これは Google Cloud Platform Advent Calendar 2015の19日目の記事です。
そろそろGoogleに入って1年が経ちます。ペースが速くて、あっという間に2015年が終わった。Developer Advocate というエバンジェリストのような、エバンジェリストじゃないような仕事をしています。僕は今年の5月にbetaとして公開した Cloud Bigtableのリリース支援をしています。Cloud Bigtable というのは、Googleの有名な大規模分散データベースのBigtableをGoogleの開発者以外でも使えるようにした大きなサービス。Googleのサービス、検索、Maps、Gmailなど、ほとんどのサービスはBigtableが支えています。
Bigtableは分散データベースでスケーラービリティが高いということは分かりやすいけど、どんだけスケールするのかがGoogle外では未だにあんまり知られていないと思います。Googleの検索インデクスは 100,000,000 Gb 以上の容量を持つ。それは 100 Petabyte ですよ。しかも実の数字はこれよりかなり大きい(何倍か)。これは公開されている保守的な数字に過ぎない。
Bigtableは社内で10年くらい使っている。2006年にBigtableのホワイトペーパーを公開して、Bigtableの設計について書いた。著者のリストはレジェンドの開発者Jeff Dean, Sanjay Ghemawat, Andrew Fikes など、同じ会社に勤めていると思えない超人の並び。Googleが出したホワイトペーパーからオープンソースのBigDataエコシステムが生まれた。MapReduceを実装するHadoopや、GFS(Google File System)をインスパイアしたHDFSがIT産業を変えた。Bigtableの設計を元にしたHBaseも利用者を集めた。
Bigtableのパフォーマンス
Googleでは検索結果をものすごい速いスピードで返さないといけない。Bigtableが遅いとGoogleはお金いくら損しちゃうのかな (1時間で検索結果が1秒遅くなったら、私の1年分の給料がぶっ飛んでしまうのが想像できます)
そのため、Bigtableはかなり効率化しています。Bigtableクラスターと同じリージョンにあるGCEのインスタンスから書き込みも、読み込みも、せいぜい10ms以内に返ってくる。これは速い。しかも、p99です (99%のリクエストは10ms以内に返ってくる)。とんでもない速い。しかも、これはクライアントから計測したレイテンシーで、ネットワーク通信も含まれている。サーバーから計測すると6msになる。
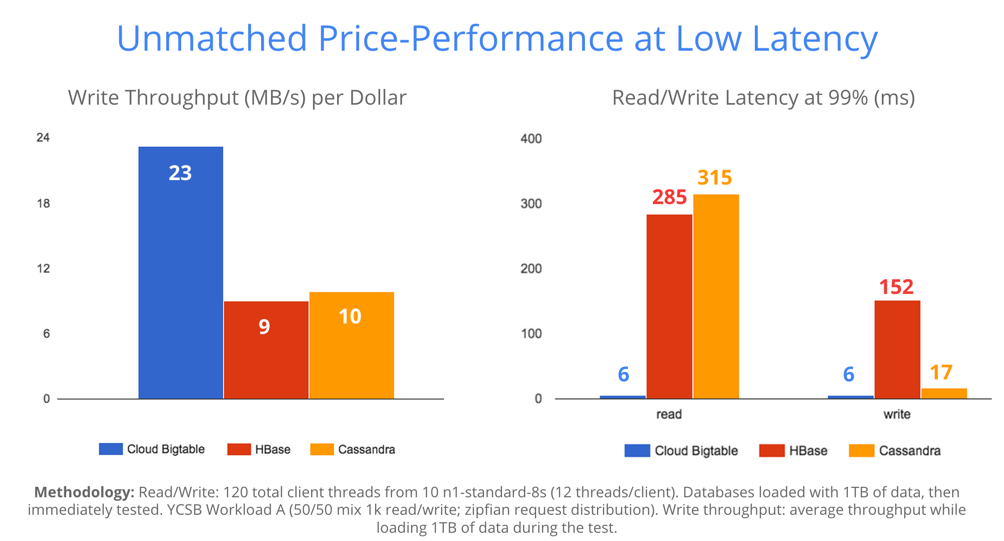
コストパーも高い。書き込みスループットで考えると MB/$ はHBaseやCassandraより倍以上高い。
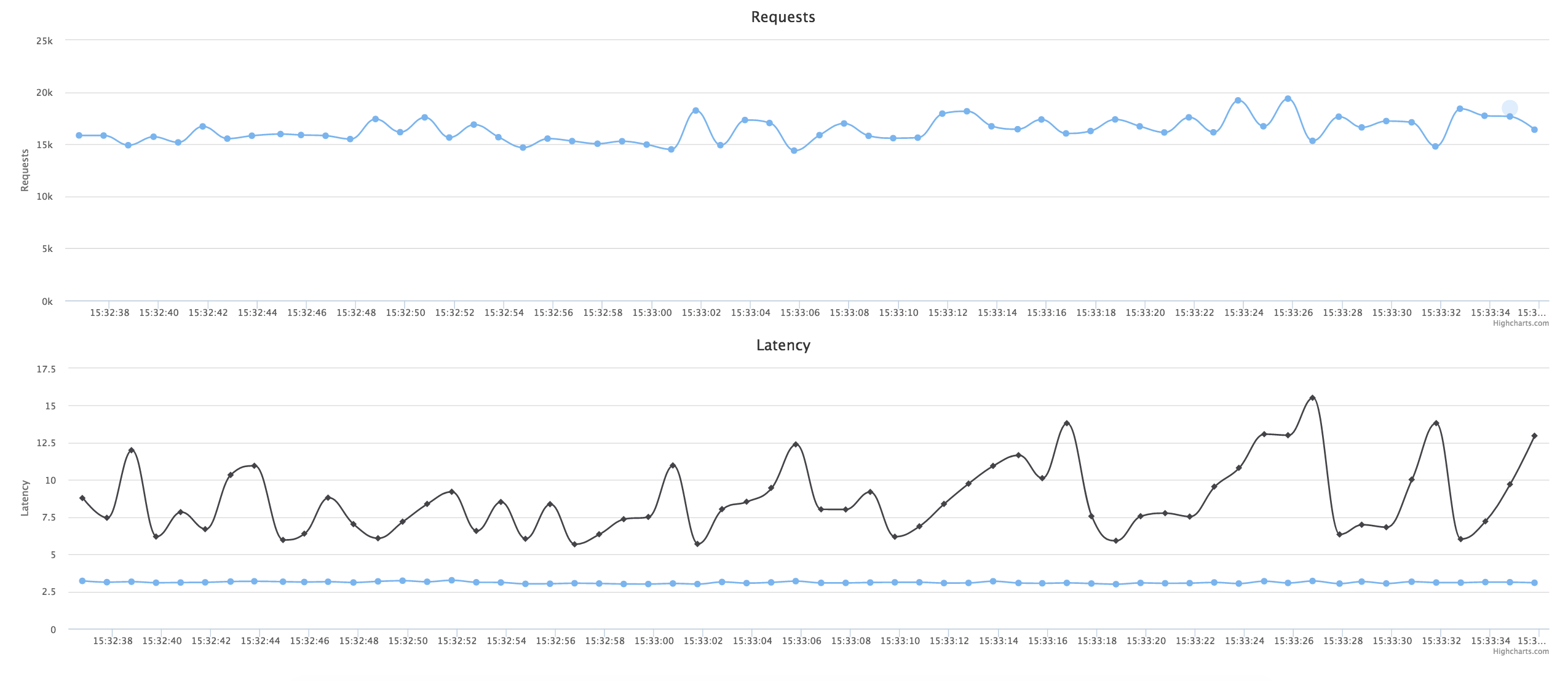
ちなみに、僕が作ったリアルタイムでパフォーマンスを見るデモアプリのイメージです。リクエスト数と書き込み時間が見えますが、これは1.5万 QPSをしながら、上に書いた通り、レイテンシーのp99が大体10ms以内 (上のグラフはQPS, 下のクラフは p50 と p99レイテンシー)。
Bigtableの設計
BigtableはNoSQLの概念を人気にさせたと言われるけど、NoSQLは幅広いので、どんな設計になっているのか、説明しよう。
BigtableはいわゆるKey/Valueデータベースですが、単純なKey/Valueデータベースではない。いくつか特殊な機能を持っている。まずは、一つのキーは複数の値を持つ機能を持っている。これはRDBMSと同じようにコラムとして表現されるけど、RDBMSと違っていて、テーブルスキーマがなくて、rowデータに含まれているコラムがrowごとに変わってもよい。
rowもキーによって、ソートされているので、rowキーを指定して、スキャンができる。だけど、コラムに入っているデータによって、クエリーやスキャンはできない。RDBMS的に言うとprimary key indexがあるけど、secondary indexがない。
最後にrow間のトランザクションはないけど、一つのrowに含まれているコラムに対して、書き込みの整合性がある。
技術を秘密にする罠
MapReduceやBigtableの技術をホワイトペーパーとして公開したが、コードは公開していなかった。その状況でOSSの実装が出てきたけど、Googleのノウハウが使われていなくて、Googleで実装したMapReduceや、Bigtableほど性能がなかった。GoogleがOSSや、IT産業にノウハウや技術をもっと貢献できるようにもっとOSSやAPIを作ろうという傾向があります。最近公開している Kubernetesや、Tensorflowに実現している。
ただ、Bigtableに関しては、もう遅いので、一番近いHBase APIに互換したAPIを提供することになった。それで、HBaseを使っていた開発者はコードを変えずにBigtableを使えるし、Bigtableにベンダーロックされない。
HBase API
HBaseネィティブAPIは割とよく出来てきて、データの読み書きが簡単にできる (Javaしかないのは私的には悲しいけどw)
こんな感じでConnectionを作って、一つのRowを取得できる。
try {
Connection connection = ConnectionFactory.createConnection();
try {
Table table = connection.getTable(TableName.valueOf(tableName));
// rowIdをもとにGetリクエストを作成して、テーブルにリクエストを実行
Result result = table.get(new Get("rowId".getBytes()));
// 結果を回して、それぞれのコラムと値をstdoutに出力
for (Cell cell : result.listCells()) {
String row = new String(CellUtil.cloneRow(cell));
String family = new String(CellUtil.cloneFamily(cell));
String column = new String(CellUtil.cloneQualifier(cell));
String value = new String(CellUtil.cloneValue(cell));
long timestamp = cell.getTimestamp();
System.out.printf("%-20s column=%s:%s, timestamp=%s, value=%s\n", row, family, column, timestamp, value);
}
} finally {
// 最後にコネクションを閉じる
connection.close();
}
} catch (IOException e) {
e.printStackTrace();
}
Putはこんな感じ
// Putリクエストを作成
Put put = new Put(Bytes.toBytes(rowId));
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value));
// 複数のコラムを一発でputできる
// put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value));
// テーブルにリクエストを実行
table.put(put);
Scanはこういうふうにできます。
// Create a new Scan instance.
Scan scan = new Scan();
// スキャンのフィルターがいくつかあります。
scan.setFilter(new SingleColumnValueFilter(columnFamily, columnName, CompareFilter.CompareOp.EQUAL, "mycolumn"));
ResultScanner resultScanner = table.getScanner(scan);
// スキャンのrowを回す
for (Result result : resultScanner) {
// rowの中のコラムと値を回す
for (Cell cell : result.listCells()) {
// 結果を出力する
String row = new String(CellUtil.cloneRow(cell));
String family = new String(CellUtil.cloneFamily(cell));
String column = new String(CellUtil.cloneQualifier(cell));
String value = new String(CellUtil.cloneValue(cell));
long timestamp = cell.getTimestamp();
System.out.printf("%-20s column=%s:%s, timestamp=%s, value=%s\n", row, family, column, timestamp, value);
}
}
Bigtableのこれから
Cloud Bigtableは現在betaで、GA (一般公開)は来年に向けて頑張っています。Cloud Bigtableの安定性をフォーカスして、GAのあとに新しい機能や改善にフォーカスすることになるでしょう。
Betaの間は誰でも使えるので、ぜひ試してみてください。