シェルソートとは
| 種別 | 挿入ソート |
|---|---|
| 内部ソート | YES |
| 安定 | NO |
| オンライン | NO |
| 最悪計算時間 | |
| 平均計算時間 | |
| 最良計算時間 | |
| 空間計算量 |
挿入ソートを改良して高速化したアルゴリズムがシェルソートです。 Donald L Shellが1959年に提案した方法で、当時は最速のソートアルゴリズムでした。
シェルソートは今までに紹介した とは異なり、
なので、比較的高速なアルゴリズムです。しかも最良計算時間は
ですから、悪くない方法です。
アルゴリズム
前述のように、シェルソートは挿入ソートの改良アルゴリズムです。 挿入ソートでは、最悪の場合は常に挿入ソートはほとんどソート済みのデータに対しては高速なのですが、乱雑に並んでいたり、逆順にソートされているデータに対しては比較回数(交換回数も)が多くなってしまいます。
もし、ソート中にデータ列をたとえ大雑把であっても「ソート済みに近い状態」に少しずつ持っていくことが出来れば、 ソート処理を進めるに従ってだんだん挿入ソートに有利なデータの並びになると考えられます。 そのため、多少手間をかけても最終的に高速処理できるようになれば、全体としての時間は短くなるかもしれません。 この考えを利用したのがシェルソートです。
以下のようなデータをシェルソートで昇順に並び替えることを考えてみましょう。
| 9 | 5 | 7 | 8 | 2 | 3 | 1 | 4 | 6 |
シェルソートでは変数hが重要なパラメータとなります。 hの初期値についてはあとで詳しく触れるとして、まずはh=4とします。 次に、データをh個おきに取り出して新しいデータ列を考えます。
| 9 | 2 | 6 |
| 5 | 3 |
| 7 | 1 |
| 8 | 4 |
データをh(=4)個おきに取り出して新しいデータ列を4つ作りました。 この4つのデータ列に対して別々に挿入ソートを行ないます。 挿入ソート適用後が次の図になります。
| 2 | 6 | 9 |
| 3 | 5 |
| 1 | 7 |
| 4 | 8 |
このデータ列を初期状態と同じ順番でまた1つのデータとして見てみましょう。
| 2 | 3 | 1 | 4 | 6 | 5 | 7 | 8 | 9 |
結局、上のようなデータになりました。 まだまだ整列されていませんが、初期状態と比べると少しだけ「整列済みデータに近い」状態になっているのがわかるでしょうか。
次にhを半分に減らします。先程はh=4だったので、h=2にして2個おきにデータを取り出します。
| 2 | 1 | 6 | 7 | 9 |
| 3 | 4 | 5 | 8 |
| 1 | 2 | 6 | 7 | 9 |
| 3 | 4 | 5 | 8 |
1度しか交換が行われなかったことに注目してください。 1度目のソートでデータの並びがソート済みの状態に近くなっていたため、交換回数が減ったのです。 また2つのデータ列を統合してみましょう。
| 1 | 3 | 2 | 4 | 6 | 5 | 7 | 8 | 9 |
ほとんどソート済みのデータになっています。
またhを半分にします。先程はh=2だったので、h=1として1個おきにデータを取り出して挿入ソートします。 つまり普通の挿入ソートと同じです。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
たった2回の交換でソートが終わりました。 このように、数個おきに挿入ソートを適用することで、ソート済みの状態にどんどん近づいていくため、非常に高速にソートできます。
h(gap)の値
シェルソートではhの初期値をどのような値にするか,hをどのように減少させるかがポイントです。 基本的には1から順番に3倍して1を足した値にすると良いとされています。 n以上のhを設定しても意味がないので、結局初期値hは次の条件を満たす最大の数にします。 この数列は
と増加していきます。 減らすときはこの逆に減らしていくのが良いhのとりかたです。 100個の要素をソートする場合は、h=364が初期値です。 その後は121, 40, 13, 4, 1と減らしていく方法が比較的高速です。 これはKnuthが提案した方法です。他にも次のようなhのとりかたが知られています。
Shellの方法(オリジナル)
Hibbardの方法
Knuthの方法
もう一つシェルソートにはおもしろい性質があります。 たとえば、h=aでソートしたあと、h=bでソートしたとします。 このときのデータ列は、a ≥ bであればどのような値でも、h=aでソート、h=bでソートの両方の性質を満たしています。 つまり、hは減少さえすれば(そして最終的に1になれば)、どのような値にしてもそれまでのソート結果を破壊しません。
もちろん、h=1のときは通常の単純挿入ソートになりますから、もっといえばhが最後に1になればどのようなhをとってもソート可能です。
時間計算量
シェルソートは平均計算量を求めるのが難しいアルゴリズムです。データの並び方やhのとりかたで比較回数が大きく変化することが原因です。 大雑把にいって、 よりは遅くて
より少し早いと予想できますね。
シェルソートは色々解析されているのですが、 平均計算量はKnuthの方法でhをとった場合,大体 と言われています。 Hibbardの方法だと
なので、Knuthの方法のほうが少し早いことがわかります。
最良計算時間は で、 最悪計算時間は
くらいです。
空間計算量
アルゴリズムの説明を読むと外部メモリが必要かと思われるかもしれませんが、シェルソートは内部ソートです。 空間計算量はシェルソートはどれくらい早いか?
シェルソートは実はなかなか優れたアルゴリズムです。 下の図を見てください。

緑の線と青い線がシェルソートの計算量です。 赤線はクイックソートやマージソート、ヒープソートなどの のアルゴリズムの計算量ですが、要素が数十万程度ならあまり計算量は変わらないことが分かります(とはいえ遅いのですが)。 バブルソートなどのアルゴリズムは紫の線で示しています。
のアルゴリズムと比較するとずっと早いことがわかります。
この図を拡大したものが次の図です。
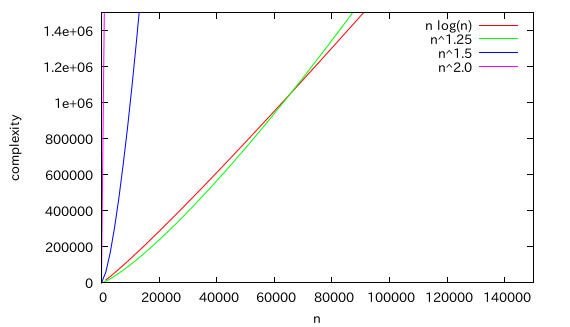
実は要素数が少ないときは、シェルソートのほうが平均計算量は少ないのです。 図ではn=60000くらいのときに逆転しています。 もっともこれはあくまでもO表記での話なので、要素数が6万以下だったらシェルソートのほうが優れているというわけではありません。
ただしヒープソートやクイックソートはオーバーヘッドが大きいので、要素数が非常に少ないときは のアルゴリズムの方が高速な場合があります。 極端に要素数が少ない場合は、たまたまソート済み、あるいはそれに近い並びになっていることがあるので、そのような場合には 最良計算時間が
のアルゴリズム、たとえばバブルソートや挿入ソートを選択するのも悪くありません。
まとめ
シェルソートはデータの並び方にかなり左右されるのですが、ほとんどのデータに対してなかなか高速です。 実際、 のアルゴリズムが発見されるまでは、しばらくの間最速のソート法でした。
シェルソートは平均計算量が なので、
のソート法よりは遅くなります。しかしnが十分に大きければあまり変わりません。 もっとも、実用的にはクイックソートがよく利用されています。