SQ3.4-レビューの技法
2013年11月29日
自らの心の闇に直面させられる恐ろしいレビューのテキストが登場・・・!
カテゴリ: SQ3.4-レビューの技法
これまで、設計レビューに関する書籍の定番と言えば、Kerl E. Wiegers氏の『ピアレビュー』でした。そこに今年、新たな定番が加わりました。しかも、日本語で。
それが、静岡大学・森崎修司先生の『間違いだらけの設計レビュー』、通称「コーヒー本」[要出典]です。もともと『日経SYSTEMS』での連載をベースにしたものであり、かねてから書籍化を願っていただけに、とても嬉しい。
コーヒー本と、『ピアレビュー』
さて、この二冊とも、対象としているのは「ピアレビュー」です。
コーヒー本によると、ピアレビューとは「ドキュメントなどに含まれる問題の検出・指摘および関係者間の意識合わせを行う」ものであり、これがさらに、「ウォークスルー」「テクニカルレビュー」「インスペクション」の三つに分類されます。後のものほどフォーマル。
コーヒー本によると、ピアレビューとは「ドキュメントなどに含まれる問題の検出・指摘および関係者間の意識合わせを行う」ものであり、これがさらに、「ウォークスルー」「テクニカルレビュー」「インスペクション」の三つに分類されます。後のものほどフォーマル。
『ピアレビュー』がフォーマル・インスペクションを主な対象としているのに対し、コーヒー本は、よりカジュアルなテクニカルレビューを中心に解説しています。このこともあってかこの二冊は、きれいに棲み分けているように思います。
『ピアレビュー』は、比較的、ドライです。着眼点はたとえば、レビューに関するメトリクス、ROI、組織への導入、テンプレートなど、「管理者っぽい」印象を受けます。
一方コーヒー本は、ウェットです。着眼点はまず何より、「マインド」。レビューがある意味で危険なコミュニケーションであることに常に念頭において、注意を促します。また、レビューの実際の進行を事細かに説明しており、「現場っぽい」印象です。
一方コーヒー本は、ウェットです。着眼点はまず何より、「マインド」。レビューがある意味で危険なコミュニケーションであることに常に念頭において、注意を促します。また、レビューの実際の進行を事細かに説明しており、「現場っぽい」印象です。
わたしがコーヒー本の重要なポイントと思ったのは、次の三つです。
|
三つと書きましたが、二つでした。
レビューの終わりの考え方
レビューは、何をもって終わるのでしょう。
作成者が一方的に説明して、質疑応答して終わりでしょうか。それとも、目標とする「指摘件数」を決めて、それを達成すれば終わりなのでしょうか。
作成者が一方的に説明して、質疑応答して終わりでしょうか。それとも、目標とする「指摘件数」を決めて、それを達成すれば終わりなのでしょうか。
わたしは特にこの、「レビュー欠陥密度」みたいな考え方があまり好きではありません。テストでの「バグ密度」にも賛否両論ありますが、レビューの欠陥密度はそれに輪をかけて、分母(欠陥数?)も分子(ページ数?)も曖昧だと思っています。
もちろんこういったメトリクスでうまくやっている組織があるとは聞いています、レビュー祭りとかで。
コーヒー本では、上述のようなメトリクスについての言及はほとんどありません(つまり、否定しているわけでもない)。
ではそういう数字なしに、じゃあどうやって「終わる」ことができるのか。そこで、「シナリオ」です。
ではそういう数字なしに、じゃあどうやって「終わる」ことができるのか。そこで、「シナリオ」です。
シナリオとは
コーヒー本では、レビューのリーダーが事前に、ドキュメントに対するチェック観点となる「シナリオ」を作成することを推奨しています。そしてそのシナリオのうち、レビューで見逃した場合に後々ひどい目にあう、ハイリスクな欠陥を対象とするシナリオから順に片付けていくという方法を提案しています。
もちろん、すぐに気になってくることがあります。
「シナリオの対象にならない欠陥はどうするんだ・・・」
「シナリオの対象にならない欠陥はどうするんだ・・・」
ここが発想の転換点なのだと思います。
明確な観点もなく、対象のドキュメントをひと通り読んで、いろんな種類の欠陥を浅く広く見つけられれば、確かにレビューした気になれる。だけどそのコスト効果って本当に高いのか、ということですね。
リスクの高い欠陥はとにかく取り除く、あとの軽微なものは見限る!この決意ができるかがポイントになりそうです。
明確な観点もなく、対象のドキュメントをひと通り読んで、いろんな種類の欠陥を浅く広く見つけられれば、確かにレビューした気になれる。だけどそのコスト効果って本当に高いのか、ということですね。
リスクの高い欠陥はとにかく取り除く、あとの軽微なものは見限る!この決意ができるかがポイントになりそうです。
課題もありそう
そもそも、適切なシナリオを立てられる人間がいるのか、シナリオ自体のレビューはどうするのか、といった問題もあると思います。
また、「リスクの高いシナリオは確認した」という表現は、エライ人にものすごく共感されない気がします。「いや全シナリオやれよ」と。
また、エライ人が突然開眼して、「そうだ、このシナリオを、組織横断で全プロジェクトに適用すればいいじゃないか!よーし、みんなチェックリスト化しろ〜」ってなって、無間チェックリスト地獄の釜が開くことも、容易に想像できますよね。
また、「リスクの高いシナリオは確認した」という表現は、エライ人にものすごく共感されない気がします。「いや全シナリオやれよ」と。
また、エライ人が突然開眼して、「そうだ、このシナリオを、組織横断で全プロジェクトに適用すればいいじゃないか!よーし、みんなチェックリスト化しろ〜」ってなって、無間チェックリスト地獄の釜が開くことも、容易に想像できますよね。
シナリオの考え方は素晴らしく、ぜひ自分でもやってみたいです。でもものすごくパワーがいると思います。シナリオの有効性を理解したうえで、それをいかに現場に浸透させ、かつ形骸化を防ぐかという問題が立ちはだかりそうですよね。
マインドの大切さ
コーヒー本の1/3くらいは、心理面での注意点に割かれているといってもよいでしょう。それほどまでに、レビューとは、「やらかしてしまう」イベントなのですね。本書に書かれたアンチパターンは、心当たりがありすぎて、猛烈な罪悪感なしには読めません。
たとえば問題記録票の文面について、こういう注意があります。
| 例えば「〜が一切ない」は「〜がない」で伝わります。 |
「一切」っておれも書いてるわ・・・あ、うん、時々だよ・・・?あまりにひどい時ね・・・。
いや、そうなんですよ。「一切」とかいらないですよね、いらないんです。角が立つだけで、誰の得にもならない。
こういう数々の「やらかし」が書かれていて、その度に自分の荒んだ心を読み取られているようで、 泣きながら一気に読みました。私もこれからこんなレビューをしてみたいなって思いました。こういうリアル心理を書けるのは、著者の森崎先生も同じ間違いを歩んできたからだと信じることで、心を鎮めている最中です。
ということで、このコーヒー本、特に大きなコストをかけることもなく(?)レビューを改善できるものとして、とてもオススメでございます。
なお、ご本人による紹介と、Itproでの関連記事へのリンクを載せておきます。
なお、ご本人による紹介と、Itproでの関連記事へのリンクを載せておきます。
2012年07月12日
今日も明日もレビューについて考える@SEA Forum
カテゴリ: SQ3.4-レビューの技法, イベント
SEA Forum in July 2012に参加してきました。
テーマは「レビューについてあらためて考えてみよう」。IBMの細川宣啓さんと、ソニーの永田敦さんのお二人のかけあいプレゼンテーションでした。特にピンときたポイントをご紹介したいと思います。(細川さん許諾ありw)
テーマは「レビューについてあらためて考えてみよう」。IBMの細川宣啓さんと、ソニーの永田敦さんのお二人のかけあいプレゼンテーションでした。特にピンときたポイントをご紹介したいと思います。(細川さん許諾ありw)
欠陥密度の分母と分子
欠陥密度とは、テストでいえば規模あたりの欠陥数、設計ドキュメントでいえば、ページ数あたりの欠陥数。「密度」というのは、何かしら客観的にモノを言っている感じのする魅惑のメトリクスです。
ただ個人的には、様々なソフトウェア開発において、設計工程における欠陥密度が一定の値の範囲にサワヤカに収まるとは思えません。ものすごーくブレるのが当然だと考えています。
なので、その場で設計工程のメトリクスには興味を失ってしまっていました。計測して意味あるのかよ・・・と。
なので、その場で設計工程のメトリクスには興味を失ってしまっていました。計測して意味あるのかよ・・・と。
ですがお二人から、以下のようなポイントを伺いました。
|
(1)の方は、ドキュメントの欠陥密度を考える人であれば一度は悩むポイントです。日本語のドキュメントのページ数を、どう正規化するのか。句読点数?文章メインでないドキュメントはどうする?
(2)はそもそも、考えたことがありませんでした。
確かに言われてみると、設計における欠陥には、仕様全体にインパクトのあるものから、軽微なものまであります。その粒度の幅は、テスト工程において見つかる欠陥より広いでしょう。では、粒度はどう合わせればいいでしょう。
確かに言われてみると、設計における欠陥には、仕様全体にインパクトのあるものから、軽微なものまであります。その粒度の幅は、テスト工程において見つかる欠陥より広いでしょう。では、粒度はどう合わせればいいでしょう。
(1)も(2)も、まだまだ理解できていないです。ちゃんと質問すればよかった・・・。同様の機会があれば、ぜひ伺いたいまくりたいところです。
トレンドを見る
永田さんの資料で、レビューによって設計の品質が改善していく様子が説明されました。時系列で追っていくと、欠陥密度が徐々に下がっていくというものです。
ここで重要なことは、この「時系列」が、いくつもの別のソフトウェア開発を比較しているわけではないということです。そうではなく、1つの開発における、小分けにしたレビューの結果のトレンドを追っています。
ここで重要なことは、この「時系列」が、いくつもの別のソフトウェア開発を比較しているわけではないということです。そうではなく、1つの開発における、小分けにしたレビューの結果のトレンドを追っています。
ただでさえブレの大きい設計工程なのに、それぞれ特性の違うソフトウェアにおけるデータを比較することには、多分あまり意味がない。アジャイル・インスペクションについてはレビュー祭りでも教えていただきましたが、1つの開発で、同じチームと行うレビューだからこそトレンドを見る価値があり、改善を確認することができるのですね。
その考え方は、細川さんの「2時間のレビューを1回やるより、15分のレビューを8回やる!」にも現れています。
その考え方は、細川さんの「2時間のレビューを1回やるより、15分のレビューを8回やる!」にも現れています。
レビューとはそもそも
細川さんは、「レビューとは、悪さの知識の移転場所」という考えです。それを推し進めると、その知識は移転可能な形になっていないといけない。1つ1つの欠陥の「インスタンス」ではなく、それを幾分抽象化した形にして、保存しなくてはならないのです。
この他にも、レビュー速度・サンプリングレートの考え方や、レビュー計画書の必要性(まずは書いてみよう!)など、示唆に富むお話がたくさんありました。
たとえば「レビューはまとめて1回じゃなくて、10回やることにしよう」などといきなりプロジェクトの方針を転換できるかと言えば難しいのですが、教えていただいた考えを少しずつ推し進めて行こうと思います。
2012年06月02日
レビューの「質」はどのように測ればいいのか
カテゴリ: SQ3.4-レビューの技法
盛況だったようで何よりです。、「レビューの質の測定」に関して、以前に関連する記事を書いたことが有りますので、ご参考まで。 bit.ly/KdyKrL @yamaguchi0307: @koike0125 無事終了しました。今度のテーマは、「レビューの質の測定」です
— 小池利和さん (@koike0125) 5月 10, 2012 紹介されている手法は、レビューのやり方・プロセスに着目したもので、アンケート形式でレビューの質を測定・見える化しようというアプローチです。
レビュー関係者に、12の設問に回答してもらい、レーダーチャートでそのレビューの良し悪しを把握する。設問は、「レビュー前/レビュー中」「主催者/参加者」という2つの切り口でも分類されており、その分析もできます。
レビュー関係者に、12の設問に回答してもらい、レーダーチャートでそのレビューの良し悪しを把握する。設問は、「レビュー前/レビュー中」「主催者/参加者」という2つの切り口でも分類されており、その分析もできます。
テストと比べて、レビューの定量評価って難しいなあと感じたぼくはかつて、この手法を試してみました!正直申しまして長期間続けたわけではないのですが、特にいいなと思った点が2つあります。
(1)測定が楽
レビュー後、関係者がアンケートに回答するのに1分もかかりません。
(2)改善する気になる
たとえば「事前に資料配布されてないよね」と分かっていることでも、点数が低く、レーダーチャートが思い切り凹んでいたりすると、あらためて「やらねば」って気持ちになります。
というのと、点数を付けられると、人ってその点数を上げたくなるもんで、それが行動に顕れます。アンケートでの5段階評価はいわゆる順序尺度ではありますが、やはり数字の力は強い。
というのと、点数を付けられると、人ってその点数を上げたくなるもんで、それが行動に顕れます。アンケートでの5段階評価はいわゆる順序尺度ではありますが、やはり数字の力は強い。
一方、気になる点は以下。
(1)つける点数がばらつく
これは仕方ないですね。甘い人と厳しい人がいます。
(2)気を使う?
ささっとアンケートをやってもらおうとすると、どうしても他の人に回答が見えちゃったりする。そこで「レビューリーダのファシリテートは適切だったか」という設問に「改善の余地あり」をつけられるかというと・・・。
また、試行しているときに周りと議論になった設問は、「脱線することが少なかったか」でした。
脱線が少ないほうが高得点になるのですが、なんといいますか、いろんな思いつきをぶつけることを目的とするレビューもあるよなあと。
たとえばDRBFMなんてものは、いろんな立場の人の観点をぶつけあうプロセスもあったりするので、うまく設問とそぐわないかなと思いました。単にそれを「脱線」と呼ばないのかも知れませんが。
脱線が少ないほうが高得点になるのですが、なんといいますか、いろんな思いつきをぶつけることを目的とするレビューもあるよなあと。
たとえばDRBFMなんてものは、いろんな立場の人の観点をぶつけあうプロセスもあったりするので、うまく設問とそぐわないかなと思いました。単にそれを「脱線」と呼ばないのかも知れませんが。
なんて話をできるといいですね!
さあ、次回はいつ開催されるでしょう。
さあ、次回はいつ開催されるでしょう。
2012年03月09日
Wordを使い込んで魔法使いを目指す - ロギング編
カテゴリ: SQ3.4-レビューの技法, MS Office
前回は、Microsoft Wordでのドキュメント作成を並行して行う場合の機能、「グループ文書」を紹介しました。今回のエントリではまた、Wordの標準機能の紹介をします。
ロギングの面倒を減らす
インスペクションでは、レビューの前に「ロギング」を行うことになっていますね。各レビュアーがレビュー前に、レビュー対象のドキュメントに対する指摘事項を記録しておく作業です。
ふつうは、指摘事項を記入するシートがExcelで配られて、レビュアーはそこに記入してくるんじゃないでしょうか。
ふつうは、指摘事項を記入するシートがExcelで配られて、レビュアーはそこに記入してくるんじゃないでしょうか。
このExcelシート式がいやなのは、ドキュメントのどこに対する指摘かというのを、ページ番号なり章番号なり、あるいは該当の記述内容なりを転記しなくてはいけない点。ページ番号も章番号も移ろいゆくものだし、ドキュメントの記述を写すのも、何やら虚しいですよね。
そこでわたしが好きなのは、Wordのメジャー機能・「コメント」です。
WordとExcelをいちいち行ったり来たりしながら記入するのではなく、指摘事項をそのまま、コメントとして書く。Excelに転記するより100倍速いし、見た目もキレイ。
WordとExcelをいちいち行ったり来たりしながら記入するのではなく、指摘事項をそのまま、コメントとして書く。Excelに転記するより100倍速いし、見た目もキレイ。
元の文書と、それにAさんがコメントを入れたイメージが以下です。

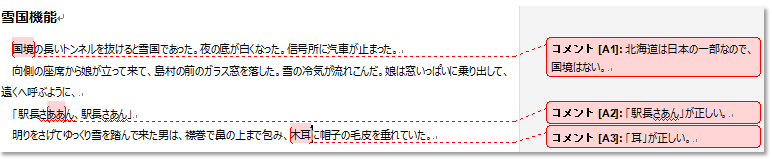
コメントのデフォルトのスタイルは、フォントも行間も大きいので、小さく狭く設定しなおしています。指摘事項がたくさんあるなら、これは必須です。
ちなみに、クイックアクセスツールバーにはもちろん、「コメントの追加」「コメントの削除」のショートカットをおいています。
ちなみに、クイックアクセスツールバーにはもちろん、「コメントの追加」「コメントの削除」のショートカットをおいています。
インスペクションの前に統合する
さて、このままではWordファイルが各人のもとで枝分かれしていますね。下の絵は、Bさんのロギング結果です。
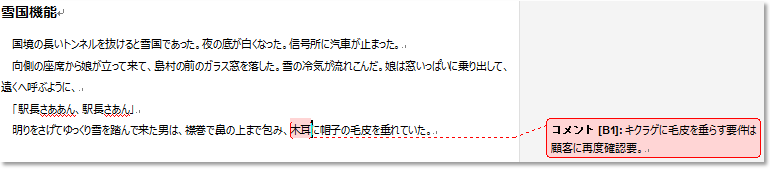
Wordでは、1つの文書から派生した文書を、元の文書に統合することができます。原型を留めていないくらい文章が変わっているなら統合する意味がありませんが、今回やりたいことは、コメントの統合。本文自体は変わっていないというところがミソです。
詳しい操作方法はMicrosoftの公式ページに掲載されています。「校閲」リボンの「比較」-「組込み」で、コメントの差分をすべて、元文書に組み込むことができます。結果は以下。
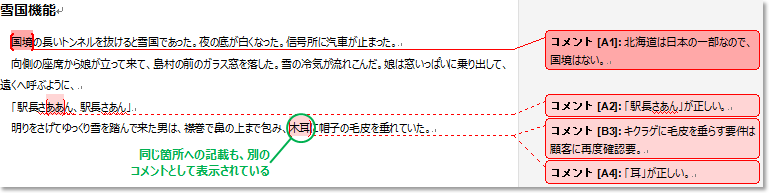
AさんとBさんのコメントが、すべてまとまっていることがわかります。二人が同じ範囲にコメントしていたとしても、別々のコメントとして扱ってくれていますね。
まあ正直言うと、この統合作業は1ファイル1ファイル行う必要はあるので、レビュアーが多いとちょっと面倒かも知れない。
まあ正直言うと、この統合作業は1ファイル1ファイル行う必要はあるので、レビュアーが多いとちょっと面倒かも知れない。
インスペクションに臨む
さて、これですべてのレビュアーの指摘事項が組み込まれた、1つのWordドキュメントができました。
誤字脱字も指摘に含まれているのであれば、レビュイーはそれを事前に修正しておき、インスペクションの場には、本質的な指摘だけを残しておくとよいでしょうね。
誤字脱字も指摘に含まれているのであれば、レビュイーはそれを事前に修正しておき、インスペクションの場には、本質的な指摘だけを残しておくとよいでしょうね。
レビュアーはみんなドキュメントに目を通しているはずなので、レビューの場ではドキュメントを紙に印刷せず、プロジェクターに映して進めても問題ないかも知れません。指摘に対する対応を全員で確認しながら進めることができます。
指摘に対する回答・対応は、このコメントにそのまま書いてしまってもいいでしょう。その場合、指摘事項と回答を分離するための、明示的なセパレターを決めておくと、後から少し楽かも。たとえば「|||」とか。指摘の中で偶然出現することがなさそうな文字列がいいです。
指摘に対する回答・対応は、このコメントにそのまま書いてしまってもいいでしょう。その場合、指摘事項と回答を分離するための、明示的なセパレターを決めておくと、後から少し楽かも。たとえば「|||」とか。指摘の中で偶然出現することがなさそうな文字列がいいです。
指摘事項を管理する
さて、Wordの機能を使うことで、Excel記入の手間を省いたわけですが、「レビュー指摘事項は一覧にして管理せよ」がルールになっている組織もあるでしょう。インスペクションでは、指摘事項が正しく対策されているかのフォローも必要です。
そんなとき、やっぱりExcelシートへの転記は必要になる可能性はあります。Wordのコメントを1つ1つ拾ってExcelに転記していく作業はやりたくない。Wordからコメントを抽出する方法はあるのでしょうか。
そんなとき、やっぱりExcelシートへの転記は必要になる可能性はあります。Wordのコメントを1つ1つ拾ってExcelに転記していく作業はやりたくない。Wordからコメントを抽出する方法はあるのでしょうか。
そうサワヤカではないかも知れませんが、少なくともひとつは方法があります。
まず、Word2007はOpen XML形式とやらで、実態がXMLです。ドキュメントの「*.docx」を「*.zip」に書き換えて、それを通常の圧縮ファイルのように展開してみてください。
Open XML形式に詳しいわけではないのでボロを出さないようなザックリ説明に終止しますが、展開したフォルダのサブフォルダ「word」の中を見ると、複数のXMLファイルがあることがわかります。
本文は、「document.xml」に入っています。で、コメントは「comments.xml」に入っているのです。
本文は、「document.xml」に入っています。で、コメントは「comments.xml」に入っているのです。
ここまで来ればもうわかるね。
このファイルに、コメントをした人間の名前も、日付時刻も、内容も全部記述されている。XMLからこれらをぶっこ抜くツールを作ってExcelに貼りつけよう!ついでに、コメントで使ったセパレータを利用して、指摘と回答も別の項目として分離しよう!そして、そのツールはわたしに譲ってください。
このファイルに、コメントをした人間の名前も、日付時刻も、内容も全部記述されている。XMLからこれらをぶっこ抜くツールを作ってExcelに貼りつけよう!ついでに、コメントで使ったセパレータを利用して、指摘と回答も別の項目として分離しよう!そして、そのツールはわたしに譲ってください。
ということで
ともあれ、「記録が残っている」ことが大事だとしても、「記録する作業」自体が大事なわけじゃないでしょう。ロギングするにしても、気のついたことを気のついた箇所にぱっと書けるコメント機能と、文書統合機能を使って、レビュー作業をもう少し軽くすることができるのでは?という提案でした。
2012年03月02日
Wordを使い込んで魔法使いを目指す - 執筆編
カテゴリ: SQ3.4-レビューの技法, MS Office
コンピュータの使い方に精通している人のことを、「wizard」(魔法使い)と言ったりします。長沢智治さんのMicrosoft Powerpoint超絶技巧はまさにウィザード。「パワー・ポッター」の異名を取っていますね。
このエントリではより地味な、Microsoft Wordの便利な使い方を紹介します。文章がメインとなる設計書を、Wordで作るという前提でのお話です。
Wordを分割 -> 統合する場合の問題点
さて、設計書はみんなで書くわけですが、この作業、どうやって「並行して」行なっていますか?
Excelは「ブックの共有」機能によって、1つのファイルを複数の人が同時に編集することが可能ですが、Wordの場合はファイルを章ごと、機能ごとに分割して編集するという運用が多いでしょう。
分割した複数のファイルを、最終的に統合する必要がある場合は、コピペ大会、章番号の振り直し、目次の作り直しといった、楽しくない作業が発生することがあります。
Excelは「ブックの共有」機能によって、1つのファイルを複数の人が同時に編集することが可能ですが、Wordの場合はファイルを章ごと、機能ごとに分割して編集するという運用が多いでしょう。
分割した複数のファイルを、最終的に統合する必要がある場合は、コピペ大会、章番号の振り直し、目次の作り直しといった、楽しくない作業が発生することがあります。
「グループ文書」機能とは
この作業を、もう少しさわやかにする機能が、Wordにはあります。
それが「グループ文書」という機能です。
それが「グループ文書」という機能です。
グループ文書の機能は、HTMLのframeをイメージしてもらえればいいでしょう。最近あまり見ないけど。
グループ文書機能では、親文書があり、その中に、呼び出す子文書のリンクを記述する形になります。この親を「グループ文書」、子を「サブ文書」といいます。
グループ文書機能では、親文書があり、その中に、呼び出す子文書のリンクを記述する形になります。この親を「グループ文書」、子を「サブ文書」といいます。
グループ文書を「印刷レイアウト」で表示すると、下のように見えます。
文書の中に、2つのサブ文書へのパスが書かれています。2行目に目次を埋め込んでいますが、サブ文書が展開されていないため、「目次項目が見つかりません。」とエラーが出ています。
文書の中に、2つのサブ文書へのパスが書かれています。2行目に目次を埋め込んでいますが、サブ文書が展開されていないため、「目次項目が見つかりません。」とエラーが出ています。
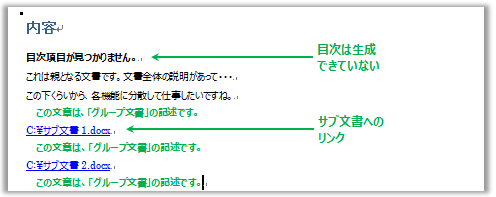
グループ文書の中で指定されたサブ文書1とサブ文書2は、それぞれ独立したファイルで、中身は以下です。
階層構造になっていますが、2つのファイルの中でそれぞれ、「1」から始まっていることに注意してください。
階層構造になっていますが、2つのファイルの中でそれぞれ、「1」から始まっていることに注意してください。


さて、先のグループ文書を「アウトライン」で表示したのが以下。サブ文書を呼び出す箇所がフレームで囲まれています。
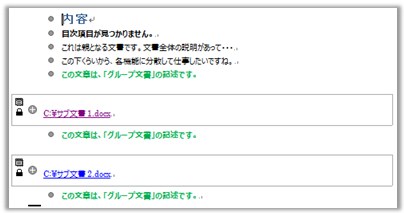
このサブ文書を展開すると、以下のように見えます。なお、「目次」についても、フィールドの更新をすることで再構成しています。
見た目上、1つの文書として表示されているとともに、目次も階層構造も、グループ文書全体で正しく解釈されていることがわかります。
ちなみに、今回Cドライブ直下にファイルを置いていますが、ファイルを移動してもリンクは追随してくれました。それでもリンク切れが不安であれば、サブ文書を参照するのではなく、サブ文書の中身をグループ文書の中に、実態として埋め込むこともできます。
ちなみに、今回Cドライブ直下にファイルを置いていますが、ファイルを移動してもリンクは追随してくれました。それでもリンク切れが不安であれば、サブ文書を参照するのではなく、サブ文書の中身をグループ文書の中に、実態として埋め込むこともできます。
メリットと注意点
この「グループ文書」機能の使い方は、最終的にドキュメントを統合する人が知っていればよくて、個々のサブ文書はこれまで同じように作ればいいというのがメリットです。
ただし、各文書が正しい階層構造で記述されていないと、統合後は悲惨なことになるでしょう。Wordドキュメントの構造のルールを事前に決めておくこと。そして、「スタイル」を用意し、ドキュメントの体裁も統一することが大切です。
ただし、各文書が正しい階層構造で記述されていないと、統合後は悲惨なことになるでしょう。Wordドキュメントの構造のルールを事前に決めておくこと。そして、「スタイル」を用意し、ドキュメントの体裁も統一することが大切です。
なお、このスタイル機能も、あまり知られていない、使われていない機能かも知れません。Webページにおけるスタイルシートと同じ役割のものということだけでも知っていれば、その便利さがわかると思うんですけどねえ・・・。
という話をしっかり書いてくれているのが、『エンジニアのためのWord再入門講座』。特にスタイル機能について充実した説明があり、Wordでドキュメントを書く人みんなが読んでおくべき本だと思います。
とまあこのように、パワー・ポッターに対抗して、「魔法使いワードナ」への名乗りをあげようと思いましたが、そもそもこれはWordの標準機能っ・・・!馬鹿もーんっ・・・!通るかっ・・・!こんなもん・・・!
2012年02月25日
レビュー観点: 用語集に載せる言葉に注意を払おう
カテゴリ: SQ3.4-レビューの技法
エンタープライズ向けシステム開発において、お客様と合意を取るべき外部仕様書にはしばしば、「用語集」が作られます。今回はその用語集の話。
広辞苑化する用語集
用語集ってけっこう厄介もので、目的を見失うと次のような用語が採録されます。
| HTTP: HyperText Transfer Protocol(ハイパーテキスト転送プロトコル) |
・・・誰も嬉しくない情報ですよね!?
もしかすると、ITに疎いお客様への思いやりかも知れませんが、そのまま突き進むと「Windows 7: Windows Vista の後継として開発されたパソコン用のオペレーティングシステム」(Windows 7)まで書く無間地獄に立ち入ることになります。
もしかすると、ITに疎いお客様への思いやりかも知れませんが、そのまま突き進むと「Windows 7: Windows Vista の後継として開発されたパソコン用のオペレーティングシステム」(Windows 7)まで書く無間地獄に立ち入ることになります。
一方、たとえば医療業界では、こんな用語も採録されそうです。
| MR: 医薬情報担当者 |
まあ、別にあったからって害があるわけじゃないのですが、これをやり始めたらキリがない。こういった業界用語集を、開発部隊向けに内部で持っているのはいいと思いますが、設計書に載せるのはイマイチかと。
用語集に載せるべき用語
用語集に載せるかどうかを決める基準って何だろう、と考えてみました。
まず、「用語」は、以下の4象限に分類することができます。すぐにマトリクスで切るのが、アメリカのコンサル会社っぽくてかっこいいと信じている。
まず、「用語」は、以下の4象限に分類することができます。すぐにマトリクスで切るのが、アメリカのコンサル会社っぽくてかっこいいと信じている。
| ビジネス | テクノロジー | |
|---|---|---|
| 一般 | (a)ドメインの用語 | (b)技術の用語 |
| 特殊 | (c)組織独自の用語 | (d)システム独自の用語 |
一般用語である(a)の「MR」も、(b)の「HTTP」も、google先生が全部教えてくれます。用語集に載せるべきなのは「特殊」行の2つ、(c)と(d)です。
エンタープライズ系システムであればきっと、その業界用語よりもさらにローカルな、会社固有の言葉を使うことになります。それが(c)です。
特に厄介なのは、「一般的な言葉ではあるが、我が社では特別な意味で使っている」というもの。かならず載せたい。
たとえば「新入社員」という用語が、「学校を卒業して就職してから1年以内の者」なのか、中途採用されて1年以内の人も含むのか。誤解のリスクがあるなら、用語として明記しましょう。
特に厄介なのは、「一般的な言葉ではあるが、我が社では特別な意味で使っている」というもの。かならず載せたい。
たとえば「新入社員」という用語が、「学校を卒業して就職してから1年以内の者」なのか、中途採用されて1年以内の人も含むのか。誤解のリスクがあるなら、用語として明記しましょう。
そのユーザの組織でもともと使われていたわけではないが、開発しているシステムのために新しく定義する用語が(d)です。
たとえば、本の「予約」という機能について、「入荷したばかりでまだ貸し出しを行なっていない本に対する予約は、通常の予約と区別するために『仮予約』と呼ぶ」みたいな話ですね。
たとえば、本の「予約」という機能について、「入荷したばかりでまだ貸し出しを行なっていない本に対する予約は、通常の予約と区別するために『仮予約』と呼ぶ」みたいな話ですね。
フィードバックするがいい
(c)と(d)について、お客様と開発者で認識違いがあると、あとあと悲惨なことになります。
「用語集のメンテくらい大した手間もかからないし、思いついたものは載せておこう」式でも悪くはないかも知れませんが、その反動で、載せるべき言葉が載っていないことにならないよう、気を付けたいですね。
設計ドキュメントを書きながら、「これって一般用語じゃないかも?」と思ったら用語集に立ち返り、他の箇所での使用を確認するのがいいと思います。
「用語集のメンテくらい大した手間もかからないし、思いついたものは載せておこう」式でも悪くはないかも知れませんが、その反動で、載せるべき言葉が載っていないことにならないよう、気を付けたいですね。
設計ドキュメントを書きながら、「これって一般用語じゃないかも?」と思ったら用語集に立ち返り、他の箇所での使用を確認するのがいいと思います。
みなさんの組織では、用語集にどのような言葉を載せていますか?自分の思いだけで書いているので、反対意見も聞きたい。
で、次回こそ、「マーブル仕様書」と「用語集」に関するトピックを書きたいのであった。
で、次回こそ、「マーブル仕様書」と「用語集」に関するトピックを書きたいのであった。
2012年01月29日
レビュー観点: 反町の「の」の曖昧さの回避の方法
カテゴリ: SQ3.4-レビューの技法
関係代名詞の「限定用法」と「叙述用法」を覚えていますか。
例文をコチラから引いてみます。
例文をコチラから引いてみます。
|
差はカンマの有無だけですが、意味がまったく違ってきます。この「few」について、限定用法の(1)が指しているのは「重傷じゃない乗客」、叙述用法の(2)が指しているのは「乗客」ですよね。
重要なポイントとして(1)は、「重傷じゃない乗客」という限定が、逆に「重傷である乗客」の存在を暗示していることです。
この違いを踏まえたうえで・・・。
重要なポイントとして(1)は、「重傷じゃない乗客」という限定が、逆に「重傷である乗客」の存在を暗示していることです。
この違いを踏まえたうえで・・・。
反町隆史の「の」
この関係代名詞のような表現が、(自然な)日本語にはないので、ややこしいことが起きます。
|
(1)は、一覧表示される条件が 延滞中 ∧ 新着図書 であることが、まあわかる。なぜなら、「延滞中か否か」と「新着図書か否か」とは、直交する条件であると自然に推測できるからです。
(2)はどうか。「購入から2週間以内か否か」と「新着図書か否か」とは、直交するという確信がもてないと思いませんか。どちらも、「購入からの経過時間」に関係していそうだからです。
よって、2つの意味に解釈することができます。
叙述用法的な意味なら、「新着図書・・・ああ、これは購入から2週間以内の図書を指すんだけどね。それを一覧表示したいんだ」というアメリカ文学みたいな仕様。
限定用法的な意味なら、「新着図書のうち、購入から2週間以内のものを、一覧表示する」という仕様。
叙述用法的な意味なら、「新着図書・・・ああ、これは購入から2週間以内の図書を指すんだけどね。それを一覧表示したいんだ」というアメリカ文学みたいな仕様。
限定用法的な意味なら、「新着図書のうち、購入から2週間以内のものを、一覧表示する」という仕様。
「以内の」の「の」のせいで言いたいことが言えない。そんな「の」はまさに poison のような危険さをもっています。
この曖昧さを回避するための表現方法として、
|
などが考えられます。
とにかく「の」は危ない。意味が多すぎるんだ。
とにかく「の」は危ない。意味が多すぎるんだ。
一粒で二度おいしいマーブル模様の仕様書
この「反町仕様書」の派生版が「マーブル仕様書」です。
例を挙げてみます。
例を挙げてみます。
| 「廃棄済みの書籍(廃棄フラグ=1)は一覧に表示しない」 |
この仕様には嫌な点が2つあります。
一つ目は、カッコ内を体言止めにしていること。カッコ内の体言止めは、反町の「の」と同じ、曖昧さをもたらす poison です。
次の二つの文では、カッコ内の言葉が果たす役割が違います。前者では叙述用法、後者では限定用法ですね。
一つ目は、カッコ内を体言止めにしていること。カッコ内の体言止めは、反町の「の」と同じ、曖昧さをもたらす poison です。
次の二つの文では、カッコ内の言葉が果たす役割が違います。前者では叙述用法、後者では限定用法ですね。
|
もう一つは、外部仕様の話を、内部的なパラメタで補う、あるいは限定していること。
次の工程への優しさなのかも知れませんが、たとえば外部仕様書をレビューするお客様にとっては意味のない記述でしょうし、上述のような曖昧さをはらんでいるだけに、あまりよい方法とは思えません。
次の工程への優しさなのかも知れませんが、たとえば外部仕様書をレビューするお客様にとっては意味のない記述でしょうし、上述のような曖昧さをはらんでいるだけに、あまりよい方法とは思えません。
それでは、外部仕様と内部仕様の「言葉」をどう繋げばいいのか。
これはまた別の話になりますので、別のエントリーで。
これはまた別の話になりますので、別のエントリーで。
2012年01月21日
IBM細川さんに、レビューのサンプリング技を学ぶ #infotalk
カテゴリ: イベント, SQ3.4-レビューの技法
| ICT関連の熱い技術,面白い活用等を取り上げ,いろいろと議論したりする場(勉強会&交流会) |
だそうです。
その第38回は、日本IBMの細川宣啓さんによる「ソフトウェア品質検査技術と静的解析〜インスペクション技術を中心に」というテーマ。ソフトウェア品質技術者たまねぎ戦士のわたしとしては外せないイベントです。
その第38回は、日本IBMの細川宣啓さんによる「ソフトウェア品質検査技術と静的解析〜インスペクション技術を中心に」というテーマ。ソフトウェア品質技術者たまねぎ戦士のわたしとしては外せないイベントです。
このエントリーでは、その内容を一部、お伝えしたいと思います。
なお発表のスライドは(まだ)公開されていませんが、内容の一部は細川さんの別の講演でも紹介されているので、そのスライドをご参照ください。たとえば、コチラ(PDF)です。わたしの記事には文章しかないので、わかりづらいと思います。
なお発表のスライドは(まだ)公開されていませんが、内容の一部は細川さんの別の講演でも紹介されているので、そのスライドをご参照ください。たとえば、コチラ(PDF)です。わたしの記事には文章しかないので、わかりづらいと思います。
サンプリングの重要性
大きなテーマがいくつかありましたが、わたしが特に気になったのは2つ。ドキュメントのレビューとコードインスペクション、それぞれの対象の選び方です。
レビュー自体の能力ももちろん重要ですが、その能力を最大限生かすためには、対象を効率よくサンプリングする能力が必要なのですね。
レビュー自体の能力ももちろん重要ですが、その能力を最大限生かすためには、対象を効率よくサンプリングする能力が必要なのですね。
V字モデルで開発している組織は多いと思いますが、その実態は、設計のある段階からテストのある段階までを外注する、つまりV字の下の部分を自分たちでは行わない「洗面器モデル」。
その洗面器に入れる「発注時のドキュメント」と、洗面器から出てくる「納品時のプログラム」の品質の見極めが大事であり、そのためにはそれぞれを適切にサンプリングする方法が必要だというお話です。
その洗面器に入れる「発注時のドキュメント」と、洗面器から出てくる「納品時のプログラム」の品質の見極めが大事であり、そのためにはそれぞれを適切にサンプリングする方法が必要だというお話です。
ドキュメントのサンプリング
まずはドキュメント。膨大なドキュメントからどう、品質的なリスクの高いものをサンプリングするか。
設計工程で得られるデータといえば、見積もり規模、ドキュメントの枚数、レビュー工数、レビュー指摘件数などでしょうか。
これらを組み合わせて、何がしかのメトリクスを作ることはできます。伝統的な指標については、たとえば『定量的品質予測のススメ』にたくさん載っています。
これらを組み合わせて、何がしかのメトリクスを作ることはできます。伝統的な指標については、たとえば『定量的品質予測のススメ』にたくさん載っています。
ですが細川さんの提示された散布図は、これらをなぎ倒すものです。
この散布図、ドキュメントの最終更新日時の「日付」横軸に、「時刻」を縦軸に持っています。そこにはどんなパターンが現れるでしょう。
この散布図、ドキュメントの最終更新日時の「日付」横軸に、「時刻」を縦軸に持っています。そこにはどんなパターンが現れるでしょう。
たとえば、縦に現れる強い筋。縦ということは同じ日に多くのドキュメントを更新しまくっているということで、つまりは納品直前だったりします。
さらにその納品日直後に、台形を左に倒したような形(右に長い辺、左に短い辺)。これは、「納品日は早上がりして、酒を飲みにいく。翌日以降は一時的に、出勤時刻が遅く、退勤時刻が早くなるが、納品後のお客様指摘への対応のために徐々に労働時間が長く・・・」ということを意味するとのこと(笑)。
さらにその納品日直後に、台形を左に倒したような形(右に長い辺、左に短い辺)。これは、「納品日は早上がりして、酒を飲みにいく。翌日以降は一時的に、出勤時刻が遅く、退勤時刻が早くなるが、納品後のお客様指摘への対応のために徐々に労働時間が長く・・・」ということを意味するとのこと(笑)。
「最終更新日時」なんていう普段は気にもしない属性が、プロジェクトの様子を如実に表していますね。
このように、グラフが示すパターンから事実を読み取ることを「グラフマイニング」と呼んでいました。特徴的な欠陥パターンの例として、以下のものがあるそうです。
このように、グラフが示すパターンから事実を読み取ることを「グラフマイニング」と呼んでいました。特徴的な欠陥パターンの例として、以下のものがあるそうです。
・Overnight Work
午前3時にプロットがある。おつかれさま・・・。でも、そんな時間帯に一人で更新すると、すり合わせ不足による矛盾・不統一の欠陥が多いかも知れない。
・2-cluster
外部設計書と内部設計書、それぞれの納品日直前の黒い筋。この間隔に全然プロットがないということは、内部設計書を書き始めてから、外部設計書をほとんど更新していないということ。仕様追跡性の欠如が疑われる。
身につまされるお話。。。
IBMでは、成果物の品質のリスクになるパターンを10数個に整理しているそうです。それらのパターンをもったあたりを狙い撃ちすることで、危ないところから潰していけるということですね。
IBMでは、成果物の品質のリスクになるパターンを10数個に整理しているそうです。それらのパターンをもったあたりを狙い撃ちすることで、危ないところから潰していけるということですね。
コードのサンプリング
まず、細川さん謹製の「欠陥の魚群探知機」という散布図。
上から下が、基底クラスから派生クラス。左から右が、重い欠陥から軽いバグとしてプロットしています。
たとえば横に強い筋があれば、広くたくさん誤っているということで、人を次ぎ込む必要がある。縦に強い筋が現れていれば、標準化をミスっているため、みんなで間違っているのかも知れない。こんなことが読み取れると言います。
上から下が、基底クラスから派生クラス。左から右が、重い欠陥から軽いバグとしてプロットしています。
たとえば横に強い筋があれば、広くたくさん誤っているということで、人を次ぎ込む必要がある。縦に強い筋が現れていれば、標準化をミスっているため、みんなで間違っているのかも知れない。こんなことが読み取れると言います。
さらに、すべてのソースファイルをスキャンして、「診断」に必要なパラメタを抽出します。行数、コメント率、IFの数、try~catchの数・・・。
これらのパラメタを組み合わせてメトリクスにして、「2万行のクラス」「コメント率が100%」「ifが数100個なのにelseがほとんどない」といったリスクの高い箇所を絞り込み、サンプリングの対象とします。
これらのパラメタを組み合わせてメトリクスにして、「2万行のクラス」「コメント率が100%」「ifが数100個なのにelseがほとんどない」といったリスクの高い箇所を絞り込み、サンプリングの対象とします。
コードインスペクション LIVE★
そのうえで、さあいよいよコードのロジックを・・・見ない。まず、ファイルを開いてコードをソートする。! ?
ソートにより、デッドコピーが1か所に集まってきたり、深すぎるネストの多さが可視化されたりするのです。これだけでも、ざっくり傾向がつかめるというのです。ダイナミック過ぎてすごい。
ソートにより、デッドコピーが1か所に集まってきたり、深すぎるネストの多さが可視化されたりするのです。これだけでも、ざっくり傾向がつかめるというのです。ダイナミック過ぎてすごい。
さらに今度は、書かれた言葉を検索する。「TODO」「TBD」「調整」など・・・。中国の開発においては、「XXX」という隠語が使われることもあるとのこと。
これらのコメントは、仕様がギリギリまで固まっていないとか、とりあえずの実装をしているといったリスクをはらむ。最悪のコメントして、「// 苦肉の策」なんてものまで紹介されました。
これらのコメントは、仕様がギリギリまで固まっていないとか、とりあえずの実装をしているといったリスクをはらむ。最悪のコメントして、「// 苦肉の策」なんてものまで紹介されました。
もちろんこれは、下準備。この後に本来のインスペクションがあるわけですが、その前段階としてできることがある、ということです。
なお、この言葉拾いは、わたし自身もドキュメントチェックの際にやっています。当初は、「以上/以下」「こともある」みたいな、間違えにつながりやすい言葉を拾っていましたが、そのうちより人間行動に着目しw、そっち系のキーワードを集めました。
わたしの場合「XX」と「**」をチェックしていますが、細川さんの観点とはちょっと違って、「XXX参照」「***に記載」のようにとりあえず書いたまま参照先のネタを作り忘れるということがあるためです。
わたしの場合「XX」と「**」をチェックしていますが、細川さんの観点とはちょっと違って、「XXX参照」「***に記載」のようにとりあえず書いたまま参照先のネタを作り忘れるということがあるためです。
その他にももっともっと
欠陥マスターDBについての話がありました。これは細川さんが以前から進めていた研究の一つで、欠陥の現象や原因を一般化し、その定義、発生の兆候、検出方法、除去方法、副作用などを整理したものです。
これらの特性を数値化し、それを「Shape of Defects」として可視化したり、欠陥同士の関連性を見つけたりという欠陥エンジニアリングの研究を進めているそうです。
これらの特性を数値化し、それを「Shape of Defects」として可視化したり、欠陥同士の関連性を見つけたりという欠陥エンジニアリングの研究を進めているそうです。
このようなトピックは、来週開催されるJaSST'12 Tokyoでもお話されるとのこと。JaSST参加予定の方は、ぜひ聞いてみることをオススメいたします。
細川さんはプレゼンの最後に、「日本のソフトウェア開発でもっとも不足しているのは、品質エンジニアだ!」と力説されていました。
品質とは本当に難しい分野だと思いますが、わたしもその一端を担えるようがんばりたいです。という、小学生の日記のような終わり方ですいません。
品質とは本当に難しい分野だと思いますが、わたしもその一端を担えるようがんばりたいです。という、小学生の日記のような終わり方ですいません。
2012年01月16日
レビュー観点: 勝手熟語を作ってくれるな
カテゴリ: SQ3.4-レビューの技法
前回のエントリーで載せた、レビュー形態のマッピングを再掲します。
昨年から地味に考え続けている(c)チェックリスト、つまり技術的な側面以外のチェック観点について、1つ目のものを書きます。
昨年から地味に考え続けている(c)チェックリスト、つまり技術的な側面以外のチェック観点について、1つ目のものを書きます。
勝手熟語生成問題日本以外全部沈没
「Verpixelungsrecht」というドイツ語があるそうです。googleストリートビューで撮影された自宅やオフィスの画像に対して、モザイク化を求める権利のこと。言葉を簡単に合成してしまうことで有名なドイツ語ならではですね。
この合成語を作り出す傾向が、ソフトウェア開発の設計ドキュメントで顕著に感じられるのはわたしだけでしょうか。
たとえば以下。
| 検索結果表示状態で複数項目選択時は・・・ |
中華一番!
「検索結果を表示した状態で、複数の項目を選択している場合は・・・」と書けばいいと思うのですが・・・。この短縮により何かメリットがあるのでしょうか。
「検索結果を表示した状態で、複数の項目を選択している場合は・・・」と書けばいいと思うのですが・・・。この短縮により何かメリットがあるのでしょうか。
これは「あるのでしょうか、いや、なかろう」という反語ではなく、疑問です。何かメリットがあるなら教えてください。
さて、勝手熟語が作られるプロセスは2つあり、それぞれ別の問題をもっています。
(1)サ変動詞を名詞に戻す
「残業をする」は、名詞+助詞+(サ変)動詞 という構造をもっていますが、「残業する」はそれ自体が1つの動詞です。「サ変動詞を省く」とは、「する」を省略して名詞に戻す行為を指します。
何が問題なのか。
「する」は動詞であり、動詞は活用を持つ。つまり「する」「される」「した」「された」といった、時制や態を持つのに、その情報をあえて捨てて、時制も態もない名詞に戻していることが問題です。
「する」は動詞であり、動詞は活用を持つ。つまり「する」「される」「した」「された」といった、時制や態を持つのに、その情報をあえて捨てて、時制も態もない名詞に戻していることが問題です。
たとえば「複数項目選択時」という勝手熟語を考えてみましょう。
|
この句点の後の行動・動作のタイミングはそれぞれ、いつなんでしょう。
(1)は「選択する前」で、(2)は「選択した後」。同じ言葉なのに、タイミングが異なりますよね。
文脈に応じて時制や態を読み手が解釈しないといけない。つまり、曖昧です。動作の説明をするドキュメントで、その動作が起こるタイミングが曖昧なのは悲しい。
(1)は「選択する前」で、(2)は「選択した後」。同じ言葉なのに、タイミングが異なりますよね。
文脈に応じて時制や態を読み手が解釈しないといけない。つまり、曖昧です。動作の説明をするドキュメントで、その動作が起こるタイミングが曖昧なのは悲しい。
(2)助詞などを省く
たとえば(1)「利用者閲覧済み記事」という合成語。この言葉を、(2)「利用者が閲覧した記事」と比べたとき、印象にどのような違いがありますか。
(2)だと、「閲覧」という操作がシステムとしてどういう意味を持つかまでは言及していないのに対し、(1)では、たとえば「閲覧済みフラグが立っている」など、「システムとして明確に特定できる言葉」であるような印象を受けます(よね?)。
合成語はもともと自然界に存在する言葉ではなく、そのシステムでいきなり生み落としているものなのだから、当然そのシステムにおいてクリアに定義された意味を持つべきということになります。そうでないなら助詞を省かず、自然な自然言語を使うのがいいと思います。
「自然言語」と「自然な言語」も、意味が違いますね。
結論というか、主張は以下です。
| 動詞や助詞の省略によって、言葉を不必要に3つ以上合成するのはやめよう。合成したらそれは新しい言葉、明確に定義しよう。 |
さて、この「明確に定義」に関する問題に、「マーブル模様の仕様書」というものがあります。多分次回は、これについて。
2012年01月07日
2012年はレビューにも想いを寄せる
カテゴリ: SQ3.4-レビューの技法
前回のエントリで書き忘れました。今年もよろしくお願いいたします。
拙ブログ、今年は1エントリ/10日+αで40本書く。そしていつしか量が質に転化して・・・という展開を目指しています。いつしかっていつだ。
拙ブログ、今年は1エントリ/10日+αで40本書く。そしていつしか量が質に転化して・・・という展開を目指しています。いつしかっていつだ。
レビューへの野望
2011年は「ソフトウェアテスト技法ドリル勉強会」のおかげで、テスト技法に関する勉強を進めることができました。
2012年はこれに加えて、「レビューどうやろうか」ってことをじっくり考えていきたいと思っています。昨年末のレビュー祭りでアジャイル・インスペクション、「ガイドを用いたサンプリングレビュー」の話を聞いたことが大きいですね。
2012年はこれに加えて、「レビューどうやろうか」ってことをじっくり考えていきたいと思っています。昨年末のレビュー祭りでアジャイル・インスペクション、「ガイドを用いたサンプリングレビュー」の話を聞いたことが大きいですね。
レビューは静的テストに分類されるのですが、プログラムのテストと大きく違う点があります。
テストケースがないことです。
何をもってよしとするかもよくわからないし、「レビューってどうやるの?」という疑問にも答えがたい。自分自身、システマティックにチェックやレビュー作業をしているとはとても言えない。
テストケースがないことです。
何をもってよしとするかもよくわからないし、「レビューってどうやるの?」という疑問にも答えがたい。自分自身、システマティックにチェックやレビュー作業をしているとはとても言えない。
細谷泰夫さんによる、SPI Japan 2011の発表資料・『産学連携によるデザインレビュー改善事例』を絶賛精読中なわけですが、このスライドp.8のような、レビューのロードマップを、自分なりに持っておきたいですね。
レビュー形態のマッピング
さて、スライドp.8の図を参考に、レビュー形態を次の2つの軸でマッピングしてみました。理解が誤っていたらスミマセン。
縦軸: 技術⇔ドキュメンテーション
「技術」はそのまま、技術的に妥当な設計かということを検討するもの。「ドキュメンテーション」(もっと適切な表現がありそう)は、用語の統一、ヘッダー・フッターといったエディトリアルな正しさや、記述の十分性、明確さなどを検討するもの。
横軸: サンプリング⇔全数
ドキュメントの一部を対象とするのか、全部を見るのか。
(A)(D)(E)がスライドにあるもの。(B)はレビュー祭りで習ったもの。(C)は今、自分で考えているものです。1つずつ見てみます。
(1)ドキュメンテーション×サンプリング の象限
まず、(A)アジャイル・インスペクションです。先の発表スライドにあるように、文書様式、言葉の定義、記述の粒度や深さという部分を見ます。技術的な妥当性は埒外。
使える道具として、エディトリアルな観点についてはプロジェクトや組織規定のチェックリストがあったり、曖昧さにつながる表現の検出については一部、ツールで機械的にチェックできますよね。
使える道具として、エディトリアルな観点についてはプロジェクトや組織規定のチェックリストがあったり、曖昧さにつながる表現の検出については一部、ツールで機械的にチェックできますよね。
(B)「ガイドを用いたサンプリングレビュー」の守備範囲はアジャイル・インスペクションと重複するものの、真にエディトリアルなところは見ないので、若干上側に。ここで使用する道具は、ガイド。
(2)ドキュメンテーション×全数 の象限
(C)チェックリストに基づくレビューってのを考えています。チェックリスト嫌いな人、かたじけない。
ここでいうチェックリストは、コーディング規約を羅列したようなものとか、過去の失敗事例に基づいて作成したような技術的・各論的なものではありません。開発対象のプログラムの性質にあまり依存しない、汎用的な項目です。
ここでいうチェックリストは、コーディング規約を羅列したようなものとか、過去の失敗事例に基づいて作成したような技術的・各論的なものではありません。開発対象のプログラムの性質にあまり依存しない、汎用的な項目です。
(3)技術×全数 の象限
(D)インスペクション。(C)との合わせ技で、技術的な妥当性と、それに伴う記述の十分性・正確性を担保する!というところでしょうか。言うだけなら簡単ですね。
レビュー担当者の成長パスとして、最初は(C)のチェックリストをたよりにレビューに貢献しつつ、次第に(D)にシフトしていく作戦。
レビュー担当者の成長パスとして、最初は(C)のチェックリストをたよりにレビューに貢献しつつ、次第に(D)にシフトしていく作戦。
(4)技術×サンプリング の象限
(E)ウォークスルーです。
(D)と(E)については、先のスライドにそれぞれ「自信のない部分を局所的に」「全体を通して」とあることから、この位置にしています。
(D)と(E)については、先のスライドにそれぞれ「自信のない部分を局所的に」「全体を通して」とあることから、この位置にしています。
で、今年よく考えていきたいと思っているのは、太い楕円のもの。(B)の「ガイド」と、(C)のチェック観点の手持ちを増やしたい。
(B)のガイドについては、レビュー祭りで習った入出力のガイドと、前回書いたキーワードマトリックスで、とりあえず2つ(笑)。
(C)のチェック観点として考えているものを、今後書けたらと思います。
(B)のガイドについては、レビュー祭りで習った入出力のガイドと、前回書いたキーワードマトリックスで、とりあえず2つ(笑)。
(C)のチェック観点として考えているものを、今後書けたらと思います。
もしかすると、車輪の劣化再発明を一生懸命やっているのかも知れません。参考になる本や記事などあれば、教えてくださいませ。
「技術的なチェックリスト」について
(C)のチェックリストは、技術的な事例の集まりじゃないよと書きましたが、「やりがちな失敗」「設計誤りの経験」みたいなものを、ノウハウとして蓄積していくのは正しいと思っています。
でもそれをチェックリストの体裁にして、設計後にそれに基づくチェックをする/させるというのは、アンチパターンかなと。挿話証拠「そんなチェックリストあるなら先に言ってよ」。
そういうノウハウは、ドキュメントを書く前に見て、理解しておくべきなんですよね。
でもそれをチェックリストの体裁にして、設計後にそれに基づくチェックをする/させるというのは、アンチパターンかなと。挿話証拠「そんなチェックリストあるなら先に言ってよ」。
そういうノウハウは、ドキュメントを書く前に見て、理解しておくべきなんですよね。
2012年01月04日
サンプリングレビューにおける「ガイド」を探した
カテゴリ: SQ3.4-レビューの技法
昨年11月に開催されたレビュー祭(ブログ記事)で、「ガイドを用いたサンプリングレビュー」というレビュー技法が紹介されました。
そこで提示された「ガイド」の例が、入出力のガイド。機能を記述した文章で、「入力」「処理」「出力」欄をきちんと埋められるかどうかで、記述の網羅性を判断します。埋まらない部分、埋めようとしても曖昧な部分が、仕様として不十分な箇所、ということになりますね。
そこで提示された「ガイド」の例が、入出力のガイド。機能を記述した文章で、「入力」「処理」「出力」欄をきちんと埋められるかどうかで、記述の網羅性を判断します。埋まらない部分、埋めようとしても曖昧な部分が、仕様として不十分な箇所、ということになりますね。
このようなガイド、他にどういうものがあるのでしょう。
『Engineer Mind』の連載『エンジニアよ、国語力に目を向けよう』(開米瑞浩氏)で紹介されている「キーワードマトリックス」が、まさにガイドとして使えると感じたので、紹介します。
『Engineer Mind』の連載『エンジニアよ、国語力に目を向けよう』(開米瑞浩氏)で紹介されている「キーワードマトリックス」が、まさにガイドとして使えると感じたので、紹介します。
記事では、Microsoft Windows XP Professional リソースキットの文章を引用しています。以下の引用はその孫引きです。
| ユーザープロファイルは、コンピュータにログオンしたユーザーごとに1つずつ作成され、規定の設定ではローカルコンピュータに保存されます。移動用のユーザープロファイルを構成しておくと、ユーザーがコンピュータからログオフしたときにユーザープロファイル内の設定がネットワークサーバーにコピーされ、そのユーザーが次にネットワーク上のどのコンピュータにログオンしても同じ設定が使用できるようになります。 |
何といいますか、清潔に書かれていますが、シーケンシャルに流れていって、頭にはなかなか入ってこない、そんな文章です。
開米さんはこの文章を、ステートメント(1つの意味だけを明確に表現した短い文)に解体し、グルーピングせよと教えています。するとこの文章は、(1)ユーザプロファイルの話 と (2)移動用のユーザプロファイルの話 に分けられることがわかります。
開米さんはこの文章を、ステートメント(1つの意味だけを明確に表現した短い文)に解体し、グルーピングせよと教えています。するとこの文章は、(1)ユーザプロファイルの話 と (2)移動用のユーザプロファイルの話 に分けられることがわかります。
キーワードマトリックスは、この再構築が終わった後に使います。
キーワードとは、上の文章でいう「ユーザプロファイル」「ログオン」など、説明の要となる言葉。さらにこのキーワードたちの、文章における属性を抽出して、マトリックスを作ります。そのマトリックスに、再構築したステートメントの内容を埋めていく。すると・・・
キーワードとは、上の文章でいう「ユーザプロファイル」「ログオン」など、説明の要となる言葉。さらにこのキーワードたちの、文章における属性を抽出して、マトリックスを作ります。そのマトリックスに、再構築したステートメントの内容を埋めていく。すると・・・
| 用途 | 作成の単位 | 保存場所 | 保存タイミング | メリット |
|---|---|---|---|---|
| (A) | コンピュータにログオンしたユーザごとに1つずつ | ローカルコンピュータ | (B) | (C) |
| 移動用 | ネットワークサーバ | ユーザのログオフ時 | どのコンピュータでも同じ設定が使える |
このように、「埋まっていない部分」が明確になるというわけです。
特に(B)は、仕様として明確にしておくべき場所でしょうが、元の文章から、「Bが抜けている」と見ぬくのは難しいですよね。
また「用途」列でわかるように、「移動用」に対して、「デフォルト」的なモノは、名前が省略されがちと指摘されていました。「ラッパ飲み」という言葉はありますが、「容器から飲み物をコップに注いでから飲む」という動作に名前がないのと同じですね。この名前の省略は、あとあと仕様の曖昧につながっていきます。
特に(B)は、仕様として明確にしておくべき場所でしょうが、元の文章から、「Bが抜けている」と見ぬくのは難しいですよね。
また「用途」列でわかるように、「移動用」に対して、「デフォルト」的なモノは、名前が省略されがちと指摘されていました。「ラッパ飲み」という言葉はありますが、「容器から飲み物をコップに注いでから飲む」という動作に名前がないのと同じですね。この名前の省略は、あとあと仕様の曖昧につながっていきます。
入出力ガイドに比べて、自分で属性を抽出しなくてはならない分難しくはなりますが、有効な方法だと思います。色々な要素が長文でダラダラ書かれているような箇所に適用するのがよさそうです。
ところで、開米瑞浩さんにはどんな著作があるのかな?と調べてみたところ、WACATE2011冬の予習本であり、ぼくも購入している『エンジニアのための図解思考 再入門講座』がまさに、それでした。2012年も、毎度毎度の出遅れ感・・・。
2011年11月18日
ド・モルガンの法則、そしてキルアのOR - その2
カテゴリ: SQ3.4-レビューの技法
今回はキルアとスタンド使いが出てきます。
ド・モルガンの法則の適用
法則の復習
ド・モルガンの法則とは、以下の2つですね。
|
腑に落とすために、次の例文を考えてみましょう。
| わたしの名はダービーというんだ! オービーでもバービーでもない! |
命題Pを「オービーである」、命題Qを「バービーである」とすると、「オービーでもバービーでもない」という言明は「オービーでない、かつ、バービーでない」、つまり「¬P ∧ ¬Q」ということになります。
これをド・モルガンの法則第1式で置換すると、「(オービーである、または、バービーである)ということはない」、ということになります。
これをド・モルガンの法則第1式で置換すると、「(オービーである、または、バービーである)ということはない」、ということになります。
NOT を消す試み
さて、何故こんなことを言い出したかというと、AND、OR、NOT が日常語に現れたとき、最も紛らわしいのはNOT だと思っているからです。で、ド・モルガンの法則を使えばその紛れを軽減することができるかも知れません。
たとえば、次のようなちょっとわかりづらい文章を書き換えていきましょう。
| 休日や19時を過ぎての入店でなければ、クーポンが使用可能です。 |
この前半部分を論理式に変換しやすいように書くと、
| (休日である または 19時より後) でない |
ド・モルガンの法則を適用して、
| 休日でない かつ 19時より後でない |
ここで、日常語ならではの変換をほどこします。
| 平日である かつ 19時以前である |
で、最終的に得られた命題は、
| 平日の19時以前であれば、クーポンが使用可能です。 |
最初の命題より、ちょっとだけ人間が理解しやすくなりました。
つまり、命題を結合した論理式全体にかかっていた否定語を、ド・モルガンの法則によって個々の命題に直接くっつけたうえで、日常語の変換をすることで、否定語を消すことができるかも知れないというお話です。特に大小関係は、「以上でない」が「未満」に変換できたりと、簡単です。
ただし、注意点が2つあります。
(1)本当に補集合か?
否定語を消して、¬A という表現を B に変換する場合に、B は A の補集合でなければなりません。AとBが、MECE であるといってもいい。
上の例でいうと、「休日以外」=「平日」である、つまり、「すべての日は、休日か平日のいずれかである」ことが保証されていないと、ダメです。
たとえば、これも秋山浩一さんのソフトウェアテスト技法ドリルで学んだことですが、ISO 5218 では、「人の性別の表示のためのコード」として、4つのコードを定義しています。「男性以外」を、そのまま「女性」と変換していいかは、考慮が必要ということですね。
上の例でいうと、「休日以外」=「平日」である、つまり、「すべての日は、休日か平日のいずれかである」ことが保証されていないと、ダメです。
たとえば、これも秋山浩一さんのソフトウェアテスト技法ドリルで学んだことですが、ISO 5218 では、「人の性別の表示のためのコード」として、4つのコードを定義しています。「男性以外」を、そのまま「女性」と変換していいかは、考慮が必要ということですね。
(2)大小関係の表現自体が・・・
そもそも、大小関係に関する日常語、たとえば「以上」「以下」「より大きい」「より小さい(未満)」という言葉自体が紛らわしい、避けろという話もあります。たしかに、不等号で表現する方が、紛れはないですね。
英語ではどうなっているのか
NOT と OR と、ド・モルガン
英語の事例を見てみましょう。
下の絵は、『HUNTER×HUNTER』というマンガのヒトコマです。
下の絵は、『HUNTER×HUNTER』というマンガのヒトコマです。
この右の吹き出しのセリフ、「右手を左足を使っていない」という表現は、英語でどう訳されていると思いますか?
| He hasn't used his right hand or left leg yet! |
「右手も左足も使っていない」と言うことを表すのに or を使うのは、ちょっと違和感がないでしょうか。
でも、ド・モルガンの法則を使って、こう理解することができます。
でも、ド・モルガンの法則を使って、こう理解することができます。
| NOT (right hand OR left leg) → (NOT right hand) AND (NOT left leg) |
つまり、右手を使っていない、かつ 左足を使っていない、と。
ここで and を使うとどうなるか。
ここで and を使うとどうなるか。
| NOT (right hand AND left leg) → (NOT right hand) OR (NOT left leg) |
つまり、右手を使っていない、または、左足を使っていない。これだと、「どっちも使っていない」という意味にならないですね。
Either or と Neither nor
命題AとBについて、次のような対応があります。
|
普通の論理和にぴったり一致する表現は見当たりませんね。Google Scholar で OR を用いると、排他的論理和XORで検索されるそうです。
はい、あまり英語のことを書くとボロが出るので控えめにします。
はい、あまり英語のことを書くとボロが出るので控えめにします。
2011年11月17日
ド・モルガンの法則、そしてキルアのOR - その1
カテゴリ: SQ3.4-レビューの技法
| 絶対ドラゴンズに勝って欲しい |
恥ずかしながら、この例文の何が曖昧なのか、なかなかわからなかったわたしですが、最近読んだ池上彰さんの著書にも、面白い「曖昧さ」の例がありました。
| 東京と長野の間を走る新幹線 |
こんな表現を聞いた男の子が池上さんに、「新幹線はどこへ行くの?」と問うたそうです。池上さんも初めは、何を聞かれているのか理解できなかったそうです。この文章の曖昧さ、わかりますか?
|
こう比べてみると、形式的には同じでも、「間」の意味がまったく違いますよね。
これってたとえばスマートフォンのタッチパネルなんかで、「アイコンとアイコンの間をフリックすると、」みたいな表現は、誤解を招きかねないってことなのかと。言葉ってやはり難しい・・・。
これってたとえばスマートフォンのタッチパネルなんかで、「アイコンとアイコンの間をフリックすると、」みたいな表現は、誤解を招きかねないってことなのかと。言葉ってやはり難しい・・・。
論理関係の曖昧さ
自然言語の曖昧さでもっとも重いのはやはり、論理式につながる表現だと思います。典型的なものは、以下の3つでしょうか。
否定の範囲の曖昧
たとえば、
| 平日で、かつ午後7時以降でない場合、 |
「でない」が「平日で」にもかかるなら、「平日でない、かつ、午後7時以降でない」のように、否定語は命題に直接くっつけて、さらに命題を読点で区切るなどして、少しはクリアにすることができるでしょう。スマートではないが・・・。
「平日で、かつ午後7時以降でもない場合」のように、「で」を「でも」にすることで、否定語が前の命題にもかかることを匂わすことはできますが、これは日本語以外だと、汲みとってもらうのが難しいかも。
「平日で、かつ午後7時以降でもない場合」のように、「で」を「でも」にすることで、否定語が前の命題にもかかることを匂わすことはできますが、これは日本語以外だと、汲みとってもらうのが難しいかも。
全否定と部分否定の曖昧
たとえば、
| すべてのチェックボックスがチェックされていない場合 |
チェックボックスが「() () ()」である状態(全否定)を言っているのか、「(レ) (レ) ()」という状態(部分否定)でも該当するのか曖昧。「すべて〜ない」という表現は危険です。
前者であれば、「チェックされているチェックボックスが1つもない場合」。後者であれば、「チェックされていないチェックボックスが1つでもある場合」の方がクリアですね。
前者であれば、「チェックされているチェックボックスが1つもない場合」。後者であれば、「チェックされていないチェックボックスが1つでもある場合」の方がクリアですね。
論理の優先度の曖昧
たとえば、
| 入会から5年以上経っている、または特別会員で、かつ購入額が20,000円以上の場合 |
論理演算子の優先度は一般的に、NOT > AND > OR となっているはずですが、それを暗黙に求められても困る。
実例として、品川図書館の検索システム。
5つの検索項目を結ぶ論理演算子に、AND、OR、NOTが自在に選べます。どういう検索結果を期待しているのか、ユーザにはわかりづらいところです。
5つの検索項目を結ぶ論理演算子に、AND、OR、NOTが自在に選べます。どういう検索結果を期待しているのか、ユーザにはわかりづらいところです。
閑話休題。
冒頭で触れた池上彰さんの本、けっこう面白かったです。言葉の誤用、変遷、敬語、カタカナ用語といった、日本語についてしばしば議論になるテーマを、池上さんらしい、丁寧で手堅く、決して炎上しない無難な語り口で一通りさらっていきます。
たとえば「悲喜こもごも」という言葉。
「入試の結果発表会場は悲喜こもごもで・・・」なんて使いがちですが、これ、誤用だそうです。一人の人間が、悲しみと喜びをかわるがわる味わうことだそうで。知りませんでした。
ちなみに上の「閑話休題」の使い方も、誤用です。「閑話休題」は、その後の話ではなく、それまでの話を無駄口をみなすわけですから・・・まあ、あながち誤用でもないか。。。
「入試の結果発表会場は悲喜こもごもで・・・」なんて使いがちですが、これ、誤用だそうです。一人の人間が、悲しみと喜びをかわるがわる味わうことだそうで。知りませんでした。
ちなみに上の「閑話休題」の使い方も、誤用です。「閑話休題」は、その後の話ではなく、それまでの話を無駄口をみなすわけですから・・・まあ、あながち誤用でもないか。。。
キルアもド・モルガンも出てこないまま、その1を終わります。
2011年11月09日
第1回レビュー祭で神輿の片棒かついできた - その3
カテゴリ: イベント, SQ3.4-レビューの技法
ガイドに基づくレビュー
3つ目は、「ガイドを用いたサンプリングレビュー」というワークショップ。与えられた「ガイド」に基づいて、ドキュメントの欠陥を摘出してみようという演習です。
「ガイド」とは?
「ガイド」とは、ドキュメント記述の妥当性を系統的に検証するための、簡易なフレームワークとわたしは理解しました。
企業のポートフォリオ戦略の話で、BCGモデルってありますよね。横軸を相対シェア、縦軸を市場成長率としたマトリクスに、各事業をマッピングする。市場成長率が低くて相対シェアが高い事業は「金のなる木」で・・・とかいうあれです。
複雑なものをたった2軸で表現できるはずはなく、色んな情報を落としているわけですが、それでも特定の切り口を与えて、その切り口にフォーカスして考えることで見えるものもある。
企業のポートフォリオ戦略の話で、BCGモデルってありますよね。横軸を相対シェア、縦軸を市場成長率としたマトリクスに、各事業をマッピングする。市場成長率が低くて相対シェアが高い事業は「金のなる木」で・・・とかいうあれです。
複雑なものをたった2軸で表現できるはずはなく、色んな情報を落としているわけですが、それでも特定の切り口を与えて、その切り口にフォーカスして考えることで見えるものもある。
レビューにおけるガイドも、同じ役割をもっています。1つの視点に基づいてレビューすることで、その視点については網羅的に確認ができる。普通ならアドホックに指摘が出て発散しがちな場を、1つのラインに乗せることもできる。
もちろん、ガイドによって検証できるのは、そのガイドが持つ切り口だけですが、いくつかのガイドを用意しておくことで、検証できる範囲は増えていきます。また、アジャイル・インスペクションでの「視点」と同様、欠陥を見つけるための手がかりがあるため、経験が豊富でないメンバーもレビュアーとして参加しやすいと言えます。
もちろん、ガイドによって検証できるのは、そのガイドが持つ切り口だけですが、いくつかのガイドを用意しておくことで、検証できる範囲は増えていきます。また、アジャイル・インスペクションでの「視点」と同様、欠陥を見つけるための手がかりがあるため、経験が豊富でないメンバーもレビュアーとして参加しやすいと言えます。
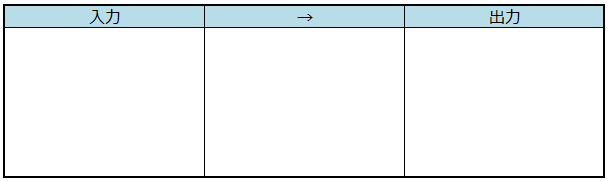
今回のガイドは「入出力」
今回のレビューで与えられたガイドは、「入力」「→」「出力」というもの。「入出力ガイド」と仮に呼んでおきます。こんな形の表。シンプルですね。
演習のテーマは「コンビニにおける、電子マネーでの決済機能」でした。
この機能は、レジから金額情報を受け取って、利用者が選択した電子マネー種別を判定して、残金から金額を引いてもマイナスにならないかを計算して・・・といういくつかの部分に分かれますよね(使ったことないので想像・・・)。で、それぞれの部分について、入力・処理・出力が決まっていないと、実装できない。
ただ、自然言語で叙述的に書いてあるドキュメントだと、その3点セットが漏れなく明確になっているか、ぱっと見わからないですよね。そこで、入出力ガイド。
この機能は、レジから金額情報を受け取って、利用者が選択した電子マネー種別を判定して、残金から金額を引いてもマイナスにならないかを計算して・・・といういくつかの部分に分かれますよね(使ったことないので想像・・・)。で、それぞれの部分について、入力・処理・出力が決まっていないと、実装できない。
ただ、自然言語で叙述的に書いてあるドキュメントだと、その3点セットが漏れなく明確になっているか、ぱっと見わからないですよね。そこで、入出力ガイド。
| 入力 ・入力元が明示されているか ・判定・処理に必要な情報の中身が明示されているか ・値の範囲が明示されているか 出力 ・出力先が明示されているか ・出力の中身が明示されているか ・いつ出力されるかが明示されているか 処理 ・出力を入力から導出する方法が明示されているか |
というポイントに注意しながら、ドキュメントの記述内容を表にマッピングしていく。すると、埋められないセルがあったり、どうも曖昧だぞっていうセルが出てくる。そういう部分は、記述の(あるいは検討の)足りていない箇所だと気づけますね。
もちろんこのガイドをきれいに埋められれば100%の設計、ということにはなりませんが、少なくとも「入出力と、その間の処理」については明確なものになっているわけです。
他のレビューとの関係は?
この後のクロージングで野中誠先生が、「既存のレビュー分類は、実施形態によるものであり、目的志向ではない」という旨のことをおっしゃっていました。おっしゃる通りで、「公式か、非公式か」「記録を取るか、取らないか」みたいな、「やり方」による分類しか、わたしは見たことがありません。
でも本当に必要なのは、「どのレビューが、どういう目的で使えるか」という情報なんですよね。たとえばアジャイル・インスペクションの目的は、ドメインに立ち入る前の、そもそもの書きっぷりをチェックして、「書くこと」そのものの品質を上げようというもの。
でも本当に必要なのは、「どのレビューが、どういう目的で使えるか」という情報なんですよね。たとえばアジャイル・インスペクションの目的は、ドメインに立ち入る前の、そもそもの書きっぷりをチェックして、「書くこと」そのものの品質を上げようというもの。
ガイドに基づくレビュー(Guides Based Review?)は、アジャイル・インスペクションの次にあるレビューとされています。位置づけ上はまだ、ドメインにあまり立ち入らない範囲での品質向上を目的とするものと紹介されました。この後に、チーム内非公式レビュー、そして公式のインスペクション、という流れになります。
もちろん、全範囲×全レビューを求めているわけではありません。アジャイル・インスペクションや、ガイドに基づくレビューによるサンプリングで、ドキュメントとしての品質を上げていく。その後に、非公式レビューと公式インスペクションで、ドメイン依存の部分のみに集中し、設計としての品質を上げていく。こんな流れなんですね。
もちろん、全範囲×全レビューを求めているわけではありません。アジャイル・インスペクションや、ガイドに基づくレビューによるサンプリングで、ドキュメントとしての品質を上げていく。その後に、非公式レビューと公式インスペクションで、ドメイン依存の部分のみに集中し、設計としての品質を上げていく。こんな流れなんですね。
他にどういうガイドがある?
今回紹介されたのは、「入出力」のガイドでした。
設計を整理し、系統的に検証するという意味では、たとえば状態遷移表やデシジョンテーブルもガイドと言えるのではないかと思います。状態遷移表は、ありうる状態と、状態間の遷移をもたらすイベントを網羅的に整理することができる。デシジョンテーブルも、ありうる真偽パターンを洗い出すことができる。
設計を整理し、系統的に検証するという意味では、たとえば状態遷移表やデシジョンテーブルもガイドと言えるのではないかと思います。状態遷移表は、ありうる状態と、状態間の遷移をもたらすイベントを網羅的に整理することができる。デシジョンテーブルも、ありうる真偽パターンを洗い出すことができる。
とはいっても、これらは設計に立ち入った情報を整理するものなので、もう少し手前のものが望ましいですね。
ぱっとは思いつかないのですが、「かつ」「または」といった、論理に関する記述について、何かガイドを設けられないかなーと考えています。
ぱっとは思いつかないのですが、「かつ」「または」といった、論理に関する記述について、何かガイドを設けられないかなーと考えています。
クロージングパネルと、後の祭り
この後、森崎修司先生を含め、登壇者全員によるクロージング・パネルがあったのですが、わたしの腕ではとてもまとめ切れせんので、レビュー祭りのレポートはこの辺で終わりといたします。
感想。
レビューは、テストに比べて理屈が少なく自由度が高く、どうもしっくりこない、「やりきった」感がないという気持ちがありました。が、今回の議論を通じて、レビューもまた、計画や戦略をもって実行できそうだという手応えを覚えました。「1日でレビュー手法を少し進化させる」という祭りのコンセプトを、実感できたように思います。
レビューは、テストに比べて理屈が少なく自由度が高く、どうもしっくりこない、「やりきった」感がないという気持ちがありました。が、今回の議論を通じて、レビューもまた、計画や戦略をもって実行できそうだという手応えを覚えました。「1日でレビュー手法を少し進化させる」という祭りのコンセプトを、実感できたように思います。
閉会の挨拶や懇親会で、登壇者の方々は口々に、「またやりましょう」「次はみなさんが前に」とおっしゃっていました。それを聞いて、「この人たちは、全然指導者気分じゃないんだな。自分たちも学んでいるんだから、教えてくれよ!っていう人たちなんだな」と思いました。
この祭りは、ちょっと信じがたいことに、参加無料。その理由は、「登壇者もまた、学ぶ立場だよ」という志にあるんだろうなと感じて、本当によい祭だなあとしみじみ思ったのでした。
この祭りは、ちょっと信じがたいことに、参加無料。その理由は、「登壇者もまた、学ぶ立場だよ」という志にあるんだろうなと感じて、本当によい祭だなあとしみじみ思ったのでした。
登壇者のみなさん・主催者のみなさん、どうもありがとうございました。来四半期の第002回を楽しみにしております(丸投げ系男子)。
2011年11月07日
第1回レビュー祭で神輿の片棒かついできた - その2
カテゴリ: イベント, SQ3.4-レビューの技法
あっという間に、開催から1週間が経ってしまいました。スピード感のないブログで申し訳ありません。その2では、チェックリストに関するセッション『レビューチェックリスト自慢、っん?』について。
チェックリスト。
この言葉を聞いただけで拒否反応を示す人もいるでしょう。
この言葉を聞いただけで拒否反応を示す人もいるでしょう。
チェックリストの恐ろしいところは、「積極的に削減する理由がない」こと。これを「四次元クローゼットの罠」と呼びます。
ずっと着てもいない服を「破れてはいない」「いつか着るかも知れない」「捨てると後悔するかも知れない」という理由から捨てないのと同様、チェックリストやその項目には、「減らす」動機がない。そして恐ろしいことに、その「着ない服」がいくらあっても、チェックリストというクローゼットは満杯にならんのです。
ずっと着てもいない服を「破れてはいない」「いつか着るかも知れない」「捨てると後悔するかも知れない」という理由から捨てないのと同様、チェックリストやその項目には、「減らす」動機がない。そして恐ろしいことに、その「着ない服」がいくらあっても、チェックリストというクローゼットは満杯にならんのです。
それはさておきこのセッション、まずは野中誠先生、細川宣啓さん、安達賢二さんが順に、チェックリストに対するご自分の考えを述べられた後、野中先生の立ち会いのもとに、細川さんと安達さんが鍔迫り合うという展開になりました。
野中先生のお話
高齢者在宅監視システムの仕様検討不足の事例から、チェックリストのあるべき姿のお話をされました。この事例については、ThinkITにご自身の記事があります。
この事例のシステムでは、「鍵を内側からかけた」「水を使用した」といった日常の行動をイベントとして、「在宅」「不在」の状態を遷移させています。たとえば、「在宅」状態において「外から施錠」すると、「不在」状態に遷移し、係の人は外部から、不在であると判断できます。
この事例に基づいて、野中先生の挙げられたポイントの1つが「安全性」です。
このシステムでは、「不在→在」に比べて「在→不在」の状態遷移が、重大な意味をもっています。なぜなら、「不在」の人に室内で問題が起きることは「ありえない」。よって、安否を確認する側の注意は離れる。
だから、「在を不在にするイベント」はよく吟味して絞り込む必要があるし、逆に「不在を在にするイベント」は間口を広げておかなくてはならない。
もちろん、イベントがどう行われたかをすべて正確に判定することは不可能なので、実際の状態とシステムの「状態」にずれが起こる場合はある。で、それを許容するとして、「観測状態と実状態にズレが生じた場合、fail-safe か」という安全性の観点で、設計を検討することが必要になります。
このシステムでは、「不在→在」に比べて「在→不在」の状態遷移が、重大な意味をもっています。なぜなら、「不在」の人に室内で問題が起きることは「ありえない」。よって、安否を確認する側の注意は離れる。
だから、「在を不在にするイベント」はよく吟味して絞り込む必要があるし、逆に「不在を在にするイベント」は間口を広げておかなくてはならない。
もちろん、イベントがどう行われたかをすべて正確に判定することは不可能なので、実際の状態とシステムの「状態」にずれが起こる場合はある。で、それを許容するとして、「観測状態と実状態にズレが生じた場合、fail-safe か」という安全性の観点で、設計を検討することが必要になります。
この他、「妥当性」「整合性」、さらに「ビジネス価値との整合性」「目的と手段の整合性」などが紹介されました。これらは、チェックリストの項目そのものではなく、項目の分類・切り口と考えた方がよいのでしょうね。
細川さんのお話
細川さんは、チェックリストが単なる責任回避にしか使われていないケースに言及されていました。
何か問題が起きた時に、チェックリストに基づいて作業していないと「なぜ、チェックリストを使わなかったんだ!」という、本質とずれた議論になってしまう。逆にチェックリストをやっておけば「やるべきことはやっていたもんね!人事は尽くしたもんね!」という、これまたよくわからない言い訳の材料に使われる。ということは、ありそう。
何か問題が起きた時に、チェックリストに基づいて作業していないと「なぜ、チェックリストを使わなかったんだ!」という、本質とずれた議論になってしまう。逆にチェックリストをやっておけば「やるべきことはやっていたもんね!人事は尽くしたもんね!」という、これまたよくわからない言い訳の材料に使われる。ということは、ありそう。
結果、「チェックリストってめんどくさいけど、とりあえずチェックしとけばいいんでしょ」と「Just do it.」モードになって、ナイキマークをたくさん書くだけの簡単なお仕事になり下がってしまいますね。
細川さんはこの知的作業を、「カラスを飛ばす」と表現していました。チェックボックスに機械的にレ点を入れていくと、「レレレレレ」とカラスの大群が飛び去る姿になるからだそうで・・・。
細川さんはこの知的作業を、「カラスを飛ばす」と表現していました。チェックボックスに機械的にレ点を入れていくと、「レレレレレ」とカラスの大群が飛び去る姿になるからだそうで・・・。
そんな風になってしまう要因として、チェック項目からドメイン固有の要素を排除することによる、チェックリストの形骸化を挙げられています。またこの排除により汎用性が(見かけ上)上がるため、組織内での適用範囲が広がり、強制力も上がってしまうという問題点を指摘されました。
この他、プロダクトのチェックリストではなくプロセスのチェックリストについて、失敗の確率を下げるためのツールとして役に立つとお話しされています。
この場合の「プロセス」が、プロジェクト全体にまたがるようなプロセスを指すのか、もっと小さな作業を指すのかが、その場では判断できませんでした。わたしは前者はあまり好きじゃありませんが、後者は重要だと思っています。たとえば本番で稼働しているシステムでのプログラム入れ替えといった作業については、チェックリストによって過去の失敗を排除し、手順書の品質をできるだけ一定にして、ミスのリスクを最小化したいものです。
この場合の「プロセス」が、プロジェクト全体にまたがるようなプロセスを指すのか、もっと小さな作業を指すのかが、その場では判断できませんでした。わたしは前者はあまり好きじゃありませんが、後者は重要だと思っています。たとえば本番で稼働しているシステムでのプログラム入れ替えといった作業については、チェックリストによって過去の失敗を排除し、手順書の品質をできるだけ一定にして、ミスのリスクを最小化したいものです。
安達さんのお話
泣けるチェックリスト項目の例を、安達さんが挙げてくださいました。
↓何の意味もない巨大なチェック項目。
↓何の意味もない巨大なチェック項目。
| 問題は残っていないか。 |
↓とても簡単にはカラスを飛ばせない、荘厳な項目。
| 顧客満足を獲得できるか。 |
↓古文書。
| 8inchFDスロットから読み込めるか。 |
安達さんは、チェックリスト、特に他人が作ったチェックリストは使わない!とのこと。
チェックリストは、「過去の事例を形式知化し、組織の財産にする」ということもできます。が、必要条件の羅列でしかないチェックリストを十分条件と勘違いして、「これに従っていればOK(意味はわからないけど)」という、思考停止の受け身な姿勢につながることもある。このマイナス面を、安達さんは嫌っているとのことでした。
チェックリストは、「過去の事例を形式知化し、組織の財産にする」ということもできます。が、必要条件の羅列でしかないチェックリストを十分条件と勘違いして、「これに従っていればOK(意味はわからないけど)」という、思考停止の受け身な姿勢につながることもある。このマイナス面を、安達さんは嫌っているとのことでした。
ただし、レビューをする際の観点は用意しているそうです。たとえば、「利用者の立場で」「作業依頼者の立場で」といった、あるロールに成り代った視点でのレビュー、「青森恐山イタコ法」。
確かに設計書を読む時には、「これ、使い方わかりづらくないか?」「本当にこんなの実装できるの?」「これじゃテスト条件が不明確だ」などと、無意識に様々な立場で眺めています。逆にいうと、視点が安定していない。イタコとして明示的なロールを受け持つことで、効率的にレビューできるように思いました。
確かに設計書を読む時には、「これ、使い方わかりづらくないか?」「本当にこんなの実装できるの?」「これじゃテスト条件が不明確だ」などと、無意識に様々な立場で眺めています。逆にいうと、視点が安定していない。イタコとして明示的なロールを受け持つことで、効率的にレビューできるように思いました。
わたしの考え
これらのお話、およびディスカッションを聴いて、今わたしが考えているチェックリストの方針は、こんな感じでしょうか。
| 具体的な設計方法や事例は、チェックリストにしない。 |
ノウハウとして蓄積すること自体はよくって、教育資料だとか、ディスカッションの材料にするのがいいんじゃないかなと。事例を項目にすると、整理されず無限増殖する。
| チェックに意味のない遠大なチェック項目を作らない |
「問題は残っていないか。」のように、それをチェックすることで何も得られない。そのチェックが意味することが何もないようなリストはご勘弁を。
| ツールにかければ見つかるようなものはチェックリストにしない。 |
静的解析ツールのような、機械でできることは、機械で。
いや全然、目新しい考え方じゃないですね。
2011年11月02日
第1回レビュー祭で神輿の片棒かついできた - その1
カテゴリ: SQ3.4-レビューの技法, イベント
RISING SUN ROCK FESTIVALをご存知でしょうか。
人生で一番音楽を聴いたであろう大学時代に初めて行った野外フェス、それが1999年の RISING SUN ROCK FESTIVALでした。
リンク先でアーティストのラインナップをご覧ください。夜を徹してのこの超絶フェス、よく考えずに占有した陣地の目の前にある巨大スピーカーの爆音の渦の中でわたしは夜中も眠ることができず、「今ならこのギターウルフの演奏で鼓膜が破れてもいい!(治るなら)」と思いました。
人生で一番音楽を聴いたであろう大学時代に初めて行った野外フェス、それが1999年の RISING SUN ROCK FESTIVALでした。
リンク先でアーティストのラインナップをご覧ください。夜を徹してのこの超絶フェス、よく考えずに占有した陣地の目の前にある巨大スピーカーの爆音の渦の中でわたしは夜中も眠ることができず、「今ならこのギターウルフの演奏で鼓膜が破れてもいい!(治るなら)」と思いました。
そのフェスと同じ興奮と感動を与えてくれたのが、10月29日に東洋大学で開催された、「レビュー祭り」でした。いや、言い直しておきましょう。「第1回 レビュー祭り」と。・・・もう一度言い直そう。「第001回 レビュー祭り」、と。
リンク先でアーティスト登壇者のラインナップをご覧ください。ソフトウェア検証周りで働く人にとって、あまりに挑発的なメンツ。「レビュー祀り」といってもいいでしょう。この企画の管理者たるしんすくさんは、裏社会にどれだけのネットワークを持っているのかと・・・。
リンク先で
オープニングで、細谷泰夫さんが宣言されました。
「コーディングやテストと違って、レビューはソフトウェア開発者の誰もが行うもの。レビュー技法の体系化・進化のキッカケを作りたい」
そりゃ、このメンツならできるわ・・・。と、丸投げ心が働いた。
「コーディングやテストと違って、レビューはソフトウェア開発者の誰もが行うもの。レビュー技法の体系化・進化のキッカケを作りたい」
そりゃ、このメンツならできるわ・・・。と、丸投げ心が働いた。
このオープニングに続いて、
|
の3つのテーマが続き、最後にクロージング・パネルという流れ。
内容を少しでもお伝えできればいいのですが、当日すごい勢いで実況中継してくださった kimukou_26さんのtogetterまとめと、当日のエントリなのにクオリティの高い、しんやさんのレポートがありますので、わたしのエントリは蛇足に過ぎないね。
内容を少しでもお伝えできればいいのですが、当日すごい勢いで実況中継してくださった kimukou_26さんのtogetterまとめと、当日のエントリなのにクオリティの高い、しんやさんのレポートがありますので、わたしのエントリは蛇足に過ぎないね。
アジャイル・インスペクション
一体、どんなもの?
実はこれまで、アジャイル・インスペクションとはどういうものかをほとんど知りませんでした。
google先生に尋ねてみると・・・一番最初に、登壇者でもある森崎修司先生の記事がヒットします。で、3つ目にも森崎先生のブログがヒットします。しかも、2〜3年前の記事。自分の知識遅れすぎ。
森崎先生のブログ記事から引用すると、
google先生に尋ねてみると・・・一番最初に、登壇者でもある森崎修司先生の記事がヒットします。で、3つ目にも森崎先生のブログがヒットします。しかも、2〜3年前の記事。自分の知識遅れすぎ。
森崎先生のブログ記事から引用すると、
| 対象ドキュメント全てをレビュー/インスペクションするのではなく、一部を抜き取って実施し、品質(欠陥密度)が目標値になるまで、抜き取り→インスペクション→修正のサイクルを繰り返します。 (中略)通常のレビュー/インスペクションが網羅的な欠陥の指摘と指摘の修正であるのに対して、アジャイルインスペクションでは、一部を対象とする点が異なります。 |
同じ「インスペクション」という言葉がついていても、Fagan Inspectionとはずいぶん異なるようです。
プロジェクト・マネジメント学会での発表によると、日立公共システムエンジニアリング株式会社にも「一人一本目チェック技法」という考え方があります。あまり情報が公開されていませんが、コチラにこのように紹介されています。
| これまでは設計書を「まとめて作成し、まとめてレビューする」プロセスであった。本技法は、担当者ごとの作業における短いサイクルの中で改善を重ねる。これが設計者自らの習熟効果により習熟曲線に沿って不良の作り込みを減らすことができるというものである。 |
本質的には同じ考え方かも知れません。
どんな流れで何をする?
アジャイル・インスペクションの概要の説明と演習は、永田敦さんが担当されました。
アジャイル・インスペクションの流れは以下の通りです。
アジャイル・インスペクションの流れは以下の通りです。
|
ここでいうルールとは、たとえば「曖昧でないこと」。
例文として出された「絶対ドラゴンズに勝ってほしい」。この話者は、果たしてドラゴンズが勝つことを望んでるのか、負けることを望んでいるのか、曖昧ですね。「テストケースは全部できなかった」。曖昧ですね。でも、「すべてのチェックボックスがチェックされていない場合は」って、そう珍しい記述でもないですよね。。。
この「曖昧」の他に、「検証可能であること」「要求仕様に設計要素を書いていないこと」といったルールがあります。
例文として出された「絶対ドラゴンズに勝ってほしい」。この話者は、果たしてドラゴンズが勝つことを望んでるのか、負けることを望んでいるのか、曖昧ですね。「テストケースは全部できなかった」。曖昧ですね。でも、「すべてのチェックボックスがチェックされていない場合は」って、そう珍しい記述でもないですよね。。。
この「曖昧」の他に、「検証可能であること」「要求仕様に設計要素を書いていないこと」といったルールがあります。
そこから、何がわかる?
今回はこの「曖昧」のルールに基づいて、実際のドキュメントを使ったワークショップを行いました。各人が15分間で、4ページ程度(絵入りなので多め)のドキュメントサンプルの欠陥を探す。とりあえず、指摘の中身自体は問いませんでした。
ここで、もう1つのポイント。
ここで、もう1つのポイント。
| レビューしたら、定量的に記録し、計測せよ。 |
永田さんが、アジャイル・インスペクションの提唱者・Tom Gilb氏からもらったという記録用のワークシートにデータを入力。欠陥件数・所要時間・推定検出率などから、サンプリングの母体となるドキュメント全体に残っているであろう欠陥の件数を推定します。この件数から、品質が閾値に達しているかを判断したり、推定される残欠陥が後構成にもたらすであろう損失額を算定したりします。
わたしは、ドキュメントのページ数と欠陥の数を、「欠陥密度」というメトリクスとして管理することがあります。
しかし、たとえば「機能」という単位でそれを分けたとしても、数個から、多くても20。10個くらいの数字をとって何か言えるとしても、せいぜい「ある機能が、他の機能に対して欠陥の密度が低い。おかしいかも?」ということくらい。それはそれで無意味ではないと思いますが、統計的に何かを言える気がしませんでした。
一方、無作為に1ページをサンプリングしてくるアジャイル・インスペクションでは、数を重ねるごとにサンプルの数が増える。また、1ページという細切れであれば、プロジェクトやソフトウェアの特性に、あまり依存しない数字が出そうで、もっとしっかりとしたデータが取れるように思いました。
しかし、たとえば「機能」という単位でそれを分けたとしても、数個から、多くても20。10個くらいの数字をとって何か言えるとしても、せいぜい「ある機能が、他の機能に対して欠陥の密度が低い。おかしいかも?」ということくらい。それはそれで無意味ではないと思いますが、統計的に何かを言える気がしませんでした。
一方、無作為に1ページをサンプリングしてくるアジャイル・インスペクションでは、数を重ねるごとにサンプルの数が増える。また、1ページという細切れであれば、プロジェクトやソフトウェアの特性に、あまり依存しない数字が出そうで、もっとしっかりとしたデータが取れるように思いました。
そのスコープは?
アジャイル・インスペクションの狙いとして注意すべきは、アジャイル・インスペクションですべての種類の欠陥を取ろうとはしていないということです。1ページのサンプリングなのに、周りのページとの整合性、全体としての統一感といった欠陥が見つけられるわけがない。こういう欠陥は狙っていないのですね。
アジャイル・インスペクションで品質を高めるのは、ドキュメントの書きっぷり。共通的な部分。
ドキュメントのフォーマットや内容構成から始まり、曖昧・不明確といった、後の欠陥のリスクにつながるものを繰り返し除去していく。これを、短時間・高頻度で回すことで、書く側の腕も上がる。
全体を俯瞰しての欠陥や、ドメイン・業務要件に依存するような部分の欠陥は、設計工程後半のインスペクションで取り除いていく。その頃には、アジャイル・インスペクション時代に注目していたような「ルール」に抵触するような欠陥は少なくなっているはずなので、本来見るべき場所に注力できる、という仕掛けです。
ドキュメントのフォーマットや内容構成から始まり、曖昧・不明確といった、後の欠陥のリスクにつながるものを繰り返し除去していく。これを、短時間・高頻度で回すことで、書く側の腕も上がる。
全体を俯瞰しての欠陥や、ドメイン・業務要件に依存するような部分の欠陥は、設計工程後半のインスペクションで取り除いていく。その頃には、アジャイル・インスペクション時代に注目していたような「ルール」に抵触するような欠陥は少なくなっているはずなので、本来見るべき場所に注力できる、という仕掛けです。
アジャイル・インスペクションのスコープを、一般的な欠陥に絞る長所として、プロジェクト外の人間や、経験の浅い若手でも参加しやすいという点があります。若手がいきなりレビューの場に放り込まれても、何を指摘していいやらわからない。そこで、「ルール」という明確な観点を与えることで、自信をもって、また集中してレビューに参加することができるんですね。
この後、細谷さんによる事例紹介がありました。現状ではまだ非公開ということで詳しくは書けませんが、アジャイル・インスペクションが日常的な活動になっている様子は、すごい・・・。
自分の仕事に取り入れられるか?
で、これをどのように自分の現場に取り入れるか。
幸い、「ドキュメントを、できたそばから次々にレビューする」に対する抵抗感は、少ないと思います。ただ、「最初のレビューは、一般的な欠陥を見つけるよ。で、後からもう一回、業務や機能に特化した欠陥を見つけるよ」という、二段階の進め方は、場合によっては「ムダ」と判定されかねず、理解されるかどうか。慣れないと、一段階目はとてもまどろっこしい。「機能に関する欠陥を指摘してほしい/したいのに・・・」となりそうです。
「まずは、ドキュメントの品質のベースラインを上げるんだぜ!」ということを繰り返し吹聴して、うまく導入できるか試してみたいです。
幸い、「ドキュメントを、できたそばから次々にレビューする」に対する抵抗感は、少ないと思います。ただ、「最初のレビューは、一般的な欠陥を見つけるよ。で、後からもう一回、業務や機能に特化した欠陥を見つけるよ」という、二段階の進め方は、場合によっては「ムダ」と判定されかねず、理解されるかどうか。慣れないと、一段階目はとてもまどろっこしい。「機能に関する欠陥を指摘してほしい/したいのに・・・」となりそうです。
「まずは、ドキュメントの品質のベースラインを上げるんだぜ!」ということを繰り返し吹聴して、うまく導入できるか試してみたいです。
ちょっと違う話ですが、「誤字・脱字はある程度、勝手に治っていくので、ほっとくこともある」というのも面白いと思いました。誤字や脱字の数を数えて、何か有益な情報が得られるとはあまり思えないので・・・。
次回に続くといいな。
2011年09月18日
SQiPシンポジウム2011に参加した! - その4
カテゴリ: SQ3.4-レビューの技法, SQ3.5-テストの技法
2日目、後半のセッションです。
先進技術の適用
このテーマは、現場の工夫による改善というよりは、大きな一歩を踏み出してみた感のある内容。実験のコストもかかっているだろうなあという内容で、聞く方にとってもありがたい知見です。
このシンポジウムでは、将来きっと役に立つであろうという評価を受けた発表に対して「SQiP Future Award 」が授与されます。わたしはこの「先進技術の適用」スロットの3つ目の、大野さんの発表に投票しました。
このシンポジウムでは、将来きっと役に立つであろうという評価を受けた発表に対して「SQiP Future Award 」が授与されます。わたしはこの「先進技術の適用」スロットの3つ目の、大野さんの発表に投票しました。
B4-1:Webアプリケーション開発における画面仕様書およびテスト仕様書の自動生成手法と開発プロセス改善の提案
早稲田大学の坂本さんの発表です。若さに嫉妬!
端的に言うと、画面モックをマスターとして、画面仕様書とテスト仕様書はそこから抽出しては?という内容です。モックもプロトタイプも、上流工程でお客様との意識合わせをするためなどに使われますが、そのまま作り込みを進めて最終製品になるプロトタイプと違って、モックは使い捨てという位置づけにあります。
端的に言うと、画面モックをマスターとして、画面仕様書とテスト仕様書はそこから抽出しては?という内容です。モックもプロトタイプも、上流工程でお客様との意識合わせをするためなどに使われますが、そのまま作り込みを進めて最終製品になるプロトタイプと違って、モックは使い捨てという位置づけにあります。
このモックを、書き殴りでなく、一定の記法に基づいて記述することで、画面上の各コンポーネントのGUI的な属性、値の制約をソースから抽出することができます。そこからさらに画面仕様書・テスト仕様書も、機械的に生成できる、というアイデアです。
会場からは、「画面仕様書の方をマスタとして、そこから画面やテスト仕様書を生成する方が一般的と思うが、何故モックから生成しようと考えたのか」という質問がありました。わたしも同じ疑問があり、モックと、本来の製品を両方メンテナンスし続けるという運用は難しいと思います。仕様変更のたびに画面ベースでお客様と意識合わせをするので、まず画面から手を入れるんです、というところであれば、可能かも知れません。
わたしからも「画面上の複数の項目が依存関係にある場合をカバーできるか」という質問をしました。たとえばアンケートで「その他」を選ぶと、「理由」欄に何か書け、というようなケースですが、その部分はまだ未検討とのこと。選択肢の内容自体をDBから引いてくるような設計もあるでしょうから、チェックの対象は、クライアント側でチェック処理を実装するような範囲になるかと思います。
今後の研究に期待ですね。
今後の研究に期待ですね。
B4-2:WebシステムにおけるVDM++による設計血管除去効果について
株式会社 NTTデータの田端さんの発表です。
仕様書の曖昧さを排除するために、自然言語ではなく形式手法で記述しようという試みは増えてきているようです。ただ、新しい記法で最初からすべてを書くというのは、どうしても敷居が高い。
この発表では、まずは設計チームが自然言語で外部仕様書を書く。それを専門部隊が、形式仕様記述言語「VDM++」で記述しなおして、欠陥を摘出するという流れになっています。
この発表では、まずは設計チームが自然言語で外部仕様書を書く。それを専門部隊が、形式仕様記述言語「VDM++」で記述しなおして、欠陥を摘出するという流れになっています。
このプロセスで欠陥の除去が期待できるタイミングは以下の3つ。
|
このうち、費用対効果が高いのは、2つ目まで行った場合とのこと。3つ目は完全に、いわゆる「テスト」なので、作るべきものがまたたくさん増えていくんでしょうね。また、形式手法の熟練者であればある程度、記述しながら実際の動作を想定することで欠陥をある程度、先出しできるようです。
B4-3:テキストマイニングを活用したSWプロジェクトの品質管理事例
バグ票の分析に興味のある人にはぜひ、公開されるであろう資料を読んでほしい。NECカシオモバイルコミュニケーションズ 株式会社の大野さんの発表です。
バグ票で利用しやすいのは、たとえば「欠陥の摘出工程」「重要度」のように、分類が用意されていて、それを選択するもの。件数や、全体からの比率など簡単にわかります(正しく分類されていればね・・・)。
一方でなかなか活かせないのが、「現象」「原因」など、各担当者が自由記述で書くところ。本当に大事なことは、こっちに書いてあったりもします。
一方でなかなか活かせないのが、「現象」「原因」など、各担当者が自由記述で書くところ。本当に大事なことは、こっちに書いてあったりもします。
この発表は、テキストマイニングにより自由記述部分を分析し、抽出した単語とその関係から、欠陥の傾向やプログラムの弱点を見出そうというものです。わたしはテキストマイニングの手順について詳しくないのですが、単純に単語を拾うだけではなく、同義語や関係性を定義したり、その関係性をネットワークグラフにしたり、色んなことができると知りました。
この技術を使って、単語の発生頻度の時系列変化から、個々の機能に閉じない全体的な欠陥の収束状況を把握することができるとしています。また、バグ票の他の要素を組み合わせての分析も可能と。
この技術を使って、単語の発生頻度の時系列変化から、個々の機能に閉じない全体的な欠陥の収束状況を把握することができるとしています。また、バグ票の他の要素を組み合わせての分析も可能と。
わたしはこの発表がとても好きで、このような技術が浸透すれば、バグ票の立場が大きく向上するのでは、と期待しています。自由記述が有効に活かされると明らかになれば、書く方もそれを意識するようになるのではないでしょうか。
ちなみにわたしは、バグ票に「タグ」という欄を設けて、似たようなことを手動で行うこともあります。このタグとは、ブログ記事についていたりするものと同じです。1つのバグ票の特徴を表す単語を最大3つくらい書いておく。ここでいう「特徴」は、起こった事象についてでもいいし、その原因でもいい。
これをすべてのバグ票を通して眺めてみて、類似単語を整理したうえで、傾向を見出すということです。この人力データマイニング、異様に泥臭いのですが、品質向上の観点としてけっこう役に立つものです。ただし、疲れる。本当に気合いが必要。
これをすべてのバグ票を通して眺めてみて、類似単語を整理したうえで、傾向を見出すということです。この人力データマイニング、異様に泥臭いのですが、品質向上の観点としてけっこう役に立つものです。ただし、疲れる。本当に気合いが必要。
2011年01月22日
画面遷移の仕様を「画面遷移表」で検算 ─ その3
カテゴリ: SQ3.4-レビューの技法, MS Office
ピボットテーブルを利用した画面遷移の検証についてお話しています。この手法は「トランプ法(TRAMP:Transition Matrix by Pivottable)」といい、我が社では全社的に適用され・・・ているはずもなく、個人的にほそぼそとやってます。名前も今決めました。なお「tramp」を英英辞典で調べると「to travel about on foot」という意味があり、この作業の地味さ加減に合っていますね!
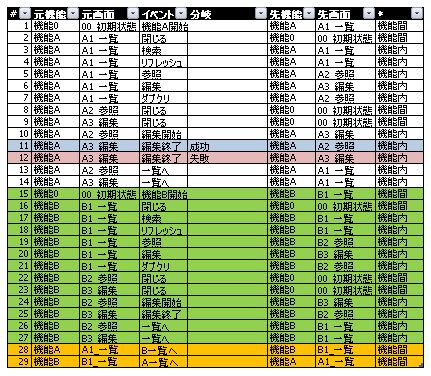
データテーブルの列として、「元機能」「先機能」「*」「分岐」と追加しています。それぞれの意味は以下。
|
データ行として、元あった機能を「機能A」と名づけて、それと似た様な画面遷移をもつ「機能B」を追加(緑色の行)。たとえば、機能Aは社員登録、機能Bは部署登録というイメージですね。さらに「一覧」画面から、機能Aと機能Bを行き来できるようにしているのが、オレンジ色の行。
また条件分岐として、「A3_編集」画面で「編集終了」ボタンを押下した際、問題なければ「A2_参照」へ(青い行)、入力値エラーなどがあれば「A3_編集」に留まる(赤い行)、という遷移分岐にしています。
また条件分岐として、「A3_編集」画面で「編集終了」ボタンを押下した際、問題なければ「A2_参照」へ(青い行)、入力値エラーなどがあれば「A3_編集」に留まる(赤い行)、という遷移分岐にしています。
一気に書いて意味不明かも知れませんが、勢いつけていきます。
条件分岐を表現する
ピボットテーブルの行ラベルに「元画面」「イベント」、列ラベルに「先画面」、値に「データの個数」を設定してください。すると、ピボット遷移表は以下のようになります。※簡単にするため、機能B系の画面は除外してあります。
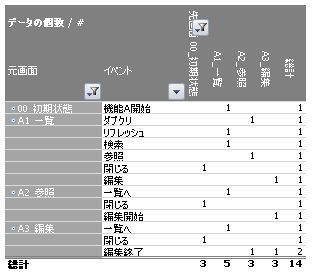
「A3_編集機能」で「編集終了」した際の遷移の「総計」が2。確かに、遷移先が2つあります。ここで行ラベルに「分岐」を追加してもいいのですが、ここでは「編集終了」セルをダブルクリックしてみましょう。すると、フィールドを選択するダイアログが現れますので、「分岐」を選択します。

すると、この「編集終了」にのみ、「分岐」の値が表示されます。
これで「総計が1じゃない問題」が解消されました。また、明示的に「分岐」列が表示されることで、「分岐」に値のないイベントについて「本当にないっけ?」という再考を促します。
これで「総計が1じゃない問題」が解消されました。また、明示的に「分岐」列が表示されることで、「分岐」に値のないイベントについて「本当にないっけ?」という再考を促します。
機能内と機能間でチェックする
今度は、行ラベルを「元機能」「元画面」、列ラベルを「先機能」「先画面」に、値に「データの個数」を設定してください。すると次のようなピボット遷移表になります。
空白セルが多いですね。その2で、遷移漏れのチェックのため空白セルに注目!と書きましたが、大半が空白だとそれはツライ。
この例で、空白はどこに現れているでしょう。よく見ると空白は、機能Aから機能B、あるいは機能Bから機能Aに行くようなセルに多い。機能同士が独立していため、機能間の遷移が少ないということです。
そういうときはまず、機能内に閉じた遷移をチェックしましょう。元・先ともに、機能Bを省いたピボット遷移表が以下です。その2の初めにあるピボット遷移表と、ほとんど変わりませんね。
そういうときはまず、機能内に閉じた遷移をチェックしましょう。元・先ともに、機能Bを省いたピボット遷移表が以下です。その2の初めにあるピボット遷移表と、ほとんど変わりませんね。
各機能内をチェックしたら、次に機能間の遷移を見ます。ここで、先の「*」が使えます。ピボットテーブルのレポートフィルタに「*」を追加し、値として「機能間」を選択してください。これにより、遷移元先と遷移で機能が異なるような遷移のみが現れます。ここで、機能をまたがるような画面間での遷移にのみフォーカスしてチェックを行います。
もっと極端には、上のピボットテーブルから「元画面」「先画面」を外します。するとこう。
2機能しかないと面白みがないですが、画面間の遷移からズームアウトし、機能間の遷移の要否を確認するのに使えますね。
以上、ピボットテーブルをいじくり回して、色んなチェックが簡単にできるのでは?というアイデアの紹介でした。
『ウィリアムのいたずらの開発日記』さんのエントリの通り、画面定義書と画面遷移図の一貫性を保つ方法としては、もっとスマートなやり方がありますね。ピボット遷移表はより地味な、愚直系チェックの際に思い出していただければ・・・というところです。
『ウィリアムのいたずらの開発日記』さんのエントリの通り、画面定義書と画面遷移図の一貫性を保つ方法としては、もっとスマートなやり方がありますね。ピボット遷移表はより地味な、愚直系チェックの際に思い出していただければ・・・というところです。
2011年01月19日
画面遷移の仕様を「画面遷移表」で検算 ─ その2
カテゴリ: SQ3.4-レビューの技法, MS Office
その1では、ピボットテーブルから状態遷移表(以下「ピボット遷移表」)を生成しました。その2では、このピボット遷移表の利用方法を考えてみます。
まず、ピボット遷移表の行ラベルから「イベント」を外してみましょう。すると、「ある画面からある画面への遷移がいくつ存在するか」を表現した表になります。
各セルの数字が、その遷移を起こすイベントの数です。たとえば「A1_一覧」から「A2_参照」への遷移を起こすイベントは、2つあるということになります。数字がない(または0)ならば、遷移がないということですね。
この表では、たとえば次のようなことをチェックできるでしょう。
その遷移はなくて大丈夫?
遷移の仕様を検討するにあたって、「なくてもいいのにある遷移」より、「あるべきなのにない遷移」の方が見つけづらいでしょう。ノードとノードが恣意的に配置される画面遷移図だけでそれを見抜くのは難しいと思いますが、ピボット遷移表では空白セルに注目することでそれがチェックできます。
たとえば上の表では、「A3_編集」と「A3_編集」との交差セルが空白、つまり自分自身に遷移することができません。このことから、「一度編集内容を保存した後、その画面で編集を続ける」といった使い方ができないが、それでいいのか?という気付きに至ります。
たとえば上の表では、「A3_編集」と「A3_編集」との交差セルが空白、つまり自分自身に遷移することができません。このことから、「一度編集内容を保存した後、その画面で編集を続ける」といった使い方ができないが、それでいいのか?という気付きに至ります。
そうはいっても、画面が増えれば、ピボット遷移表は空白セルだらけ。そのセルをすべてチェックするのは相当虚しい作業です。ピボット遷移表の拡張によって、その作業を改善する方法を、次回紹介します。
その画面はスタート?ゴール?
ピボットテーブルで注意しなくてはならないことがあります。それは、データがなければピボットテーブルにも現れないということです。
たとえば「A3_編集」画面から、「A4_袋小路」画面に飛ぶが、「A4_袋小路」からはどこにも行かないものとして、これをデータテーブルに追加すると、ピボット遷移表は以下のようになります。
たとえば「A3_編集」画面から、「A4_袋小路」画面に飛ぶが、「A4_袋小路」からはどこにも行かないものとして、これをデータテーブルに追加すると、ピボット遷移表は以下のようになります。
「A4_袋小路」は、横軸(遷移先)にはあるが縦軸(遷移元)にはありません。この画面が元になるような遷移が存在しないためです。
このように、ピボット遷移表の縦軸・横軸には、すべての画面が現れるとは限りません。
それが気持ち悪ければ、明示的に、イベントと遷移先を「-」などとしたデータを追加しておくとよいでしょう。これにより、その画面は行き止まりであることが明確になります。開始画面についても同様です。
それが気持ち悪ければ、明示的に、イベントと遷移先を「-」などとしたデータを追加しておくとよいでしょう。これにより、その画面は行き止まりであることが明確になります。開始画面についても同様です。
こうしておけば、ピボットテーブルのフィルタを使って、「遷移先が1つもない画面」「遷移元が1つもない画面」を一覧化することができ、それらの画面から/への遷移がなくていいか、ということに注目したチェックができます。
複数遷移していない?
今一度、行ラベルに「イベント」を追加してみましょう。
今度は行の「総計」(一番右の列)に着目します。これは通常1になります。上で述べた通り、0であればそもそも表に現れません。
2以上になるケースとしては、以下が考えられます。
2以上になるケースとしては、以下が考えられます。
|
1.のケースは、総計だけでなく、個別のセルが2以上になっているはずです。データテーブルから重複するデータを消してください。Excel2007以降なら、「重複の削除」という機能を使うと速いですね。
2.のケースは、おめでとうございます。欠陥を検出することができました。どちらかの遷移は誤っているので、検討して設計書にフィードバックしてください。
3.のケースは正直、通常の画面遷移図でもどう表現するべきなのかがわかりません。そんな遷移に出会わないことを祈っています。
4.のケースは、おそらくよくあるものと思います。これはデータテーブルに「条件」列を追加することで解決できます。これについても次回書きます。
2.のケースは、おめでとうございます。欠陥を検出することができました。どちらかの遷移は誤っているので、検討して設計書にフィードバックしてください。
3.のケースは正直、通常の画面遷移図でもどう表現するべきなのかがわかりません。そんな遷移に出会わないことを祈っています。
4.のケースは、おそらくよくあるものと思います。これはデータテーブルに「条件」列を追加することで解決できます。これについても次回書きます。
・・・タイトルは「検算」でしたが、画面遷移図との突き合わせより、仕様検討のネタとしての話ばかりしていることに気付きました。
2011年01月16日
画面遷移の仕様を「画面遷移表」で検算 ─ その1
カテゴリ: SQ3.4-レビューの技法, MS Office
画面遷移図は、画面の遷移を直感的に理解するのにとても役立つドキュメントです。が、画面の遷移に関する情報は、それぞれの画面個別の仕様書にも書かれている。つまり情報が重複しているため、不整合のリスクを常に抱えた不遇のドキュメントでもありますね。
設計段階でその不整合を除去するための「検算」のネタとして、わたしは「画面遷移表」を作ることにしています(*1)。
ここでいう画面遷移表とは、状態遷移図に対する状態遷移表のようなものを意図しています。つまり、2次元マトリクスの縦軸に遷移元画面が、横軸に遷移先画面があり、その遷移を起こすためのイベントが書かれているものです。
ここでいう画面遷移表とは、状態遷移図に対する状態遷移表のようなものを意図しています。つまり、2次元マトリクスの縦軸に遷移元画面が、横軸に遷移先画面があり、その遷移を起こすためのイベントが書かれているものです。
たとえば次の画面遷移図を考えてみましょう。
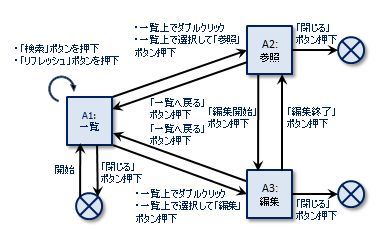
社員のデータの参照や更新をするシステムとしましょうか。
システムを起動すると、社員の一覧画面が出ます。検索を行ってデータを絞り込み、一覧の中から選んだデータを参照。必要に応じて編集モードにして、内容を編集するといったものとします。
システムを起動すると、社員の一覧画面が出ます。検索を行ってデータを絞り込み、一覧の中から選んだデータを参照。必要に応じて編集モードにして、内容を編集するといったものとします。
単純化してたった3画面ですが、イベントは14個あります。実際のシステムでは画面もイベントももっと多いですし、イベントが条件分岐するようなことまで考えると、逆に「よく画面遷移表なんて描けるな・・・狂気の沙汰だ・・・」と思ってしまいます(自動化しているところもあるのでしょうが)。
つまり、画面やイベントの数が多くなると、画面遷移図って絶対間違うだろ、とわたしは思っています。なので、検算のために、別ルートから起こした画面遷移表との突き合わせをしたくなるのです。
つまり、画面やイベントの数が多くなると、画面遷移図って絶対間違うだろ、とわたしは思っています。なので、検算のために、別ルートから起こした画面遷移表との突き合わせをしたくなるのです。
さてその画面遷移表をどう作るか。縦軸と横軸にすべての画面名を書き、各画面の定義書を見ながらセルを1つずつ埋めていくことになるのでしょうか。50画面あったら2,500セル。そんなお絵かきロジックはやっておれぬ。
そこで、Excelマジックを使いましょう。
そこで、Excelマジックを使いましょう。
まずは各画面の画面定義書から、画面遷移に関する情報、つまり「遷移元画面」「イベント」「遷移先画面」の3つを集めます。これはいずれにしても避けられません。イベントと画面遷移の仕様は、定義書内の各地に散らばっているのではなく、1箇所に整理しておくのがよいですよね。
Excel上でこれを1つのデータテーブルにすれば、準備は完了です。例にあげたシステムでは、たとえばこんな感じになります。
Excel上でこれを1つのデータテーブルにすれば、準備は完了です。例にあげたシステムでは、たとえばこんな感じになります。
では、このテーブルからピボットテーブルを作成しましょう。行ラベルに「元」「イベント」をおき、列ラベルに「先」をおいて、値は「データの個数」とします。すると、こんなピボットテーブルができます。これが画面遷移表です。一瞬でできるのがステキです。
次回は、この表を使って何をするのよ?ということを考えてみたいと思います。
(*1) 「画面遷移図と各画面の定義書のうえに、さらにそんなもんを作ったら3管理になって、むしろ状況が悪化するじゃないか!」と怒られそうですが、このデータテーブルは一生メンテし続けることを意図しているわけではなく、設計がおおよそ固まった時点で、おそらく変転してきたであろう画面遷移の仕様に関する記述の整合性が取れていることをチェックするための、補助的な資料と位置づけています。
(*2) このエントリを書くにあたって「画面遷移表」について調べてみたのですが、上のピボットテーブルで作ったようなものを「画面遷移表」と呼んでいる例が見当たりませんでした。ピボットテーブルを作る前身のデータテーブルのことを「画面遷移表」と呼ぶことはあるようです。状態遷移図-状態遷移表のアナロジーから、前者のことを「画面遷移表」と呼びたいものですが・・・。
調べる中で見つけた『WEBシステムにおける画面遷移図表表記法の提案と効果的なテストケースの作成』(主査・秋山浩一氏、副主査・奥村有紀子氏)という論文にある「XSTD表」というものが、わたしのイメージしている「画面遷移表」の表構成です。
調べる中で見つけた『WEBシステムにおける画面遷移図表表記法の提案と効果的なテストケースの作成』(主査・秋山浩一氏、副主査・奥村有紀子氏)という論文にある「XSTD表」というものが、わたしのイメージしている「画面遷移表」の表構成です。