本日は、弊社で利用しているPostgreSQLのバックアップ取得方法についてご紹介します。
弊社は、データベースにPostgreSQL8.4系を利用しています。
定期的なバックアップとして一般的なpg_dumpも利用していますが、
データベース容量が数100GBになると数時間バックアップ時間を要してしまいます。
通常はこのバックアップ時間でも問題ありませんが、サービスの運用上この時間を許容できないシーンがありました。
バージョンアップの作業時間を短縮することが目的
弊社では、3ヶ月に1回提供アプリケーションのバージョンアップが行われます。
その際に、作業内容によってはデータベースの変更が行われます。
万が一、作業で問題があった場合は作業前の状態にロールバックする必要があります。
そのため、メンテナンス画面を表示し、リクエストの遮断した後にデータベースのバックアップを取得します。
しかし、バックアップに数時間を要してしまうとメンテナンスによる停止時間が大幅に増加してしまいます。この時間を削減するために運用を開始したのが、今回ご紹介するバックアップ取得方法です。

元々、冗長化のためにPITRを利用したレプリケーションを利用していました。
PITRについての詳しい解説はこちらが参考になります。
http://www.postgresql.jp/document/current/html/continuous-archiving.html
(PostgreSQLマニュアル 継続的アーカイブとポイントインタイムリカバリ)
http://lets.postgresql.jp/documents/technical/backup/3
(Let's PostgreSQL 物理バックアップの概要)
簡易イメージだとこんな感じです。
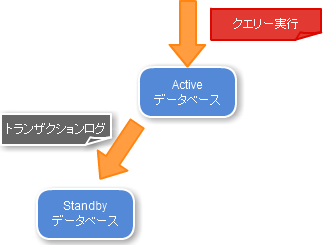
このような形で、アーカイブログ単位で待機系サーバのデータベースを更新しています。
完全な同期型ではありませんが、ほぼリアルタイムにデータはレプリケーションされていますので
Activeサーバが停止した場合は、Standbyサーバに変更するだけでサービスを再開できます。
ファイルシステムのスナップショットの仕組みを参考に
短時間のバックアップが目的でしたので、試行錯誤の結果ファイルシステムのスナップショットの仕組みに注目しました。そして、それをPITRを利用して再現することでデータベース版のスナップショットにしたのが下記のイメージ図です。
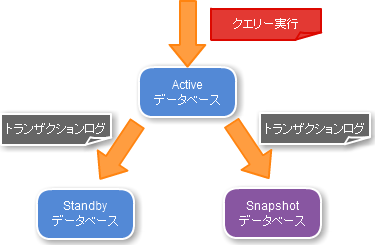
このように、PITRをStandbyサーバだけでなく、3台でレプリケーションさせてしまいバージョンアップなどメンテナンス作業前に分離することで、瞬時にバックアップを取ることできると考えました。
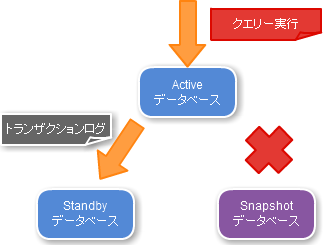
こうすることで、Snapshotサーバは切り離した時点のデータ状態のまま維持されますので万が一メンテナンス作業を中断し全て元に戻す必要がある場合はSnapshotをActiveのデータベースとして利用すれば良いわけです。
(社内では、元になったアイデアからSnapshotサーバと呼んでいます)
この仕組みを採用し、開始当時で3から4時間メンテナンスによってサービスが停止する時間を短縮することができるようになりました。
このデータベーススナップショットの仕組みは、このような課題があれば有効です。
- データベースサイズが大きくpg_dumpではある程度時間がかかる
- 短時間にデータベースのバックアップを取得する瞬間がある
- 世代バックアップである必要が無い
- 構築コストをできるだけかけないようにしたい(OSSのみで実現したい)
当然ですが、デメリットもあります。
- 一度止めたSnapshotサーバを再びレプリケーションに復帰させるのには時間がかかる
構築方法は通常のPITRに追加して3つだけ
【アーカイブログを共有する】
弊社では、Activeのデータベースサーバーが各Standby(Snapshot)サーバをNFSでマウントしログを書き込んでいます。
マウントのイメージ
XXX.XXX.XXX.XXX:/var/lib/pgsql/nfs/archive_log/standby-server/
***G ***G ***G **% /var/lib/pgsql/nfs/archive_log/standby-server/
XXX.XXX.XXX.XXX:/var/lib/pgsql/nfs/archive_log/snapshot-server/
***G ***G ***G **% /var/lib/pgsql/nfs/archive_log/snapshot-server/
【アーカイブコマンドでスクリプトを使う】
postgresql.conf
archive_command = '/home/public/tools/archive_copy.sh %p %f </dev/null'
【スクリプトでアーカイブログを2箇所に保存する】
※スクリプトの例
/home/public/tools/archive_copy.sh
#!/bin/bash basefilename=$1; copy2filename=$2; copy2path1='/var/lib/pgsql/nfs/archive_log/standby-server/'; copy2path2='/var/lib/pgsql/nfs/archive_log/snapshot-server/'; cp -i $basefilename "$copy2path1/$copy2filename"; cp -i $basefilename "$copy2path2/$copy2filename";
この3つの作業を行うことで、アーカイブログが各Standbyサーバ、Snapshotサーバに転送され
復元され続けますので非同期ではありますがデータベースをレプリケーションできます。
後は、必要に応じてSnapshotサーバのアーカイブログの読み込みを止め、PostgreSQLを起動してしまえばその時点のデータを分離させることができます。
弊社では、アーカイブログの読み込みにpg_standbyを利用していますので、トリガーファイルを特定の場所に設置するだけで読み込みが停止されます。
0 コメント:
コメントを投稿