It is no secret that I am a pretty big fan of excellent Linux Software RAID. Creating, assembling and rebuilding small array is fine. But, things started to get nasty when you try to rebuild or re-sync large size array. You may get frustrated when you see it is going to take 22 hours to rebuild the array. You can always increase the speed of Linux Software RAID 0/1/5/6 reconstruction using the following five tips.
Recently, I build a small NAS server running Linux for one my client with 5 x 2TB disks in RAID 6 configuration for all in one backup server for Mac OS X and Windows XP/Vista client computers. Next, I cat /proc/mdstat and it reported that md0 is active and recovery is in progress. The recovery speed was around 4000K/sec and will complete in approximately in 22 hours. I wanted to finish this early.
Tip #1: /proc/sys/dev/raid/{speed_limit_max,speed_limit_min} kernel variables
The /proc/sys/dev/raid/speed_limit_min is config file that reflects the current "goal" rebuild speed for times when non-rebuild activity is current on an array. The speed is in Kibibytes per second (1 kibibyte = 210 bytes = 1024 bytes), and is a per-device rate, not a per-array rate . The default is 1000.
The /proc/sys/dev/raid/speed_limit_max is config file that reflects the current "goal" rebuild speed for times when no non-rebuild activity is current on an array. The default is 100,000.
To see current limits, enter:
# sysctl dev.raid.speed_limit_min
# sysctl dev.raid.speed_limit_max
NOTE: The following hacks are used for recovering Linux software raid, and to increase the speed of RAID rebuilds. Options are good for tweaking rebuilt process and may increase overall system load, high cpu and memory usage.
To increase speed, enter:
echo value > /proc/sys/dev/raid/speed_limit_min
OR
sysctl -w dev.raid.speed_limit_min=value
In this example, set it to 50000 K/Sec, enter:
# echo 50000 > /proc/sys/dev/raid/speed_limit_min
OR
# sysctl -w dev.raid.speed_limit_min=50000
If you want to override the defaults you could add these two lines to /etc/sysctl.conf:
#################NOTE ################ ## You are limited by CPU and memory too # ########################################### dev.raid.speed_limit_min = 50000 ## good for 4-5 disks based array ## dev.raid.speed_limit_max = 2000000 ## good for large 6-12 disks based array ### dev.raid.speed_limit_max = 5000000
Tip #2: Set read-ahead option
Set readahead (in 512-byte sectors) per raid device. The syntax is:
# blockdev --setra 65536 /dev/mdX
## Set read-ahead to 32 MiB ##
# blockdev --setra 65536 /dev/md0
# blockdev --setra 65536 /dev/md1
Tip #3: Set stripe-cache_size for RAID5 or RAID 6
This is only available on RAID5 and RAID6 and boost sync performance by 3-6 times. It records the size (in pages per device) of the stripe cache which is used for synchronising all write operations to the array and all read operations if the array is degraded. The default is 256. Valid values are 17 to 32768. Increasing this number can increase performance in some situations, at some cost in system memory. Note, setting this value too high can result in an "out of memory" condition for the system. Use the following formula:
memory_consumed = system_page_size * nr_disks * stripe_cache_size
To set stripe_cache_size to 16 MiB for /dev/md0, type:
# echo 16384 > /sys/block/md0/md/stripe_cache_size
To set stripe_cache_size to 32 MiB for /dev/md3, type:
# echo 32768 > /sys/block/md3/md/stripe_cache_size
Tip #4: Disable NCQ on all disks
The following will disable NCQ on /dev/sda,/dev/sdb,..,/dev/sde using bash for loop
for i in sd[abcde] do echo 1 > /sys/block/$i/device/queue_depth done
Tip #5: Bitmap Option
Bitmaps optimize rebuild time after a crash, or after removing and re-adding a device. Turn it on by typing the following command:
# mdadm --grow --bitmap=internal /dev/md0
Once array rebuild or fully synced, disable bitmaps:
# mdadm --grow --bitmap=none /dev/md0
Results
My speed went from 4k to 51k:
cat /proc/mdstat
Sample outputs:
Personalities : [linear] [raid0] [raid1] [raid10] [raid6] [raid5] [raid4] [multipath]
md5 : active raid1 sde2[2](S) sdd2[3](S) sdc2[4](S) sdb2[1] sda2[0]
530048 blocks [2/2] [UU]
md0 : active raid6 sde3[4] sdd3[3] sdc3[2] sdb3[1] sda3[0]
5855836800 blocks level 6, 64k chunk, algorithm 2 [5/5] [UUUUU]
[============>........] resync = 61.7% (1205475036/1951945600) finish=242.9min speed=51204K/sec
Monitoring raid rebuilding/recovery process like a pro
You cat /proc/mdstat file. This read-only file contains information about the status of currently running array and shows rebuilding speed:
# cat /proc/mdstat
Alternatively use the watch command to display /proc/mdstat output on screen repeatedly, type:
# watch -n1 cat /proc/mdstat
Sample outputs:

Fig.01: Performance optimization for Linux raid6 for /dev/md2
The following command provide details about /dev/md2 raid arrray including status and health report:
# mdadm --detail /dev/md2Sample outputs:
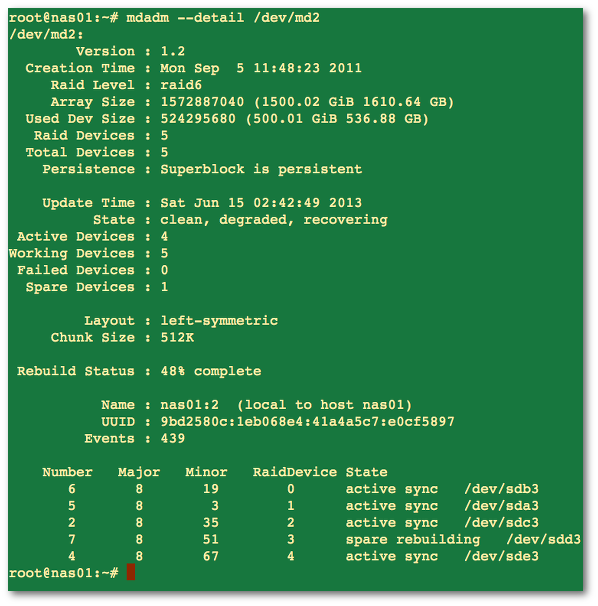
Fig.02: Finding out information about md2 raid array
Another option is to see what is actually happening by typing the following iostat command to see disk utilization:
watch iostat -k 1 2 watch -n1 iostat -k 1 2
Sample outputs:

Fig.03: Find out CPU statistics and input/output statistics for devices and partitions
References:
- 30 Handy Bash Shell Aliases For Linux / Unix / Mac OS X
- Top 30 Nmap Command Examples For Sys/Network Admins
- 25 PHP Security Best Practices For Sys Admins
- 20 Linux System Monitoring Tools Every SysAdmin Should Know
- 20 Linux Server Hardening Security Tips
- Linux: 20 Iptables Examples For New SysAdmins
- Top 20 OpenSSH Server Best Security Practices
- Top 20 Nginx WebServer Best Security Practices
- 20 Examples: Make Sure Unix / Linux Configuration Files Are Free From Syntax Errors
- 15 Greatest Open Source Terminal Applications Of 2012
- My 10 UNIX Command Line Mistakes
- Top 10 Open Source Web-Based Project Management Software
- Top 5 Email Client For Linux, Mac OS X, and Windows Users
- The Novice Guide To Buying A Linux Laptop
{ 37 comments… read them below or add one }
i love your blog, but now i hate you … i added a new drive last week and watched mdadm reshape for ~80hrs … guess it’ll be easier next time. thanks for the tip :P
Heh.. no problem. I’ve updated the post with bitmap option which will increase speed further.
That’s an awesome tip. From my rough calculations I assume it finished in about 1hr 45min. May not be a good thing if you bill your clients per hour :)
Hi there,
this for sure will help a lot when I’ll install our budget backup SAN :-). Do you by any chance also now whether such limits exists for drbd-syncing?
Cheers!
Yes, drbd also suffer from the same issue and can be fixed by editing /etc/drbd.conf. Look out for rate directive:
Another note LVM really slows down performance with drbd; so make sure you avoid it. See this help page [drbd.org].
I always faced this speed problem and I thought this is due to software issue. With this tip I reduced my build time from 9.2 hours to less than 1 hour.
One of my machines has 5x 2TB in a RAID5. I got even more speed out of my volume after tweaking the drives and the md0 volume itself.
—BEGIN—
—END—
Thanks for sharing your script.
One more question on the software raid possibilities:
with a hardware raid, when one disk dies, you can still boot the machine. I had achieved the same for RAID-1 with info found on the net, but how does one goes to achieve the same for a 6 disk RAID-5 setup? I can’t find that info…. Any suggestions or links?
One possible solution I came up with (but I’m not too keen on using it) would be to install the system to an USB drive/stick (of which one can easily make backups, or even use 2 usb devices in RAID-1) and keep the 6 drives as pure data-disks (no OS) in RAID 5.
Thanks in advance
You could split the disks into two partitions, a small 100M partition, and a data partition which uses the rest of the disk. Set up two raid volumes. The small partitions would be raid1, and the rest raid5/6 whatever. install everything on the raid6 volume and mount the raid1 as /boot. Setup grub for each disk:
root (hd0,0)
setup (hd0)
root (hd1,0)
setup (hd1)
…etc.
In this way, any drive could be removed and you could still boot the machine.
Hi Cr0t,
on which hardware specs reliy your setra and read_ahead_kb values?
i got WD20EARS with 64mb memory.
so is it save/usefull to increase your values?
Best practice values ? limits?
thanx ;)
The easiest solution I found was to combine raid 1 (for booting the system) & raid 5 (for data) on the same six disks. Agreed, I now have a 6 disk raid 1, but it is only 2GB. The rest is raid 5. Hopes this helps someone facing the same problems sometimes.
Cheers, Jord
A suggestion, boot from a pendrive.
I just leave a pendrive in a usb port and boot from that as there isn’t any space for more drives.
Had some problems installing Fedora 12 some months ago using the onboard fakeraid and locking up, so reinstalled as standalone drives and mdadm.
I wanted to make a kickass colocated web/mysql server and I’m still soaking it, but I’m worried that resyncing may cause performance issues at critical times, as I have seen while developing.
(it’s now part of a 3-node multiple master mysql cluster+slave experiment, with one node at the ISP linked to here at home over 30mbps / ssh tunnels) :-)
My setup:
RAID10, persistent superblock (host i7/920 + 12Gb RAM)
|=========md0========|====md1====| /dev/sda 1Tb
|=========md0========|====md1====| /dev/sdb 1Tb
|=========md0========|====md1====| /dev/sdc 1Tb
|=========md0========|====md1====| /dev/sdd 1Tb
|=========md0========| /dev/sde 750Gb
|=========md0========| /dev/sdf 750Gb
|======| /dev/sdg 2x250Gb (HW raid1)
|=| /dev/sdh 1Gb pendrive /boot
So can you add the intent bitmap during a RAID 5 reshape? That would really help me out…
Definitely should have looked at this before. Great blog post, man.
When I run sudo mdadm –grow –bitmap=internal /dev/md1
I get:
mdadm: failed to set internal bitmap.
The RAID is rebuilding when I ran this. Do I need to do this before I rebuild? If so, how??
md1 : active raid5 sde[4] sdf[2] sdg[3] sdd[1] sdb[0]
5860543488 blocks super 0.91 level 5, 4k chunk, algorithm 2 [5/5] [UUUUU]
[=>...................] reshape = 8.2% (161204840/1953514496) finish=1231.1min speed=24262K/sec
No change in speed.
You can use –bitmap=internal with create/build/assemble.
Setting the speed limits didn’t help in my case.
I have raid6 with 6xwd20ears, with 0xfb partitions (4kb physical 4kb logical, aligned).
Resync speed after setting up the array is around 20000kb/s, I assume it will get even slower towards the end of the process.
Maybe it would be faster with AAM set to 255 (now set to 128), unfortunatly I cannot set it through my raid controller (only works if the drive is plugged in on the mainboard sata controller).
I’m also not able to set the bitmap, but i think it would not affect the initial resync after having just built the array, am I right?
I would also be interested in further information about setting read ahead etc.
edit:
Sometimes the speed is rising from 20000k to 100000k for a few seconds or minutes and then falling back to 20. I have no explanation for that behaviour.
Except for the resync the system is idle.
md0_raid6 is using about 5% while speed ist 20000k, 25% while speed ist 100000k
md0_resync is using a few percent at 20000k, 20% at 100000k.
Just in this moment the speed went up to 100000k for only 10 seconds… no clue.
Sounds like the RAID setup can do 100 MB/sec, but you have changed the /proc/sys/dev/raid/speed_limit_max setting only, this is used if there is no other activity on the disks at all. SO the rise to 100MB/sec is wen no other I/O activity happens. Try changing /proc/sys/dev/raid/speed_limit_min
then see what happens.
just for sharing : replacing a failed drive , 2TB caviar black – WD2002FAEX, 3 good drives + 1 new on a production server (still gets 100Mbs trafic out )
[>....................] recovery = 2.8% (56272128/1942250240) finish=888.0min speed=35394K/sec
The drives ar having a 92% busy
DSK | sda | busy 92%
—-total-cpu-usage—- -dsk/total- -net/total- —paging– —system–
usr sys idl wai hiq siq| read writ| recv send| in out | int csw
6 6 83 3 0 2| 107M 51M| 0 0 | 5.6B 44B|8900 14k
1 10 72 14 0 3| 363M 150M|8421k 23M| 0 0 |9330 11k
7 12 63 14 1 4| 416M 150M|8009k 25M| 0 0 |9804 12k
won’t push the speed limit to keep the server responsive.
ps: careful running “magic” scripts with “magic” settings. got my server (colocated) frozen while changing some readhead values “on the fly”. Costed me 30$ extra intervention to the colo guys to reboot it (it was on weekend :)) .
Can be fun tweaking but really there’s no silver bullet that comes without some risks. For oldies : there were times when computers came with a Turbo button. If you’d press it the cpu frequency would get higher. Of course 50% of the time Duke Nukem would freeze if you press the turbo button while playing:)
Thanks to this article and the comments on tweaking the drive parameters from Cr0t, rebuild performance on RAID1 went from 32K to over 110K during system idle. The combination of increasing the dev.raid.speed_limit_min to 50000 and disabling NCQ on both drives gave a phenomenal increase in performance. After seeing how much disabling NCQ helped, I further increased dev.raid.speed_limit_min to 110000 to further speed up the rebuild. The rebuild went from an initial estimate of 6 hours, to only taking about 1.5 hours after these tweaks.
Also, thanks to Cr0t!! sped up my raid build from about 28-30K/sec to 40-45K/sec, topping out over 50K occasionally. recognize what you are doing issuing those commands, which is tuning the hard drive parameters that deal with pretty low-level communication options of the device. options tied to the drivers, firmware and kernel. so, use them with care, and don’t be surprised if extreme circumstances cause a lock-up or other failure case causing you to have to start your raid rebuild over. point being, use with caution and in experimental environment as mentioned. still, this did not cause any issues with my setup even doing it during the build, and in most cases on properly working hardware it should not. but be warned!
anywho, the original problem for me turned out to be one bad hard drive causing the array to be built at <1K/sec. sad thing is that nothing about the system or even smartctl really indicated errors. it was really diagnosed by noticing the smartctl 'remap' value skyrocketing on one device where it was not on any of the others, and physically looking at the box showed 10x more LED activity on the problematic disk as it tried every read and write vs the other 19 in the array. so, don't rely on your os to inform you of hard drive issues and you can't rely on SMART at face value either. i think any experienced sys-admin would validate that statement.
happy tuning everyone =) thanks for the info.
Thank you. You saved me tonnes of hours.
There is no reason to turn bitmaps off (unless you need to grow the array), in fact, the whole point to bitmaps is to leave them on so only the unsynced parts of the device (as indicated by the bitmap) need to be rebuilt when a crash or other unclean shutdown occurs. Turn them on when you first make the raid and leave them on.
Also you can’t turn them on during a resync anyways.
Thanks for the tips, and thanks to Cr0t for sharing his script.
Speed went from 26M/sec to 140M/sec
I did
But Didn´t work :/
The speed_min is 50000 and the speed on process continues 1000kb/s
Further to Cr0t’s script…
A little clean up + added lines to set speed max/min
NOTE: only edit the lines at the beginning
— begin script —
#!/bin/bash ### EDIT THESE LINES ONLY RAID_NAME="md0" # devices seperated by spaces i.e. "a b c d..." between "(" and ")" RAID_DRIVES=(b c d e f g) # this should be changed to match above line blockdev --setra 16384 /dev/sd[bcdefg] SPEED_MIN=50000 SPEED_MAX=200000 ### DO NOT EDIT THE LINES BELOW echo $SPEED_MIN > /proc/sys/dev/raid/speed_limit_min echo $SPEED_MAX > /proc/sys/dev/raid/speed_limit_max # looping though drives that make up raid -> /dev/sda,/dev/sdb... for index in "${RAID_DRIVES[@]}" do echo 1024 > /sys/block/sd${index}/queue/read_ahead_kb echo 256 > /sys/block/sd${index}/queue/nr_request # Disabling NCQ on all disks... echo 1 > /sys/block/sd${index}/device/queue_depth done # Set read-ahead. echo "Setting read-ahead to 64 MiB for /dev/${RAID_NAME}" blockdev --setra 65536 /dev/${RAID_NAME} # Set stripe-cache_size echo "Setting stripe_cache_size to 16 MiB for /dev/${RAID_NAME}" echo 16384 > /sys/block/${RAID_NAME}/md/stripe_cache_size echo 8192 > /sys/block/${RAID_NAME}/md/stripe_cache_active— end script —
@fuzzy,
Nice update. One suggestion, you can accept md0 (or md1) and SPEED_MIN and
SPEED_MAX using command line args:
#!/bin/bash ### EDIT THESE LINES ONLY RAID_NAME="${1:-md0}" # devices seperated by spaces i.e. "a b c d..." between "(" and ")" RAID_DRIVES=(b c d e f g) # this should be changed to match above line blockdev --setra 16384 /dev/sd[bcdefg] SPEED_MIN=${2:-50000} SPEED_MAX=${3:-200000} # reset is same as posted by fuzzyOne can run it as:
I have raid5 with 5 wd20ears. Before this script:
echo 50000 > /proc/sys/dev/raid/speed_limit_min
I had rebuilding speeds of around 15000K/sec. After running that script I have 55000-70000K/sec, but somehow after the rebuilding was running couple of hours it slowed down again to the original speed of 15000K/sec…
When I query the speed with this command: ” sysctl dev.raid.speed_limit_min “, it still shows ” dev.raid.speed_limit_min = 50000 “, but it just slowed down to an average speed of 15000K/sec.
What happened? What can I do? Please help me in this issue.
Just wanted to add, that if the sync is going when you change these values, it won’t (or at least didn’t for me) make a diff. So, you can bounce the machine OR do this which causes the resync to restart.
echo “idle” > /sys/block/md0/md/sync_action
And changing this value really kicks the resync into overdrive…
echo [size val] > /sys/block/md1/md/stripe_cache_size
Let me add aswell, I’ve been running a raid6 for a few months, and done quite a few rebuilds, and often it fails during rebuild, but having it rebuild at slower speeds gives me more data security… just my 2 cents
Great post – thanks
I have 2 x 16GB USB thumb drives with CentOS software RAID level 1 operating 5 x 2TB software RAID level 5 with hot spare which offers 6TB iSCSI target to the network. My poor man’s SAN :)
If your RAID rebuild is only running at the min speed, it could be because you have just created an ext4 filesystem and it is doing background initialisation (look for a process called “ext4lazyinit”). When that completes, as long as there’s no other disk I/O going on, the RAID rebuild should crank up to the max speed.
Once the rebuild is complete do recommend changing any of these values back to something or leaving them as is? If you recommend changing them, what would recommend they be changed to?
Examples of changed values:
echo 1024 > /sys/block/sd${index}/queue/read_ahead_kb
echo 256 > /sys/block/sd${index}/queue/nr_request
echo 1 > /sys/block/sd${index}/device/queue_depth
Thoughts?
These steps helped a great deal, improving resync performance of my RAID-5 array with 4x WD20EARX drives from 15MB/s to 45MB/s on a dual-core hyperthreaded atom-d525. Didn’t realize the NCQ settings had such a big impact, improving performance by 200%, while the stripe-cache-size improved performance by around 25%.
I have made a script that saves current values so you can restore them later, before setting the high performance values. It will also detect the underlying disks to set the NCQ for you, along with the read-ahead and sync_speed values. I left out the setting of the bitmap as this can only be done while not syncing, so wasn’t useful to me.
The script can be found at https://gist.github.com/jinnko/6209899.
On a Synology Rackstation, I increased an ongoing RAID5 rebuild speed from 10 MB/s to 20-30 MB/s by increasing
sysctl -w dev.raid.speed_limit_min=100000
(default was 10,000)
without significant CPU load increase.
I wonder if I could set the stripe-cache_size during the rebuild or if I should/must wait till it’s over?