題が発生した、他の環境でも同様の事象が発生することも考えられる為、情報を共有しておきたい。
Dockerのmetadata領域に1TBのDiskを割り当てようとするとエラーが発生する
先に紹介した手順では、/dev/sdbの領域に990GBと10GBの領域を割り当ててDockerを起動している。当初の予定では/dev/sdbをdataに、/dev/sdcをmetadata領域に割り当てようとしていたが、その際に今回のエラーに直面した。ここでは既存のDockerのサービスは停止しており、データも存在していないものとする。
/dev/sdbをdataに、/dev/sdcをmetadataとして割り当てDockerを起動すると、以下のようなエラーとなる。
[root@host_server ~]# docker -d --storage-opt dm.datadev=/dev/sdb --storage-opt dm.metadatadev=/dev/sdc INFO[0000] +job serveapi(unix:///var/run/docker.sock) INFO[0000] Listening for HTTP on unix (/var/run/docker.sock) FATA[0000] Error running DeviceCreate (CreatePool) dm_task_run failed
/var/log/messagesには、割り当てたDiskのセクタが多すぎる旨のログが出力されていた。
kernel: device-mapper: thin: Metadata device sdc is larger than 33292800 sectors: excess space will not be used.
Dockerのmetadata領域に、Diskの先頭セクタを利用したパーティションを割り当てようとするとエラーとなる
割り当てられるセクタに上限があることが上の事象からわかったので、次に最大割り当て可能セクタ以下の領域をmetadataに割り当てることにした。具体的には/dev/sdcにパーティションを作成し、先頭セクタから10GB分を/dev/sdc1(metadata用)に、残りの領域を/dev/sdc2(data用)に割り当て、Dockerを起動する。
[root@host_server ~]# lsblk /dev/sdc NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sdc 8:32 0 931.5G 0 disk ├─sdc1 8:33 0 10G 0 part └─sdc2 8:34 0 921.5G 0 part
そうすると、以下のエラーとなった。
[root@host_server ~]# docker -d --storage-opt dm.metadatadev=/dev/sdc1 --storage-opt dm.datadev=/dev/sdc2 INFO[0000] +job serveapi(unix:///var/run/docker.sock) INFO[0000] Listening for HTTP on unix (/var/run/docker.sock) FATA[0000] Error running DeviceCreate (CreatePool) dm_task_run failed
この際、/var/log/messagesには以下のログが出力されていた。
kernel: device-mapper: block manager: superblock validator check failed for block 0 kernel: device-mapper: thin metadata: couldn't read superblock kernel: device-mapper: table: 253:2: thin-pool: Error creating metadata object kernel: device-mapper: ioctl: error adding target to table
ログの内容からは、スーパーブロックのバリデートチェックが失敗してmetadataオブジェクトの作成に失敗しているように見える。対処法としては、実際の手順として前述したようにmetadataに割り当てる領域を「Diskの終端を含みつつ環境の最大割り当て可能セクタ以下のパーティション」とすることで、エラーを回避できることが判明した。
前述の問題を解消し、ディスクが割り当てられた状態でテスト1のコンテナ構成を用意してテストを実施すると、表5の結果が得られた。
表5:テスト2の結果
| 作業 | 1分間のオペレーション | 平均(ミリ秒) | 中央値(ミリ秒) | 90%Line(ミリ秒) | 最小値(ミリ秒) | 最大値(ミリ秒) | Error% | スループット | KB/sec |
|---|---|---|---|---|---|---|---|---|---|
| アクセス | 2000 | 9474 | 3346 | 32695 | 13 | 112310 | 5.67 | 18.3 | 82.9 |
| ログイン実行 | 2000 | 1590 | 1260 | 3300 | 8 | 9923 | 5.67 | 18.3 | 110.2 |
| Projectへ遷移 | 2000 | 10109 | 4138 | 33039 | 22 | 112338 | 5.65 | 18.3 | 97.6 |
| チケット作成 | 2000 | 1507 | 1179 | 3176 | 11 | 10041 | 5.65 | 18.3 | 95.0 |
| 平均 | 2000 | 5670 | 2480.75 | 18052.5 | 13.5 | 61153 | 5.66 | 18.3 | 96.43 |
テスト2で取得できたiostatの最大値
avg-cpu: %user %nice %system %iowait %steal %idle
46.43 0.00 5.65 9.43 0.00 38.49
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sdb 0.00 277.33 2.33 127.00 9.33 5364.00 83.09 1.62 12.54 7.29 12.64 5.88 76.07
dm-2 0.00 0.00 2.33 391.67 9.33 5305.33 26.98 4.29 10.94 7.29 10.96 1.72 67.77
dm-4 0.00 0.00 2.33 392.00 9.33 5508.00 27.98 4.47 11.38 7.29 11.41 1.94 76.33
テスト1に比べ待ち時間(90%Line)とエラー率のパフォーマンスが50%程度改善されていることが見て取れる。Writeの流量も増えており、こちらも良い傾向である。しかし全体で見るとまだ待ち時間が多く、少ないながらエラーも発生していることから改善の余地があると考える。
テスト3:コンテナで利用する一部のファイルをホストOSへ切り出す
本テストはコンテナ内の一部のファイルをホストOS側で管理する仕組みを試してみる。本項で行った環境への変更は全て戻し、テスト1の最初の時点の環境へとロールバックを行っている。
Dockerを利用する上で、Dockerが利用する各ファイルシステムが差分更新となっているため、パフォーマンスが気になるという声があった。今回のテストは、差分更新のファイルシステムを回避することが可能かの検証を考えている。
Dockerの機能として、外部デバイスや領域をコンテナからマウントして利用する機能が提供されている。
その機能を活用し、DiskIOが多いと考えられるRedmineのデータ部分やMySQLのDBのファイルシステム部分をベースOS側に配置してみる。
ホスト側で保存する領域(ディレクトリ)を作成
Redmineのファイル保存領域、およびMySQLのDBファイルの保存場所を作成する。
[root@host_server ~]# mkdir -pv /opt/redmine/files [root@host_server ~]# mkdir /opt/redmine/mysql
コンテナ起動
Redmineコンテナを起動する。一部のファイルをホスト側に保存し利用するため、「-v」オプションを使って先の手順で作成した保存領域を指定する。テスト1と同条件で行ったテストの結果を表6に示す。
[root@host_server ~]# docker run --name=redmine -p 8080:80 -d -v /opt/redmine/files:/redmine/files -v /opt/redmine/mysql:/var/lib/mysql sameersbn/redmine:2.5.0
表6:テスト3の結果
| 作業 | 1分間のオペレーション | 平均(ミリ秒) | 中央値(ミリ秒) | 90%Line(ミリ秒) | 最小値(ミリ秒) | 最大値(ミリ秒) | Error% | スループット | KB/sec |
|---|---|---|---|---|---|---|---|---|---|
| アクセス | 2000 | 53 | 21 | 110 | 10 | 1025 | 0.00 | 10.8 | 50.4 |
| ログイン実行 | 2000 | 112 | 88 | 203 | 38 | 959 | 0.00 | 10.8 | 66.2 |
| Projectへ遷移 | 2000 | 79 | 36 | 169 | 18 | 952 | 0.00 | 10.7 | 59.3 |
| チケット作成 | 2000 | 70 | 41 | 14418 | 1064 | 0.00 | 10.7 | 56.4 | |
| 平均 | 2000 | 78.5 | 46.5 | 156.5 | 21 | 1000 | 0.0 | 10.75 | 58.08 |
テスト3で取得できたiostatの最大値
avg-cpu: %user %nice %system %iowait %steal %idle
51.89 0.04 2.82 2.56 0.00 42.69
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 3.33 0.00 110.67 0.00 4377.50 79.11 1.51 13.67 0.00 13.67 6.62 73.27
dm-1 0.00 0.00 0.00 86.67 0.00 4377.50 101.02 1.66 19.18 0.00 19.18 8.45 73.20
dm-2 0.00 0.00 0.67 12.33 42.67 332.00 57.64 0.08 6.26 0.00 6.59 6.26 8.13
dm-3 0.00 0.00 0.00 18.00 0.00 710.67 78.96 0.12 6.89 0.00 6.89 6.89 12.40
全てのファイルをコンテナに配置していたテスト1と比べて、大幅にパフォーマンスが上がっているのがわかる。平均待ち時間が0.15秒となり、HTTPリクエストエラーも検出されなくなった。さらに若干ではあるが、DiskIOのWriteの値が増えている。これはIOWaitの時間が短くなり、より多くの書き込みが出来るようになったということだろう。
特定のファイルをホストOS内のストレージ領域へ保持させる「-v」オプションを利用した手法は、コンテナのパフォーマンス向上が見込める便利なオプションではあるが、Dockerのメリットでもあるポータビリティが犠牲になる側面を持つ。
通常の利用であれば、コンテナ内で設定や情報が完結しているので、コンテナを起動するホスト端末が変更された場合にもコンテナを移動すれば、今までの環境を再現できる。だが今回のように情報をコンテナ外に出すことによって、コンテナを移設するためには、新たなホスト端末へ同様のパスを作成し、切り出した情報を配置し、コンテナをオプション付きで起動する必要が生じる。
一方でこの方法を利用すれば、誤ってコンテナを削除してしまった場合にもデータの喪失はない。外部ストレージなどを活用すれば堅牢性の確保にも有用だが、コンテナのポータビリティという観点では運用が難しくなり、コンテナの数が増えていくと運用ミスの温床になることが懸念される。
テスト4:コンテナをRedmineとMySQLの2つに分離してみる
今回利用しているコンテナは、一つのコンテナに対してRedmineやMySQLといったサービスが複数入っている状態で稼働している。メンテナンス性を考えると、コンテナは分離したほうが良いというのがDockerコンテナを利用する上での一般的な考え方となっている。
コンテナを分離した場合、コンテナ間はDockerの仮想ネットワークで通信が行われるため、ネットワーク通信によるオーバーヘッドが発生するのでは? と考えた。今回の検証ではコンテナを2つに分離し、パフォーマンスの観点からどのような相違が発生するかを検証する。
コンテナの分離手順
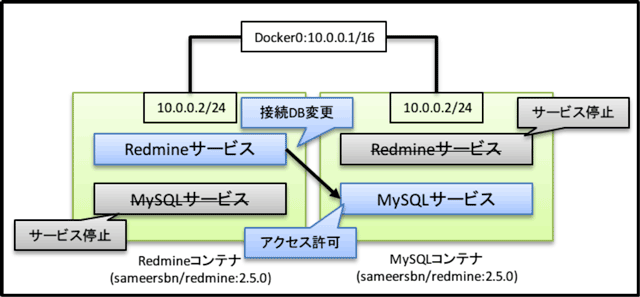
図1:MySQLとRedmineを別のコンテナに分離する
コンテナの分離は、上図のように行った。コンテナは先のテストと同様に「sameersbn/redmine:2.5.0」を利用しており、同じコンテナを別の名前をつけてポートフォワードするコンテナ(Redmine用)とポートフォワードしないコンテナ(MySQL用)を起動する。
[root@host_server ~]# docker run --name=redmine -p 8080:80 -d sameersbn/redmine:2.5.0 [root@host_server ~]# docker run --name=mysql -d sameersbn/redmine:2.5.0
この状態では2つのコンテナともRedmine+MySQLの構成で動いているので、それぞれ片方のサービスを停止した後、DBに対して外部からのアクセス許可を加えRedmineの接続DBの向き先を変更した。
この構成でテストを行い、得られた結果を表7に示す。
表7:テスト4の結果
| 作業 | 1分間のオペレーション | 平均(ミリ秒) | 中央値(ミリ秒) | 90%Line(ミリ秒) | 最小値(ミリ秒) | 最大値(ミリ秒) | Error% | スループット | KB/sec |
|---|---|---|---|---|---|---|---|---|---|
| アクセス | 2000 | 24892 | 12424 | 63000 | 17 | 110880 | 21.68 | 11.1 | 45.4 |
| ログイン実行 | 2000 | 2245 | 1833 | 4712 | 9 | 19814 | 21.68 | 11.1 | 62.7 |
| Projectへ遷移 | 2000 | 24629 | 12890 | 63000 | 84 | 110882 | 20.05 | 11.1 | 53.3 |
| チケット作成 | 2000 | 2118 | 1713 | 4461 | 10 | 18078 | 20.05 | 11.1 | 55.3 |
| 平均 | 2000 | 13471 | 7215 | 33793.25 | 30 | 64913.5 | 20.87 | 11.1 | 54.18 |
テスト4で取得できたiostatの最大値
avg-cpu: %user %nice %system %iowait %steal %idle
23.42 0.00 3.17 13.57 0.00 59.83
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 3.33 0.33 86.00 16.00 3096.33 72.10 1.37 15.92 14.00 15.93 11.32 97.77
dm-1 0.00 0.00 0.33 75.67 16.00 3095.83 81.89 1.39 18.25 14.00 18.26 12.86 97.77
dm-2 0.00 0.00 0.67 94.33 2.67 3076.00 64.81 3.95 41.39 7.00 41.63 9.11 86.57
dm-4 0.00 0.00 0.00 19.33 0.00 1021.33 105.66 1.20 62.28 0.00 62.28 9.83 19.00
dm-5 0.00 0.00 0.67 74.33 2.67 2430.67 64.89 3.08 40.85 7.00 41.16 13.13 98.47
使用しているコンテナ自体はテスト1と同じだが、コンテナを2つに分離した場合にはパフォーマンスが劣化するという結果が得られた。ネットワーク起因によるレスポンス悪化を想定していたが、それに加えて、DiskIOの劣化が顕著であった。iostatの結果を見てもw/sの発行回数が少なく、ディスクビジー状態が平均して高いわりに書き込み流量が少ない結果となった。エラー発生率も1個のコンテナで動作させた場合の2~2.5倍程度になり、性能面だけから見ると、密接に関係している複数のサービスは1つのコンテナに集約した方が良いことがわかる。
テスト5:Apacheのチューニングを実施する
これまでにDockerコンテナの実行環境や構成に対して様々な対策を施し、レスポンスの改善や問題点を確認してきたが、新たなアプローチとしてコンテナ内のアプリケーションの設定によるチューニングによる性能改善を検証する。ここでは、Redmineを稼働させる為に使用しているApacheおよびRuby on RailsアプリケーションをApacheと連携させるPhusion Passengerのチューニングに着目してみる。
コンテナ自体はテスト1と共通である。チューニングはRedmineコンテナに接続し、コマンドラインから直接設定を変更した。変更点は、プロセスの並行処理可能数の向上を目的として、Apacheの最大子プロセス数の上限とPassengerの最大プロセス数の上限の増加である。
| 設定項目 | 変更前 | 変更後 |
|---|---|---|
| MaxSpareServers(mpm_prefork_module) | 10 | 25 |
| MaxClients(mpm_prefork_module) | 150 | 200 |
| PassengerMaxPoolSize | 6 | 15 |
この状態で再度負荷テストを行う。結果を表9に示した。
表9:テスト5の結果
| 作業 | 1分間のオペレーション | 平均(ミリ秒) | 中央値(ミリ秒) | 90%Line(ミリ秒) | 最小値(ミリ秒) | 最大値(ミリ秒) | Error% | スループット | KB/sec |
|---|---|---|---|---|---|---|---|---|---|
| アクセス | 2000 | 137 | 22 | 279 | 10 | 2945 | 0.00 | 28.6 | 133.9 |
| ログイン実行 | 2000 | 327 | 235 | 610 | 58 | 3209 | 0.00 | 28.6 | 175.8 |
| Projectへ遷移 | 2000 | 200 | 39 | 431 | 17 | 4222 | 0.00 | 28.3 | 156.5 |
| チケット作成 | 2000 | 138 | 42 | 310 | 19 | 3713 | 0.00 | 28.4 | 149.5 |
| 平均 | 2000 | 200.5 | 84.5 | 407.5 | 26 | 3522.25 | 0.0 | 28.48 | 153.93 |
テスト5で取得できたiostatの最大値
avg-cpu: %user %nice %system %iowait %steal %idle
23.42 0.00 3.17 13.57 0.00 59.83
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 3.33 0.33 86.00 16.00 3096.33 72.10 1.37 15.92 14.00 15.93 11.32 97.77
dm-1 0.00 0.00 0.33 75.67 16.00 3095.83 81.89 1.39 18.25 14.00 18.26 12.86 97.77
dm-2 0.00 0.00 0.67 94.33 2.67 3076.00 64.81 3.95 41.39 7.00 41.63 9.11 86.57
dm-4 0.00 0.00 0.00 19.33 0.00 1021.33 105.66 1.20 62.28 0.00 62.28 9.83 19.00
dm-5 0.00 0.00 0.67 74.33 2.67 2430.67 64.89 3.08 40.85 7.00 41.16 13.13 98.47
エラー割合は0%となり、「90%Line」の値も大幅に改善されている。Docker環境自体が変更出来ない場合でもプロダクト側の設定をチューニングすることで、パフォーマンスの改善が図れることがわかった。
ただしプロセスを増やした場合、必然的にこれまでテストを実施してきたコンテナと比べてホスト側のCPUやメモリリソース等をより多く消費してしまうこととなる。リソース量に上限を設けたければ、docker runコマンドの「-c」や「-m」オプションが有効だ。
まとめ
テスト中に得られた値と比較するため、Dockerコンテナのディスクイメージ格納用の領域として使用したハードディスクそのものの性能を測定してみた。
[root@host_server~]# dd if=/dev/zero of=/dev/sda bs=1MB count=1024 1024+0 records in 1024+0 records out 1024000000 bytes (1.0 GB) copied, 3.90083 s, 263 MB/s
ddコマンドによる単純なシーケンシャルwriteだが、1GBのファイルを一つ作成するにあたって263MB/secの書き込み速度が出ている。実際にテスト1中に取得したiostatの結果と比べて見よう。
avg-cpu: %user %nice %system %iowait %steal %idle
43.82 0.00 5.27 7.56 0.00 43.35
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.33 1.67 3.00 140.67 102.67 3229.83 46.39 1.04 7.22 10.33 7.15 5.77 82.97
dm-1 0.00 0.00 3.33 110.67 102.67 3229.50 58.46 1.05 9.25 13.10 9.13 7.27 82.87
dm-2 0.00 0.00 1.67 276.33 26.67 3328.00 24.13 1.12 4.03 19.40 3.93 2.81 78.23
dm-3 0.00 0.00 1.33 264.33 5.33 3340.00 25.18 1.25 4.70 9.25 4.67 3.16 83.83
取得した値を見るとディスクの使用率(%util)は非常に高いが、一方で書き込みデータ量(wkB/s)はディスク自体の性能から見ると少ないことがわかる。つまり、ハードディスクの物理的な性能不足ではなく、データ量に比べてI/Oリクエストの処理件数が非常に多いことにより、処理性能の劣化が発生していると推察される。
これまでの性能対策の結果のまとめとして、Redmineに対する処理性能の評価を行った「90%Line」「Error%」「KB/sec」を各テストの平均値を比較したい。
| 90%Line(ミリ秒) | Error% | KB/sec | |
|---|---|---|---|
| テスト0:ベアメタル環境 | 74 | 0.00% | 94.75 |
| テスト1:Redmineコンテナ立ち上げてテストを行う | 26704 | 9.31% | 73.1 |
| テスト2:DockerのData Spaceを別の物理ディスクに置き換え、テストを行う | 18052 | 5.66% | 96.43 |
| テスト3: コンテナで利用する一部のファイルをホストOSへ切り出してテストを行う | 156 | 0.00% | 58.08 |
| テスト4:コンテナをRedmineとMySQLの2つに分離してテストを行う | 33793 | 20.87% | 54.18 |
| テスト5:Apacheのチューニングを実施し、テストを行う | 407 | 0.00% | 153.93 |
まず、レスポンスタイムの平均値である90%Lineの数値を確認する。
テスト4のコンテナをRedmineとMySQLの2つに分離してテストを行ったケースが一番低いスコアとなっている。今回のケースではDiskの性能が十分に出ていないところにコンテナを分割で配置し、コンテナ間通信のネットワーク負荷も発生させたことで、さらにレスポンスが悪化した形になっている。
テスト2のDockerのファイルシステムに物理デバイスを割り当てる方式だが、Dockerが標準で利用するLoopbackデバイスにdevicemapperとしてファイルシステムをマウントする方式に比べて、30%以上の改善が見られる。ファイルによる仮想ディスクと比較して、大幅に性能が改善されていると考えられる。
テスト3では、比較的IOの高いファイルをホストOS側へ配置することによって、Dockerのファイルシステム(devicemapper)の影響を受けていない。iostatの結果からもわかるように、他のテスト結果に比べて秒間Write回数が多いのにも関わらず、Diskビジーの割合が低くベアメタル環境に近いレスポンスタイムとなっている。
次にリクエストがエラーとなったError%を確認する。
コンテナを分離したテスト4のケースが、一番高いエラー率を示した。レスポンスタイムの悪化からタイムアウトなどのエラーが多発したことが原因だと考えられる。テストケース2は、90%Lineからもレスポンスタイムの改善が見受けられ、その改善によりエラー発生率が約半減している。テスト3、テスト5は、ともにベアメタルと比較するとレスポンスタイムの若干の劣化はあるものの、エラー発生率は0%となっており、Docker環境においても環境やプロダクトのチューニングにより、ベアメタルと同等の性能を確保できることがわかる。
今回の検証を終えて得られた筆者の結論は、以下のようになる。
『Dockerコンテナは、設定やチューニング次第で十分処理性能を確保できる』
Dockerコンテナのパフォーマンスを引き出す上でボトルネックとなるのは、予測していたDiskIO速度の低下であった。さらにコンテナ間の通信速度も、性能劣化の一因となることも判明した。DiskIOに対しては『Dockerコンテナ用ファイルシステムを個別ストレージにする』方法や『DiskIOが多い領域を外部ファイルシステムに配置する』方式が有効である。
さらにDiskIOがボトルネックになる可能性があることを考慮し、コンテナ内のプロダクトのチューニングを行うのも非常に有効だ。コンテナ間通信のネットワーク負荷による性能劣化に関しては、必要な機能を一つのコンテナにまとめることで解消が可能である。
ただ、いずれの方式もDockerの標準インストール状態からは乖離するため、利用できるハードウェア環境や実行するプロダクトに応じて、環境構築を行う必要がある。またこれ以外にも、Docker専用に開発され、性能対策が施されているRed Hat Enterprise Linux 7 Atomic Hostなどの製品の利用も一つの選択肢である。
現在盛んに利用されているサーバ仮想化環境やパブリッククラウドも、発表された当初はビジネスシーンで使うには性能が不足で、信頼性に対してリスクが高いと考えられていた。しかし昨今のクラウドの性能や信頼性の向上で、クラウドの利用は非常に盛んとなっており、全てのシステムをクラウドに移行した、又は移行を決定した企業も多く出てきている。
そしてDockerも、これらの技術と同様の進化が起きるだろう。現状では様々な課題があるDockerだが、今後は利用が拡大し、性能や信頼性のさらなる向上が期待される。今後もDockerと周辺技術の利用を続け、より良い利用方法や安定稼働させる環境づくりなど様々な形でトライして行きたい。
この記事の著者
佐藤 司
インフラ基盤の設計・構築・運用までの全ての工程を担当。最近は、OSS製品を活用したインフラ基盤の提供を行っている。利用するOSS製品の調査・研究も行っており、現在は、DockerとTerraformに注目している。
>株式会社アーベルソフト
森元 敏雄
デザイン指向クラウドオーケストレーションソフトウェア「CloudConductor(http://cloudconductor.org/)」の開発およびクラウド関連技術の調査・検証に従事。社内向けの大規模プライベートクラウド開発環境の設計・構築・運用の経験を生かし、CloudConductor関連製品の技術調査・検証を担当。
> TIS株式会社